
GLM-5 — новая open-source модель от Zhipu AI, в бенчмарках догоняет Claude и GPT. Zhipu уже вышла на IPO — первая публичная AI-компания с открытыми моделями.
Я прогнал GLM-5 через реальную задачу в Kilo Code: от эпика до готового кода, прошедшего моё ревью. В статье показан мой подход разработки через ИИ-агентов, краткий обзор инструментов, полная сессия со скриншотами и выводы. По сравнению с кодингом без ИИ-агентов моя продуктивность выросла примерно в 3 раза.
Кому будет полезно
Программистам, которые хотят делегировать код ИИ-агенту, но не знают как выстроить процесс. Тем, кто выбирает инструмент для AI-кодинга или ищет рабочую open-source модель. Инвесторам, которые оценивают AI-компании. И тем, кто уже работает с ИИ-агентами — советы по настройке и разбор типичных проблем.
Содержание
GLM-5: знакомство с моделью
11 февраля Zhipu AI выпустила GLM-5 — open-source модель, которая в бенчмарках догоняет Claude и GPT. Zhipu называет это переходом "от вайб-кодинга к агентной инженерии": модель заточена под многошаговые задачи и самостоятельную работу агентов.
Технические характеристики
GLM-5 создана для сложных системных задач и долгосрочной работы агентов (long-horizon). По сравнению с GLM-4.5 масштаб вырос с 355B параметров (32B активных) до 744B (40B активных), а объём пре-тренировочных данных — с 23T до 28.5T токенов.
Официальный анонс от Z.ai:
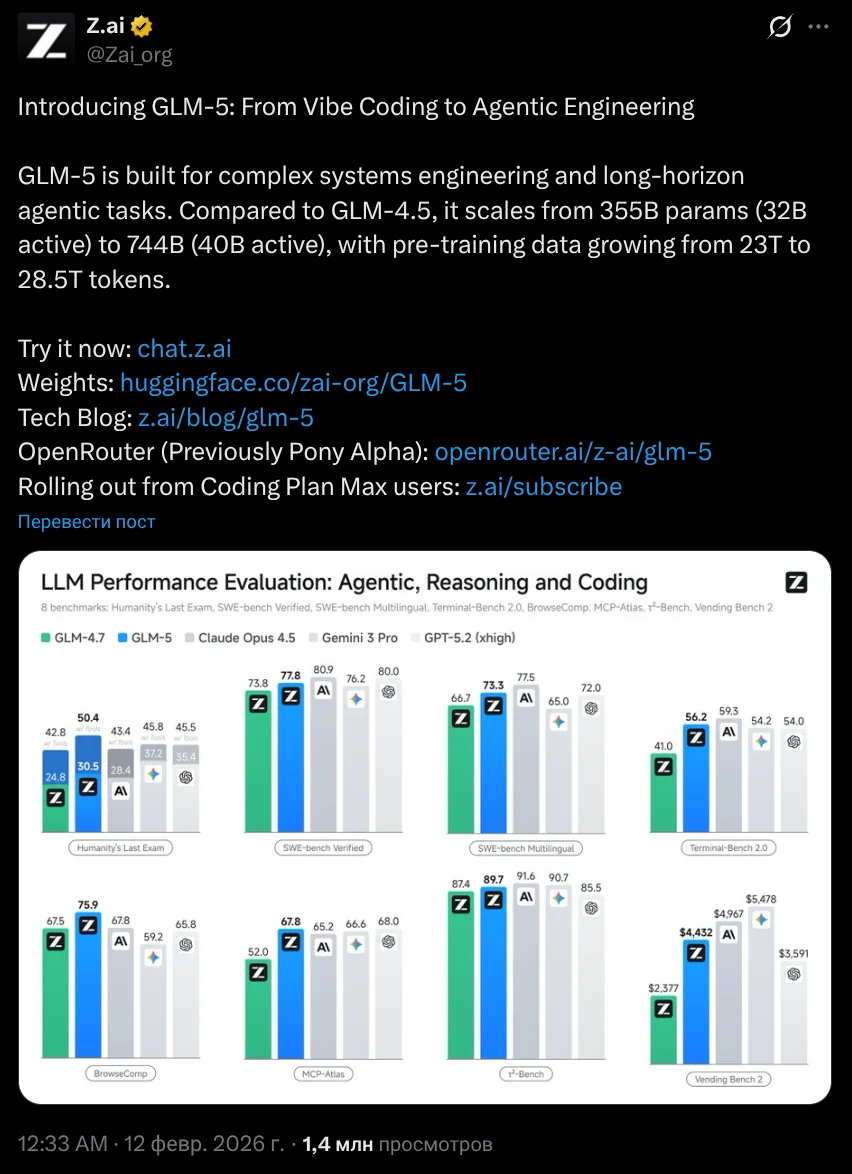
Источник: https://x.com/Zai_org
Результаты в бенчмарках
GLM-5 опережает другие открытые модели (DeepSeek V3, Kimi K2.5, MiniMax) и впервые среди open-source достиг 50+ баллов на Artificial Analysis Intelligence Index. В бенчмарках приближается к Claude Opus 4.6 и GPT-5.2.
Скриншот с Artificial Analysis Intelligence Index:
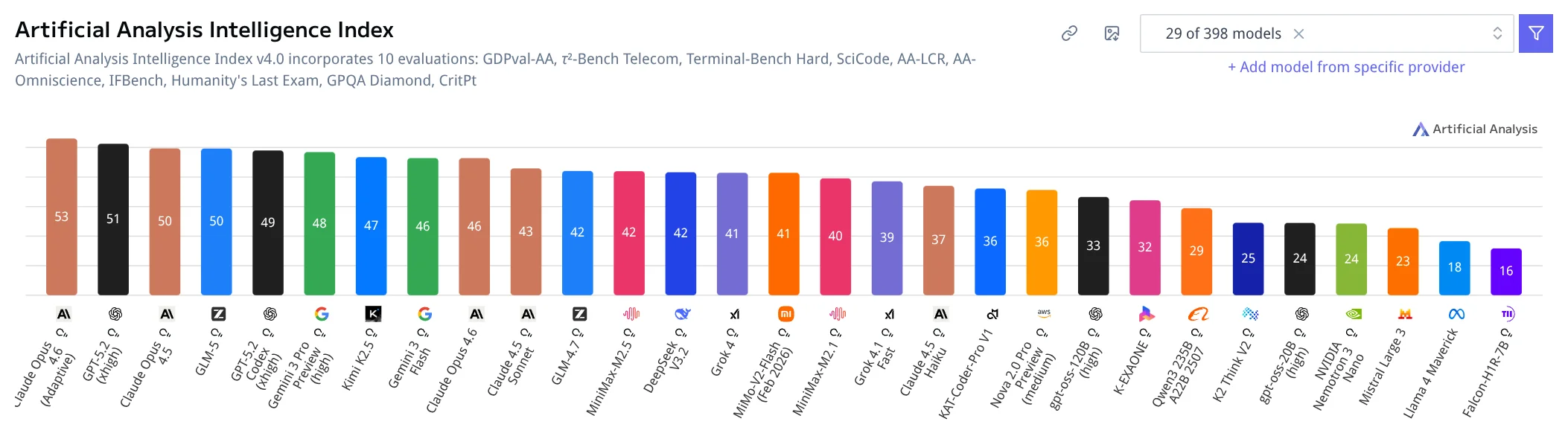
Источник: https://artificialanalysis.ai/
Сильные стороны
Кодинг и агенты. Модель показывает высокие результаты в кодинге, логическом выводе и long-horizon задачах (многошаговые агенты, tool use).
Скриншот с coding-бенчмарков:
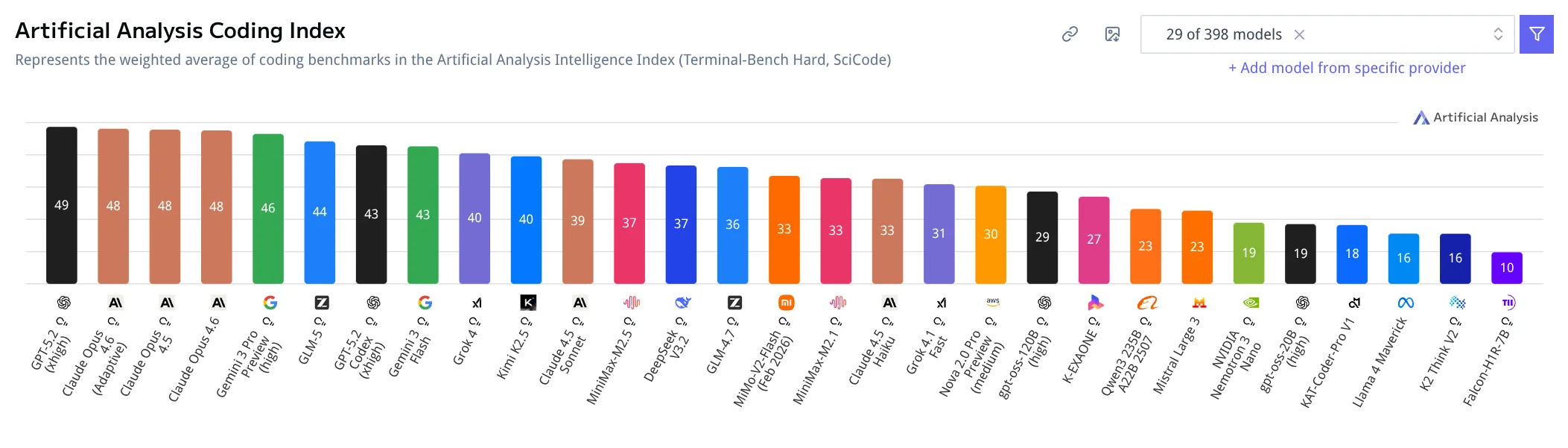
Источник: https://artificialanalysis.ai/
Низкий hallucination rate. Модель реже галлюцинирует и чаще отвечает "не знаю" при неуверенности.
Скриншот с метрикой hallucination rate:
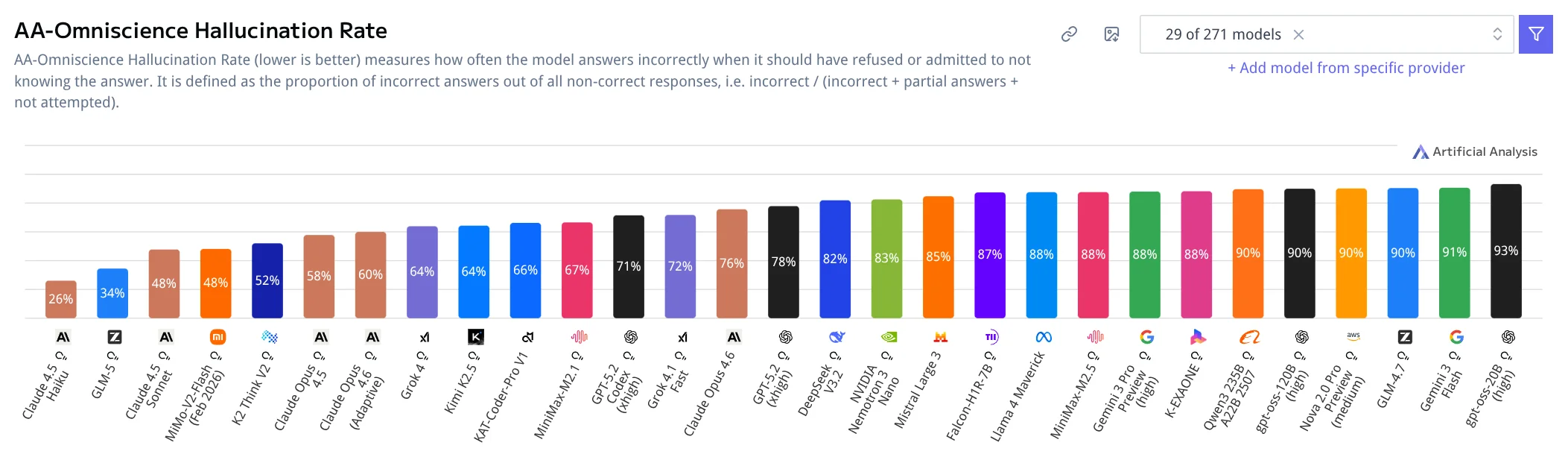
Источник: https://artificialanalysis.ai/
Бизнес-контекст
Zhipu AI вышла на IPO в Гонконге 8 января 2026 года (тикер: HKG:2513). В день релиза GLM-5 акции выросли на 29%, достигнув HKD 402 — исторического максимума. На утро 17 февраля цена составила HKD 508.
Скриншот котировок:
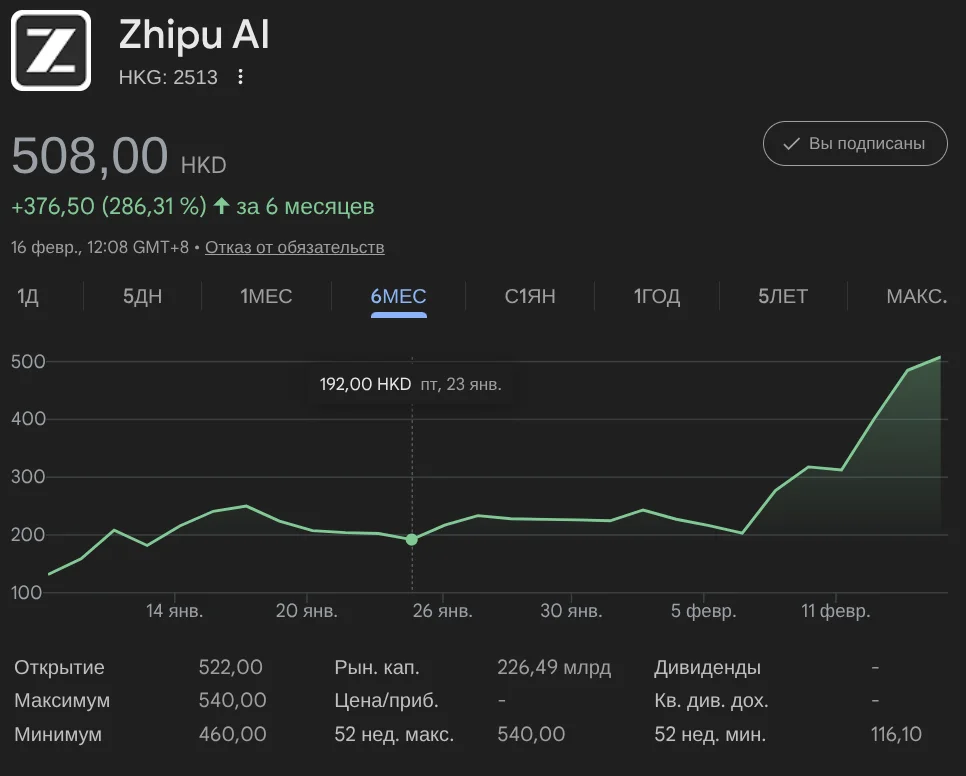
Источник: Google Finance
Это контрастирует с OpenAI и Anthropic: обе компании держат модели закрытыми и остаются частными. OpenAI планирует IPO в конце 2026 года, Anthropic следует за ними. Zhipu — первая из крупных AI-компаний, открывшая и веса модели, и финансовую структуру для рынка.
Релиз GLM-5 поднял сектор китайских AI-акций: MiniMax (HKG:0100) выросла на 15%, полупроводниковые компании — на 3–14%. Zhipu и MiniMax — первые из "AI Tigers" Китая, вышедшие на публичные рынки.
На фоне роста спроса Zhipu подняла цены на подписку GLM coding plan на 30%.
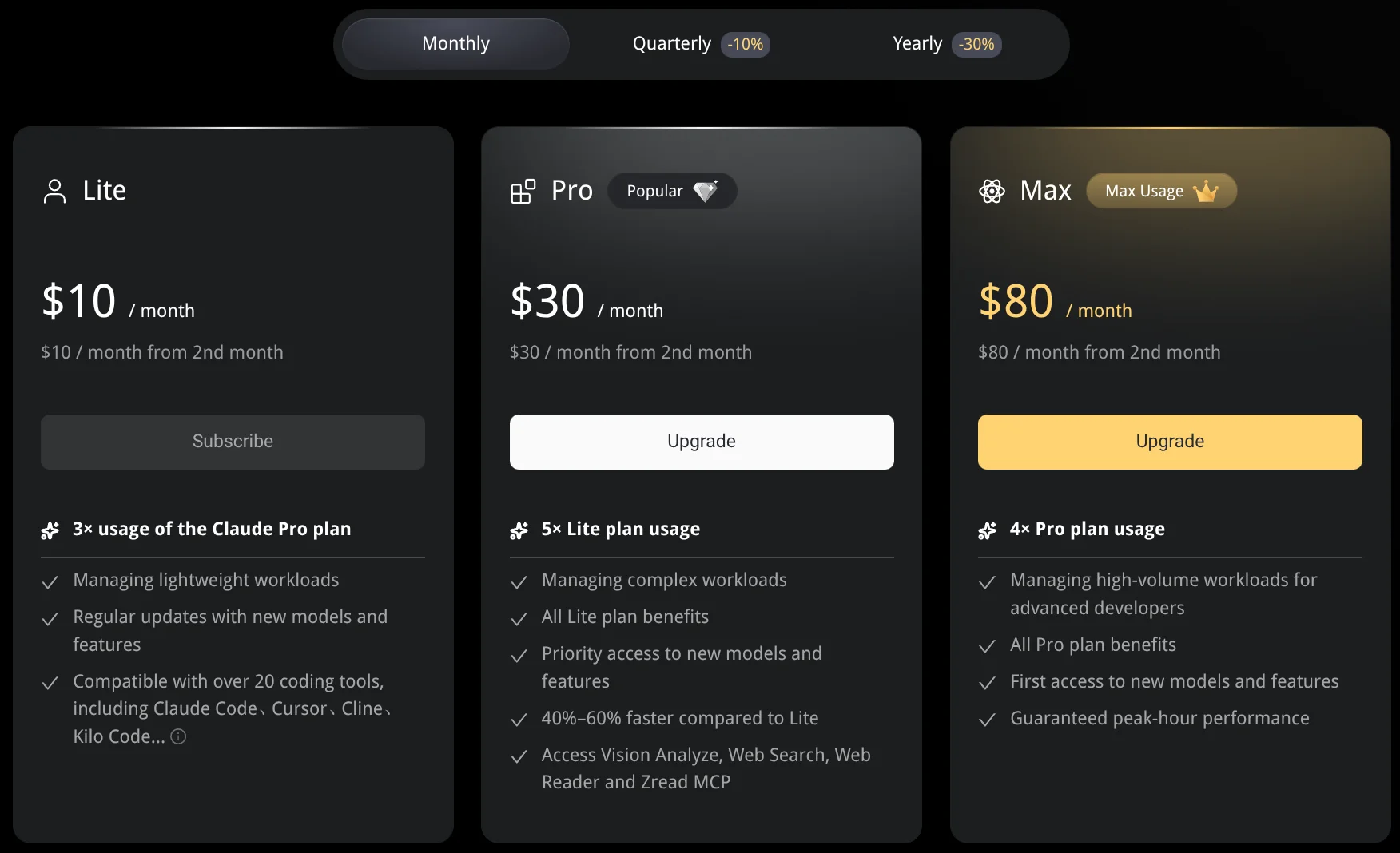
Источник: https://z.ai/subscribe
Zhipu открыта и как продукт (веса модели), и как компания (IPO делает финансовую отчётность публичной). Выход на биржу даёт ресурсы для масштабирования, инвесторы верят в компанию — это подтверждается ростом капитализации.
Подход к GLM-5
Я решил проверить GLM-5 в кодинге и заодно показать, как работаю с ИИ-агентами и закрепить текущий опыт разработки.
Ранее я пользовался Codex Cloud, а после ужесточения лимитов стал искать альтернативы. Три месяца я перебирал инструменты для AI-кодинга. Сейчас, более-менее, определился с основным окружением, но продолжаю пробовать новое — например, эту статью пишу в Obsidian с помощью OpenCode на GLM-5.
На сегодня мои основные инструменты для создания кода: Codex CLI с gpt-5.3-codex high и Kilo Code с GLM-4.7 (переключаюсь на GLM-5). По-моим субъективным наблюдениям Codex учитывает больше деталей, после него меньше замечаний. Но GLM не уступает — обе модели справляются. Если делают что-то не так, указываю на недочёт — правят.
Уровень доверия к коду от ИИ еще низкий, 100% кода проверяю. Поэтому делегирую так: прошу агента исследовать задачу и предложить решение, даю обратную связь, итерациями допиливаю постановку. Пример: Возьми на себя роль аналитика. Мне нужна status page для проекта, сделай эпик для этой задачи.
Не использую Skills или MCP — всё необходимое расписано в AGENTS.md со ссылками на файлы с детальными инструкциями. Обе модели в разных экосистемах используют AGENTS.md, необходимые инструкции подгружают в свой контекст сами. AGENTS.md и правила у меня "живые": если есть повторяющиеся отклонения или нарушения правил — вношу корректировки через ИИ-агента.
Я опубликовал AGENTS.md и все инструкции для агентов в открытом репозитории: https://github.com/prikotov/task-agents-playbook.
Обзор инструментов для AI-кодинга
За три месяца поиска я попробовал несколько инструментов и собрал обзор по основным игрокам на рынке AI-кодинга.
| Инструмент | Тип | Звезд | Версия | Релизов | Первый коммит | Посл. релиз | Возраст | Посл. коммит | Контриб.: | Открыто Issues | Закрыто Issues |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenCode | cli | 105.7K | 1.2.6 | 716 | 25-03-21 | 26-02-17 | 11 мес. | 26-02-17 | 749 | 3876 | 4604 |
| Gemini CLI | cli | 94.7K | 0.28.2 | 355 | 25-04-17 | 26-02-14 | 10 мес. | 26-02-17 | 509 | 1802 | 8064 |
| Claude Code | cli | 67.2K | 2.1.44 | 324 | 25-02-22 | 26-02-17 | 11 мес. | 26-02-17 | 50 | 5975 | 19210 |
| Codex CLI | cli, vscode | 60.7K | 0.101.0 | 509 | 25-04-16 | 26-02-13 | 10 мес. | 26-02-17 | 366 | 1134 | 4289 |
| Cline | vscode | 58.1K | 3.63.0 | 231 | 24-07-06 | 26-02-17 | 1 г. 7 мес. | 26-02-17 | 296 | 470 | 2837 |
| Aider | cli | 40.7K | 0.86.0 | 93 | 23-04-04 | 25-08-09 | 2 г. 10 мес. | 26-02-16 | 168 | 1150 | 2800 |
| Continue | cli, vscode, jetbrains | 31.4K | 1.2.15 | 798 | 23-05-24 | 26-02-05 | 2 г. 9 мес. | 26-02-17 | 451 | 779 | 4388 |
| RooCode | vscode | 22.2K | 3.47.3 | 248 | 24-10-31 | 26-02-06 | 1 г. 3 мес. | 26-02-17 | 293 | 267 | 2952 |
| Qwen Code | cli | 18.5K | 0.10.2 | 281 | 25-04-17 | 26-02-17 | 10 мес. | 26-02-16 | 335 | 436 | 584 |
| Kilo Code | vscode, jetbrains | 15.5K | 5.7.0 | 298 | 25-03-10 | 26-02-12 | 11 мес. | 26-02-17 | 499 | 768 | 991 |
| Antigravity | vscode fork | 1.16.5 | 25-11-18 | 26-02-03 | 3 мес. |
Данные актуальны на 17 февраля 2026. Из этого списка для себя я выбрал Codex CLI, который использую в паре с PHPStorm и Kilo Code, который использую в VS Code, и пробую OpenCode иногда.
И это не полный список. Есть ещё Windsurf, Trae, Cursor, Zed с AI-фичами и десятки других. Отдельно отмечу KodaCode — отечественную систему для AI-кодинга (и она не единтсвенная). Инструменты бывают разные: расширения для IDE (VS Code, JetBrains, Zed), форки редакторов (как Antigravity), отдельные десктопные приложения (OpenAI выпустили для MacOS Codex App), CLI-агенты. Рынок растёт, каждый месяц появляются новые решения, а существующие выпускают по несколько релизов в день.
Мой проект TasK: размер и стек проекта
Привожу размер и стек проекта TasK, чтобы было понимание размера кодовой базы и технологий, с которыми приходится работать ИИ-агенту.
Стек:
- Бэкенд: Symfony 7.3, PHP 8.4, DDD
- Фронтенд: Symfony UX (Turbo, Stimulus)
- Инфраструктура: Docker/Podman, PostgreSQL+PGVector, Rabbit, Memcached, S3
- Тесты: unit, integration, e2e
- Инструменты: PHPUnit, PHPMD, Deptrac, Psalm, PHP_CodeSniffer
Размер проекта (scc): ~300K строк кода, 5600+ файлов.
| Language | Files | Lines | Blanks | Comments | Code | Complexity |
|---|---|---|---|---|---|---|
| PHP | 4654 | 275382 | 43532 | 16948 | 214902 | 6128 |
| Markdown | 431 | 46055 | 9963 | 0 | 36092 | 0 |
| Twig Template | 216 | 15559 | 1136 | 0 | 14423 | 601 |
| YAML | 175 | 9239 | 457 | 250 | 8532 | 0 |
| Plain Text | 33 | 9791 | 0 | 0 | 9791 | 0 |
| JavaScript | 32 | 3200 | 479 | 196 | 2525 | 290 |
| Shell | 25 | 1856 | 277 | 161 | 1418 | 222 |
| BASH | 18 | 213 | 23 | 24 | 166 | 53 |
| JSON | 14 | 9400 | 0 | 0 | 9400 | 0 |
| Other | 12 | 1334 | 165 | 81 | 1088 | 54 |
| Total | 5630 | 372230 | 56072 | 17675 | 298483 | 7348 |
Процесс работы
За 9 месяцев кодинга с ИИ-агентами я пришёл к подходу, который называю Task-driven development — разработка, управляемая задачами как спецификациями.
В этом подходе единица истины — не "общее описание требований", а конкретная задача (или эпик), оформленная по строгому шаблону. Задача выступает спецификацией для исполнения: задаёт цель, границы (scope / out of scope), критерии приёмки, обязательные проверки. При необходимости — требования к тестам (юнит, интеграционные, e2e). Реализация считается готовой только после подтверждения соответствия задаче: прохождения проверок, выполнения тестов и финального ревью. Иначе задача уточняется и цикл повторяется.
Чем отличается от spec-driven development. Spec-driven строится вокруг отдельного артефакта спецификации (контракт API, сценарии поведения, формальная модель), относительно которого пишется реализация. В task-driven спецификация "упакована" прямо в задачу: задача = спецификация. Постановка задач становится центральным элементом процесса, а разработка — процессом доказательства, что код удовлетворяет формулировкам задачи.
Всё строится на AGENTS.md — файле с инструкциями и правилами проекта для ИИ-агента. Процесс, шаблоны и правила переходов описаны там — так агент работает предсказуемо, результат повторяется.
Процессы не окончательные — я постоянно их улучшаю. Конечная цель улучшений - повысить качество решений агента и его автономность. Чем больше доверяю агенту, тем меньше моего участия в разработке.
Я уже не пишу код руками — только мелкие правки и md-документы. Но моё участие всё равно велико: не могу на 100% доверять моделям, приходится проверять. Бывает агент нарушает правила проекта, изоляцию слоёв, именование namespace и классов, пишет лишние тесты.
Постановка задачи
- Запрос. Делаю запрос к ИИ-агенту. Пример:
Возьми на себя роль аналитика. Мне нужна status page для проекта, сделай эпик для этой задачи. - Генерация. Агент подгружает роль, правила постановки задач, шаблоны — и генерирует текст задачи.
- Self review. Прошу агента проверить себя. Если нужно проработать определенное направление (архитектура, devops, фронт, бэк, тесты), прошу взять соответствующую роль.
- Доработка. Если есть замечания после self review — прошу исправить и возвращаемся к шагу 2.
- Создание PR. Если всё хорошо — прошу агента создать PR.
- Финальное ревью. Сам проверяю результат: постановку задачи, прохожу с агентом итерации "замечание — правка".
- Закрытие. Мержу PR, сообщаю агенту. Он удаляет ветку, переключается на master, выбирает следующую задачу и предлагает приступить.
Реализация задачи
Процесс похож на постановку задачи, но агент проводит больше проверок самостоятельно — прежде чем показать мне код.
- Запрос. Пример:
Ты [Бэкендер](docs/agents/roles/team/backend_developer.md). Возьми в работу задачу из todo/EPIC-status-page.todo.md - Реализация. Агент выполняет требования задачи и сам запускает проверки: тесты (PHPUnit), статический анализ (PHPMD, Deptrac, Psalm), валидацию стиля (PHP_CodeSniffer), сборку (Composer). Так создаётся цикл самовалидации — агент отдаёт код уже достаточно чистым.
- Self review. Прошу агента проверить решение. Можно попросить взять роль (архитектора, devops, фронт-разработчика, бэк-разработчика, тестировщика) и прогнать проверки последовательно для каждой роли.
- Доработка. Если есть замечания на этапе self review — прошу исправить и возвращаемся к шагу 2.
- Создание PR. Если всё хорошо — прошу агента создать PR.
- Финальное ревью. Проверяю код сам, прохожу с агентом итерации "замечание — правка".
- Закрытие. Мержу PR, сообщаю агенту. Он удаляет ветку, переключается на master, выбирает следующую задачу.
- Накопление задач. Так накапливается пул задач к релизу.
- Подготовка релиза. Прошу агента запустить e2e-тесты и подготовить релиз: агент назначает тег, создает changelog и публикует на GitHub.
- Релиз. Я сам выкладываю в прод: прописываю конфигурации, ставлю зависимости, запускаю миграции, перезапуск супервизора. Затем делаю post-проверки.
📸 Пример работы в Kilo Code с GLM-5
Теперь покажу полную сессию взаимодействия с GLM-5 в Kilo Code — чтобы увидеть процесс изнутри и оценить качество ответов модели и интерфейс Kilo Code.
Постановка и планирование эпика
Запрос к агенту: Возьми на себя роль аналитика. Мне нужна status page для проекта, сделай эпик для этой задачи.

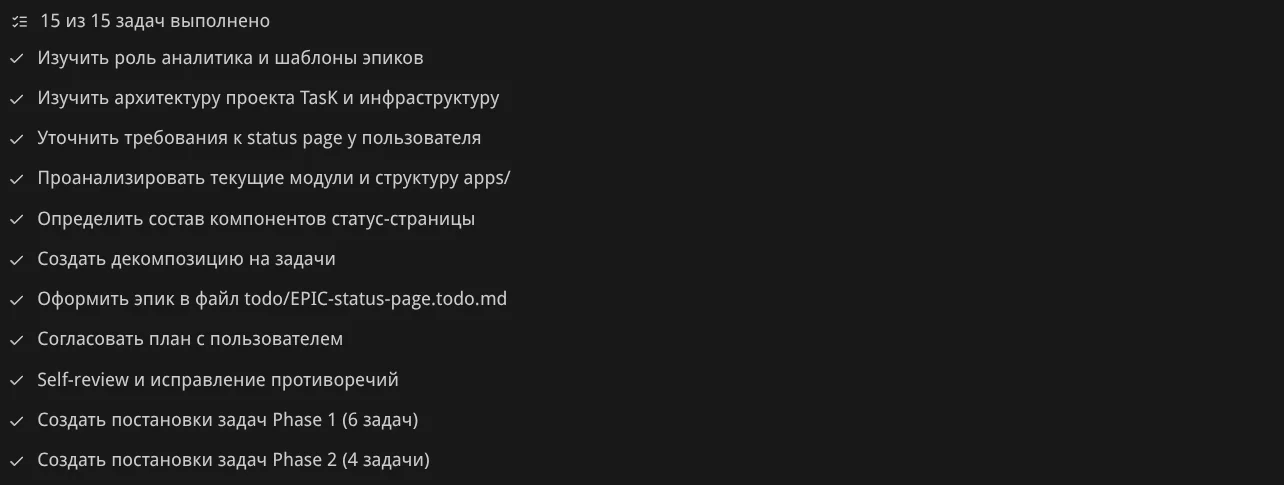
Планирование работы. Агент создал план из 15 пунктов: изучить роль аналитика, архитектуру проекта, уточнить требования, проанализировать модули, определить компоненты, создать декомпозицию, оформить эпик, согласовать план, сделать self-review, создать задачи Phase 1 и Phase 2. По мере выполнения он отмечает пункты галочками:
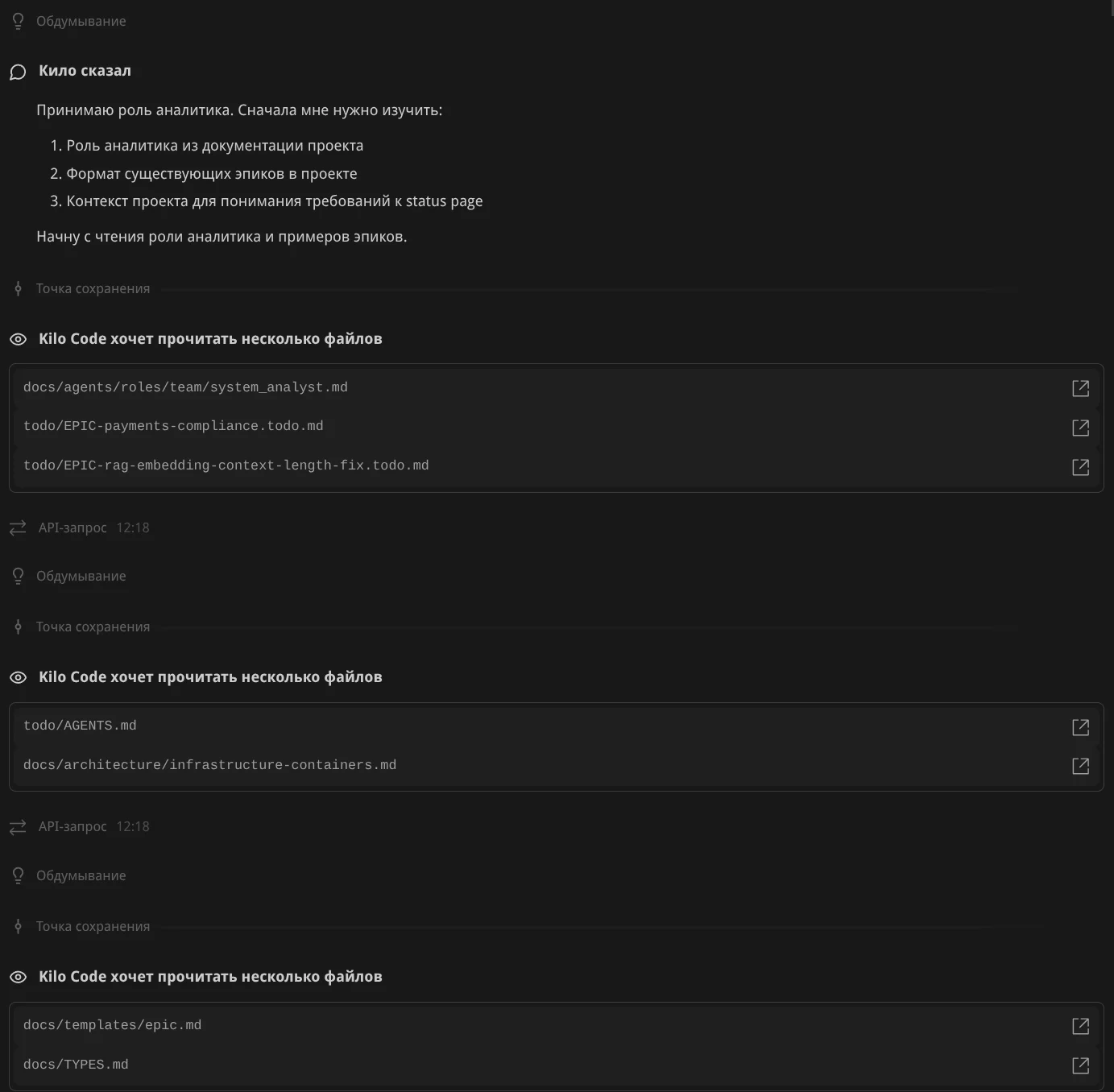
Погружение в контекст. Агент рассуждает: "Принимаю роль аналитика. Сначала мне нужно изучить: роль аналитика из документации, формат существующих эпиков, контекст проекта". Подтягивает файлы: роль системного аналитика, примеры эпиков, AGENTS.md, архитектуру контейнеров, шаблон эпика:
Семантический поиск. Kilo Code ищет не только grep-ом, но и по смыслу — нашёл 9 результатов по "health check endpoint status monitoring service". Затем искал в конфигах и изучил docs/product:
Изучение продукта. Агент нашёл и изучил vision.md и mvp.md — погружается в направление проекта:
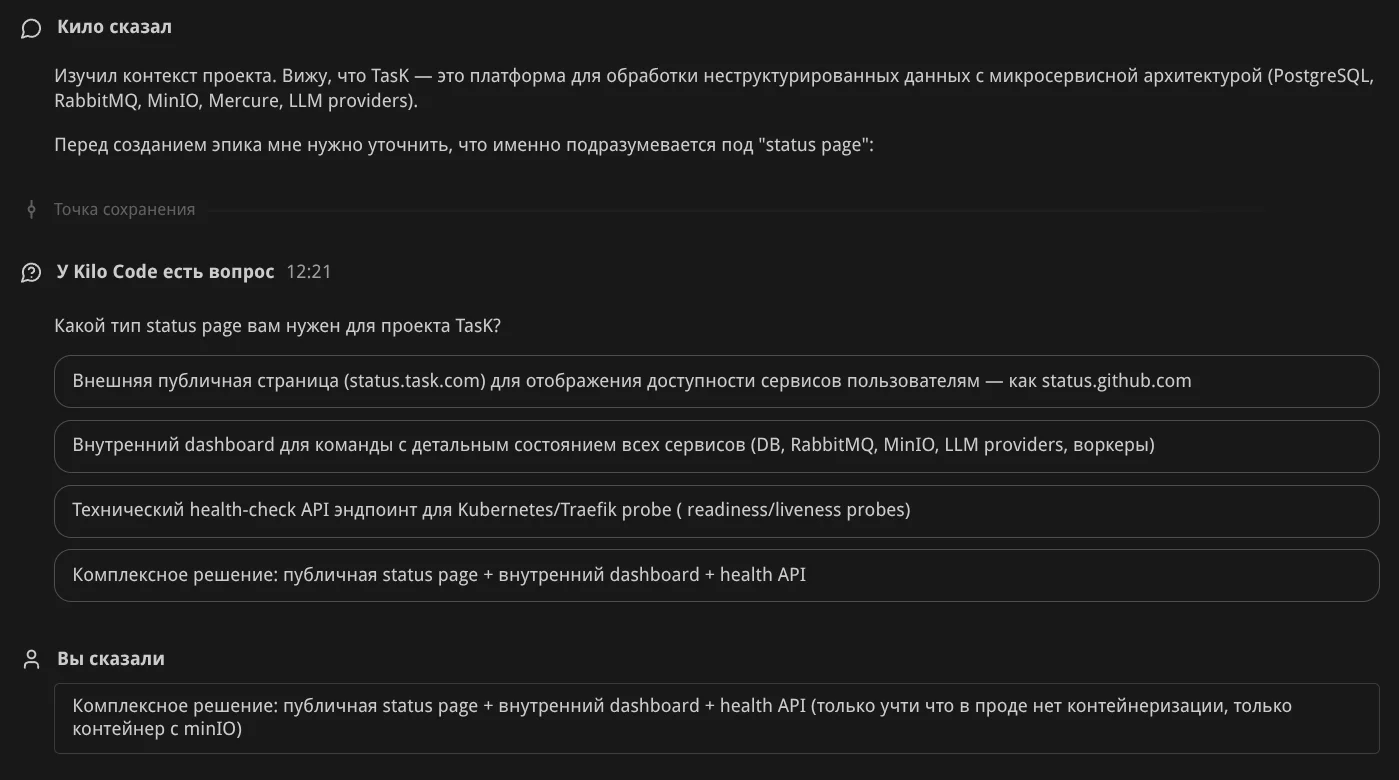
Уточняющие вопросы. Агент спрашивает: "Какой тип status page нужен?" и предлагает варианты — публичная страница как status.github.com, внутренний dashboard, health-check API, или комплексное решение:
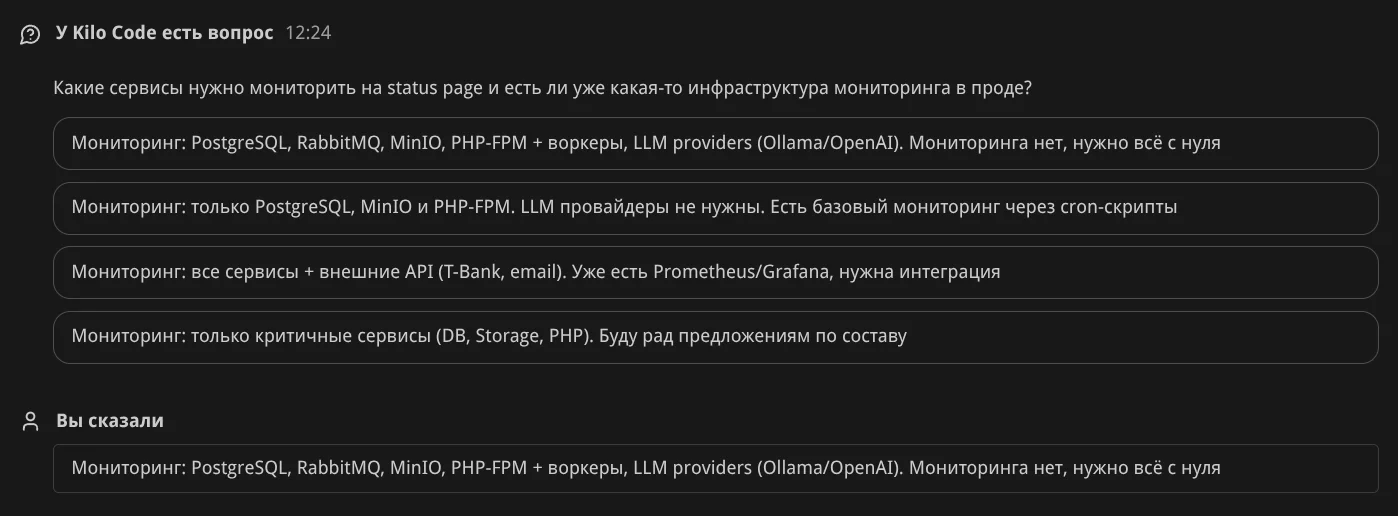
Результат и резюме. Агент отдаёт результат и предлагает доработки:

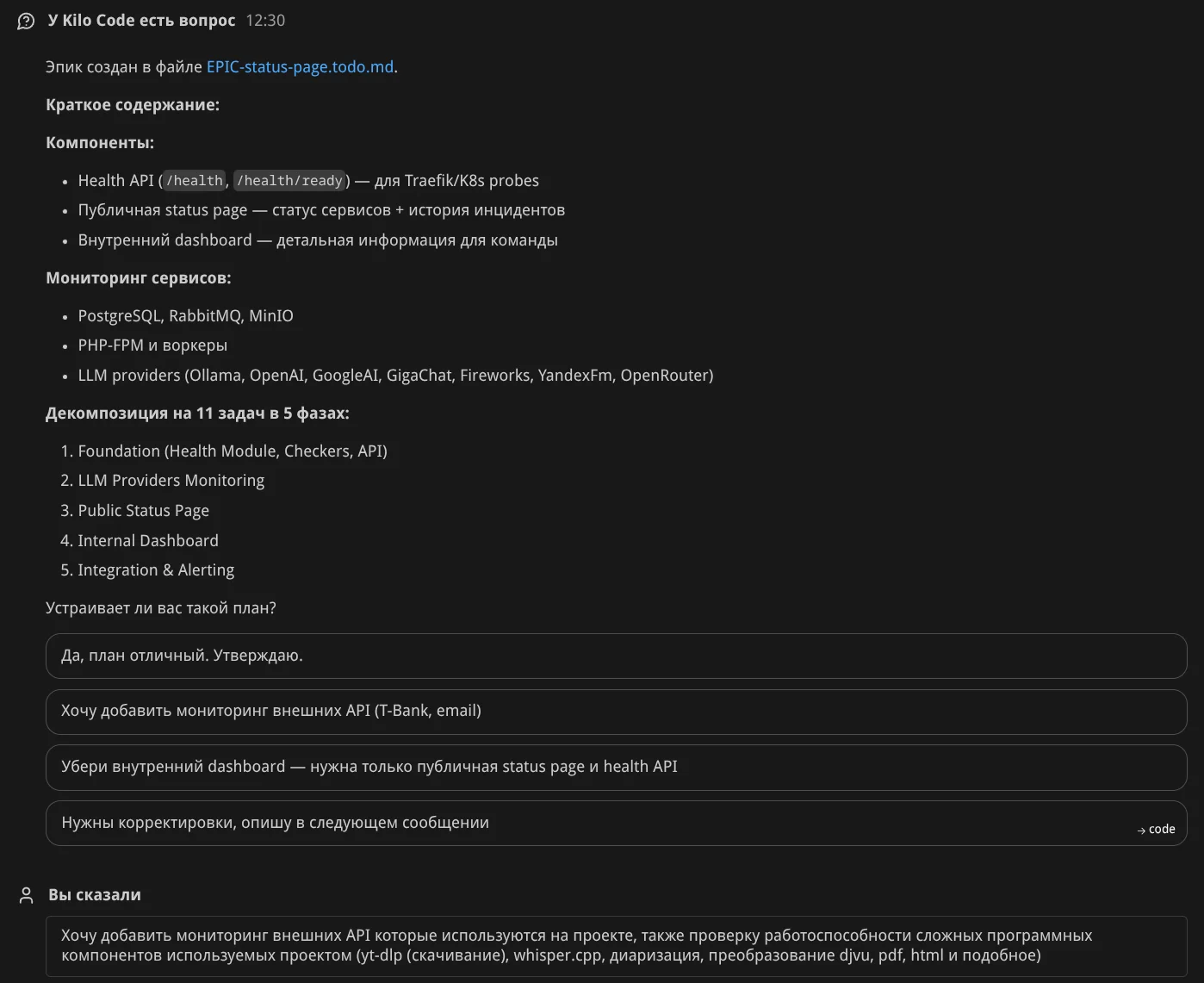
Доработка. Я увидел упущенные моменты и попросил доработать план. Агент исследует проект:
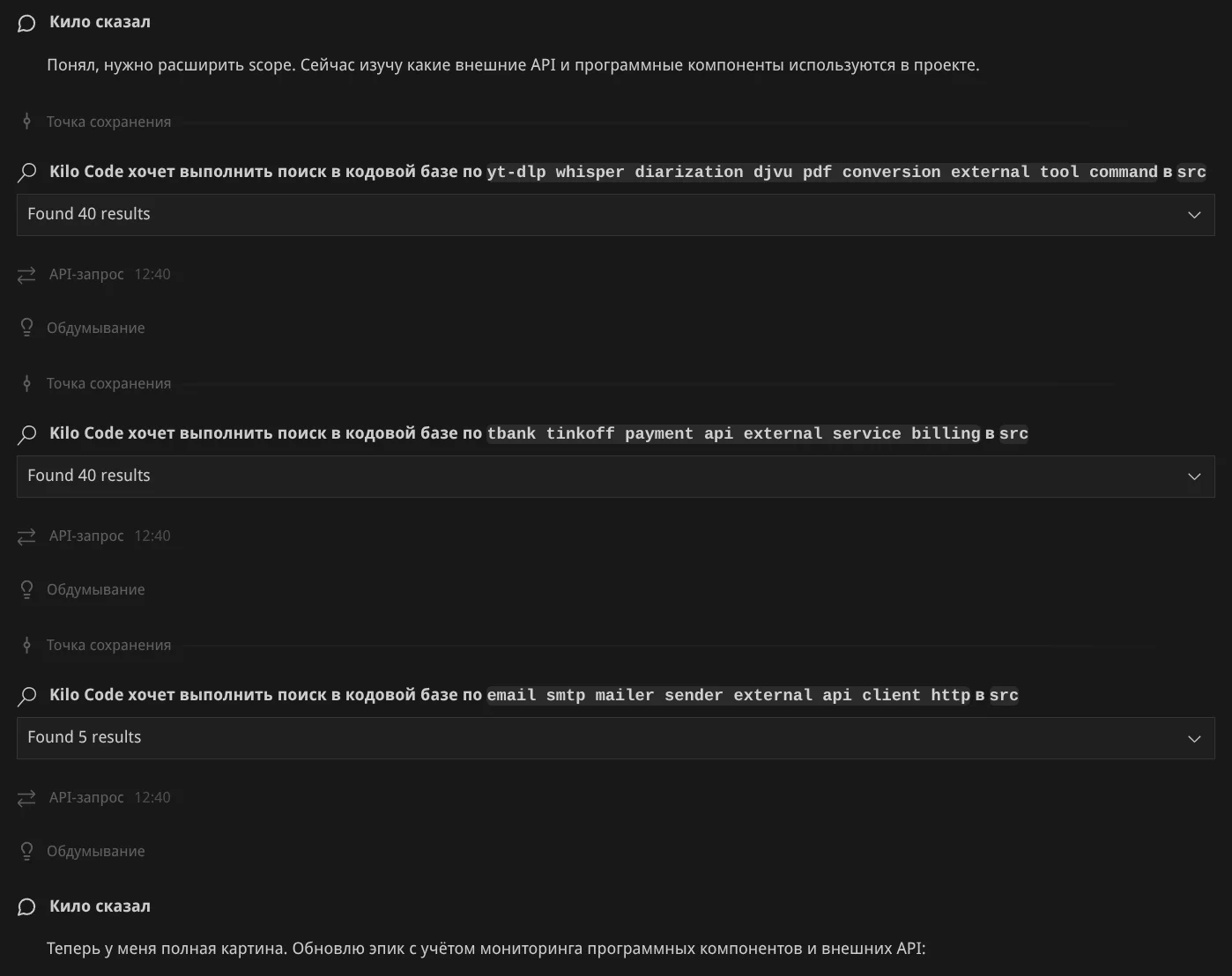
Ещё одна итерация уточнения требований:
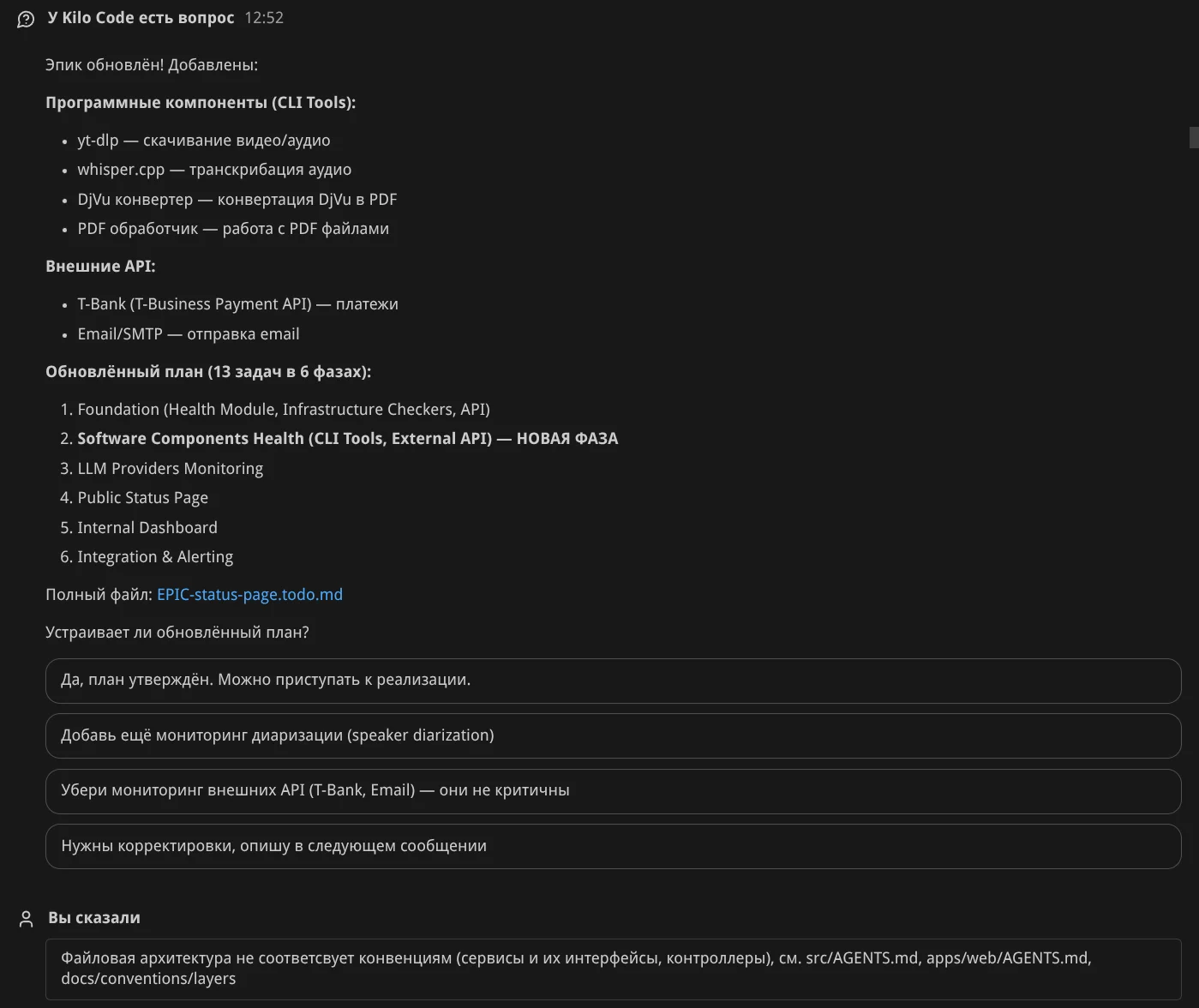
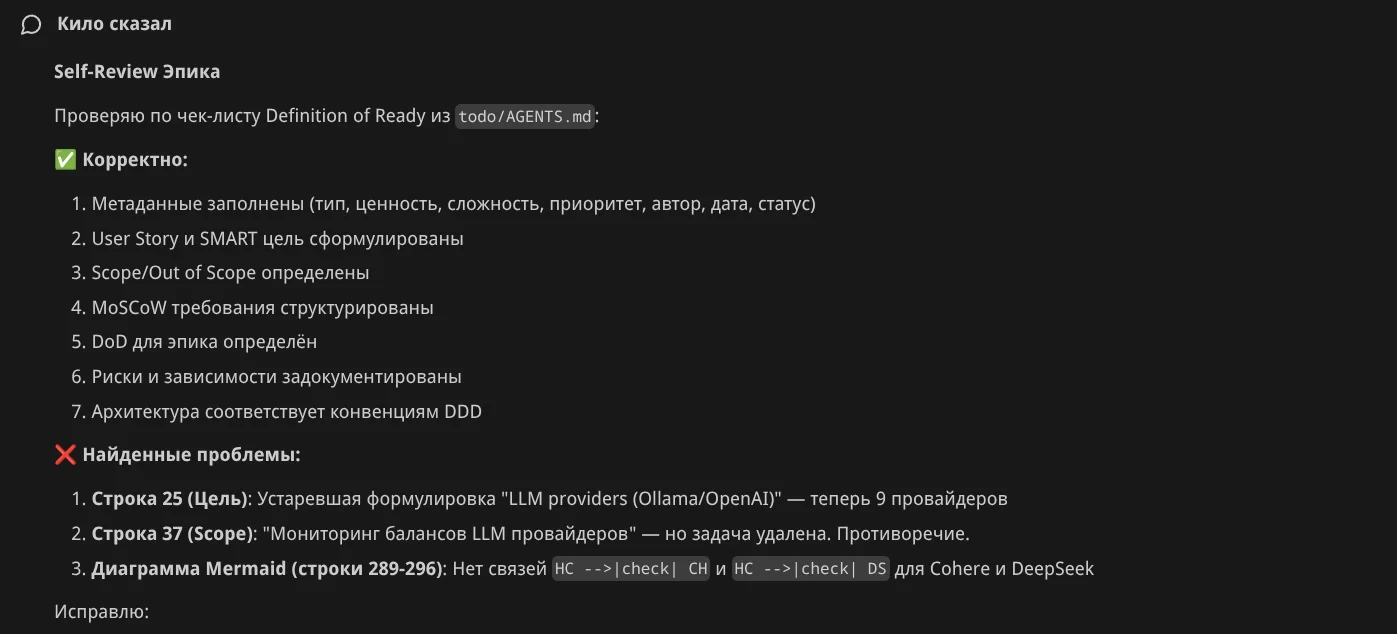
Self review. Попросил Агента проверить себя — он нашёл что поправить:
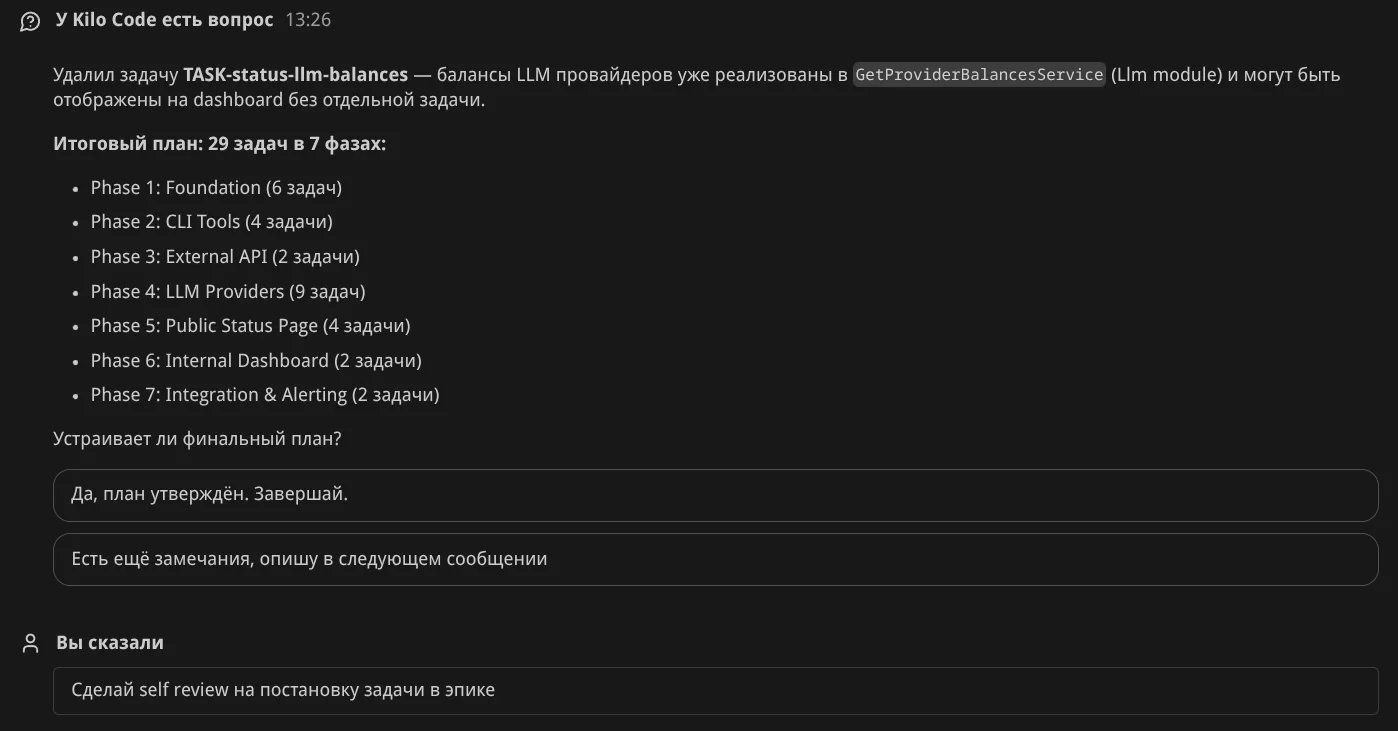
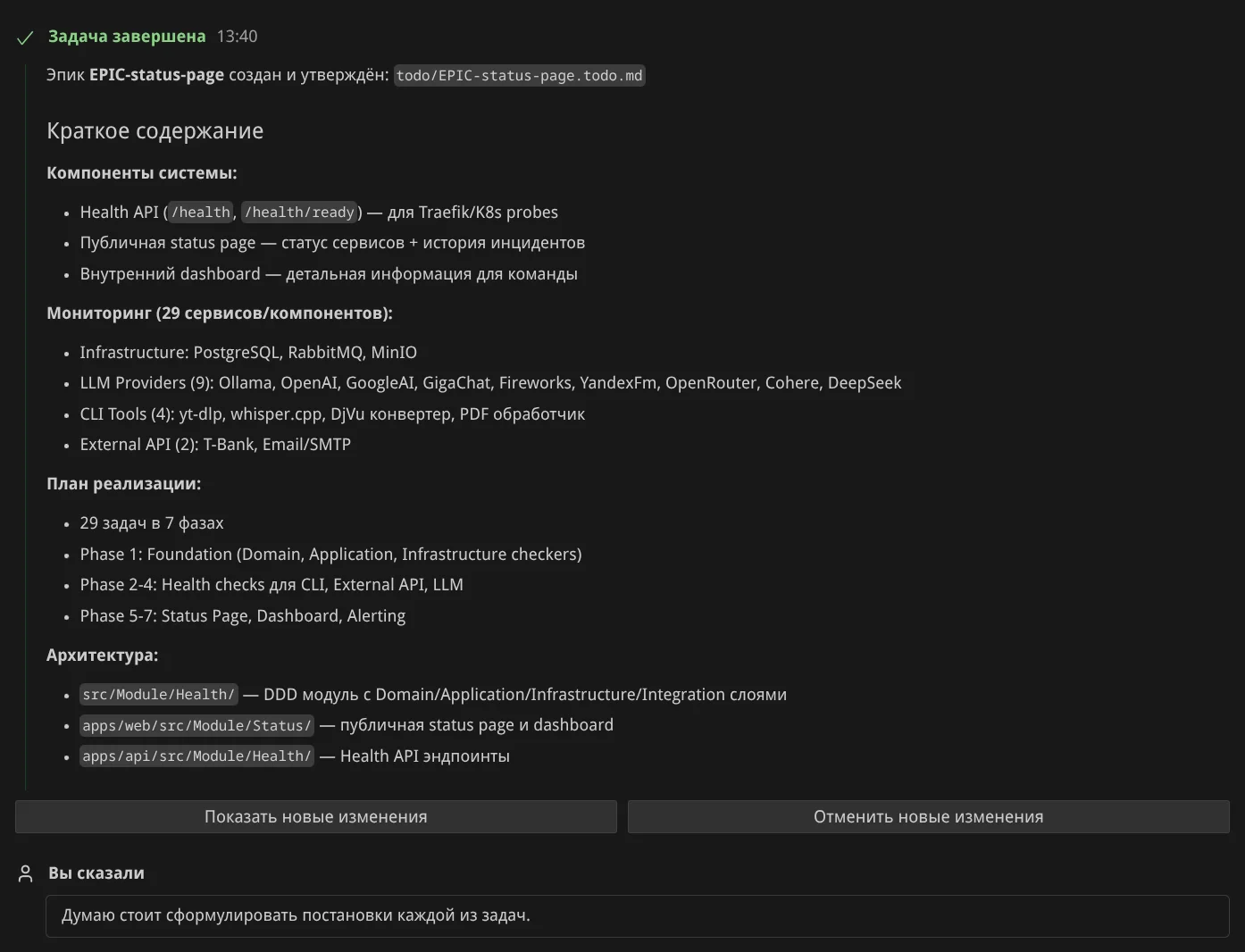
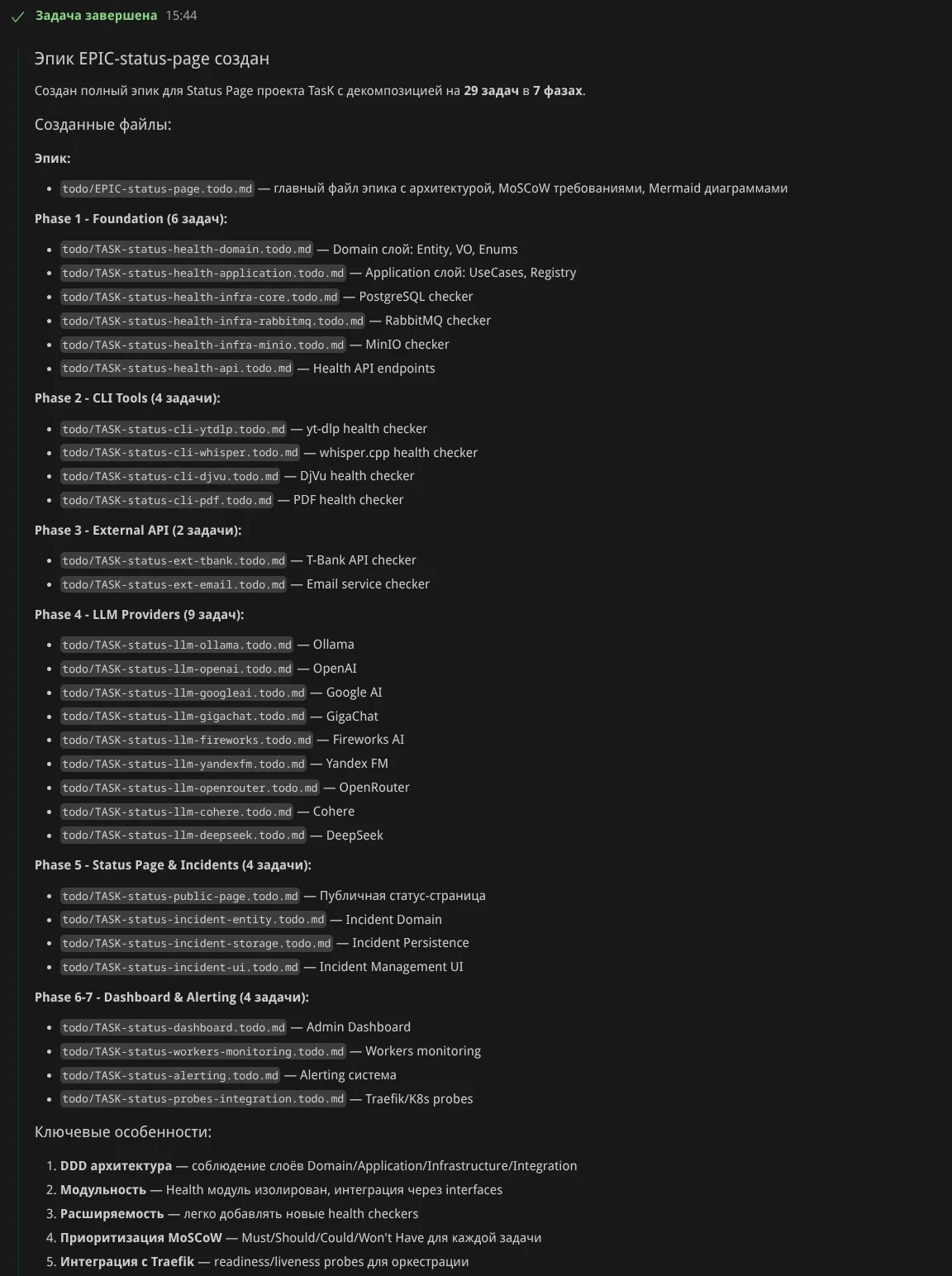
Декомпозиция. Теперь прошу агента расписать задачи эпика — получил 28 задач в 7 фазах (этапах):
Я попросил убрать лишние задачи и снова отправил на self review:
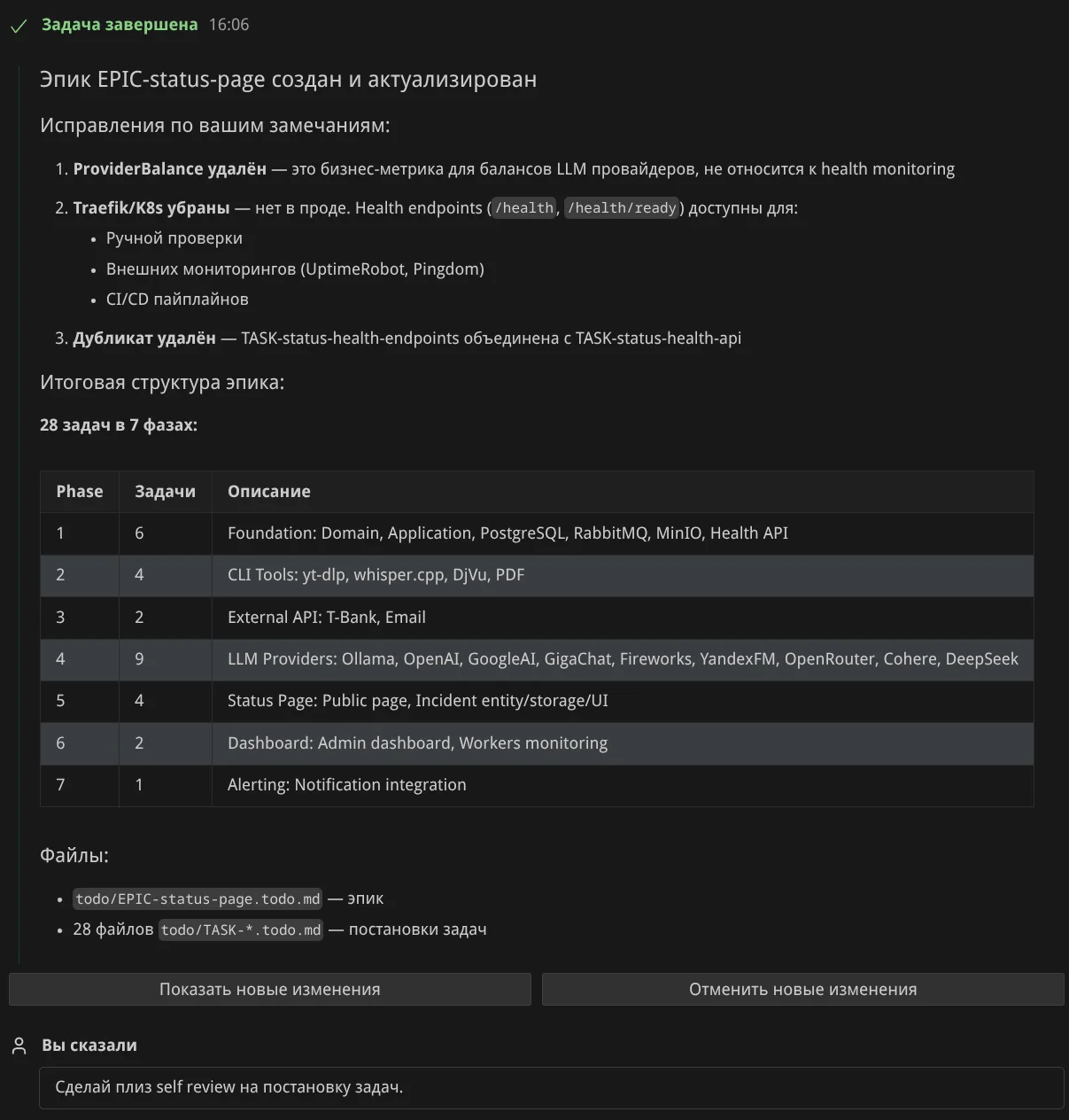
Ещё моя просьба доработать постановку задач:
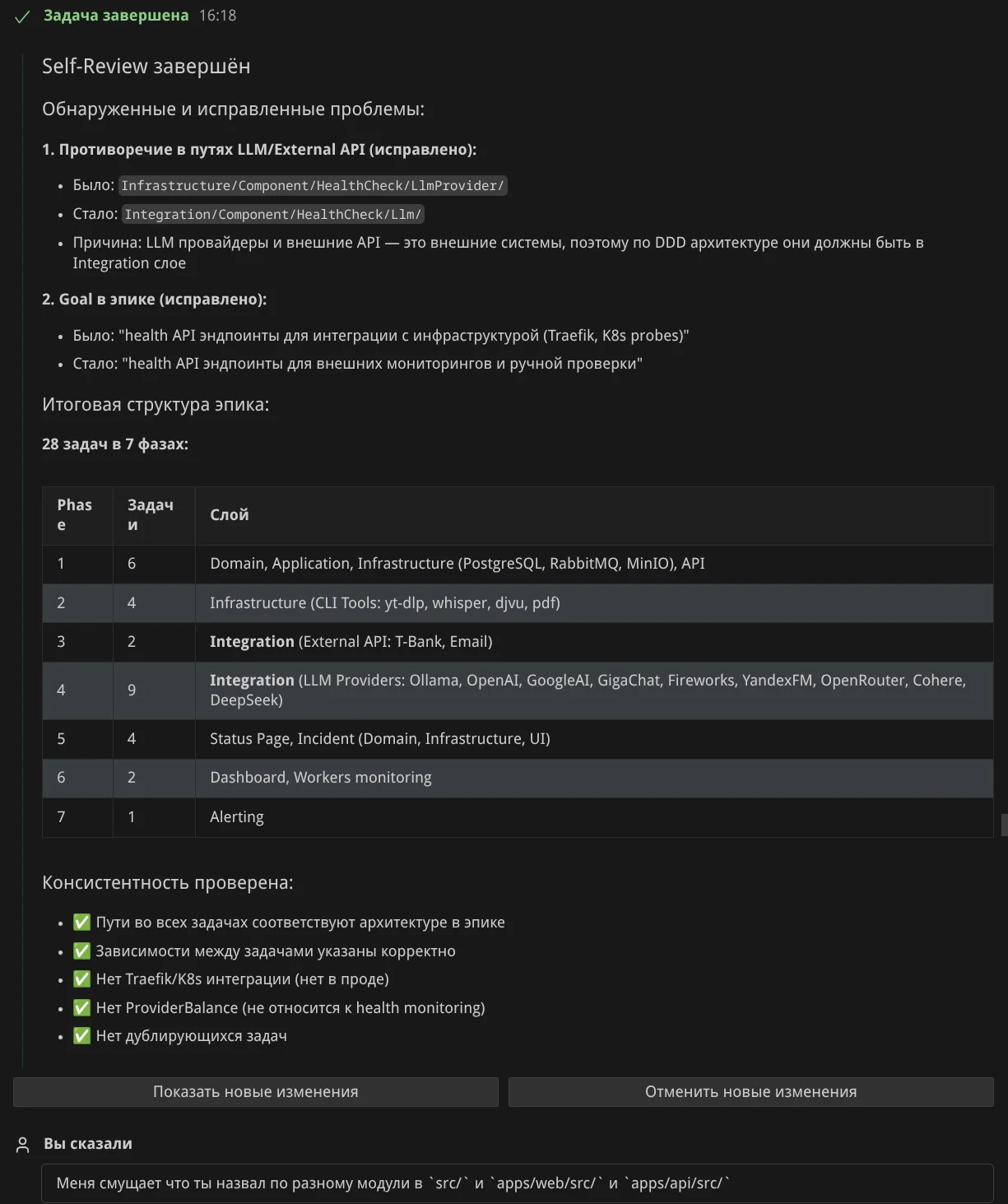
Создание PR. Когда результат устроил — я попросил создать PR:
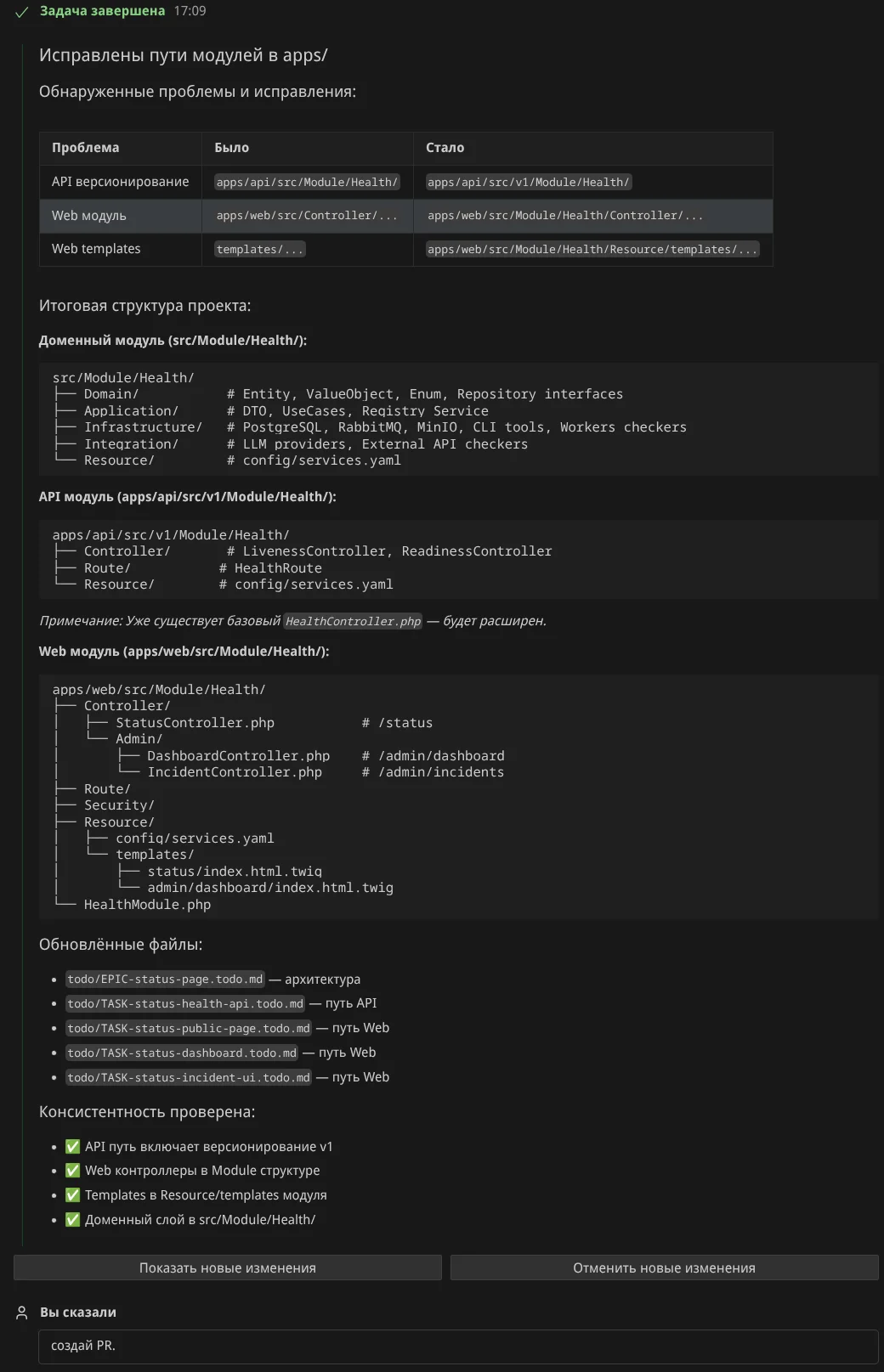
Я проверил PR в GitHub, там же смержил и сообщил агенту об этом:
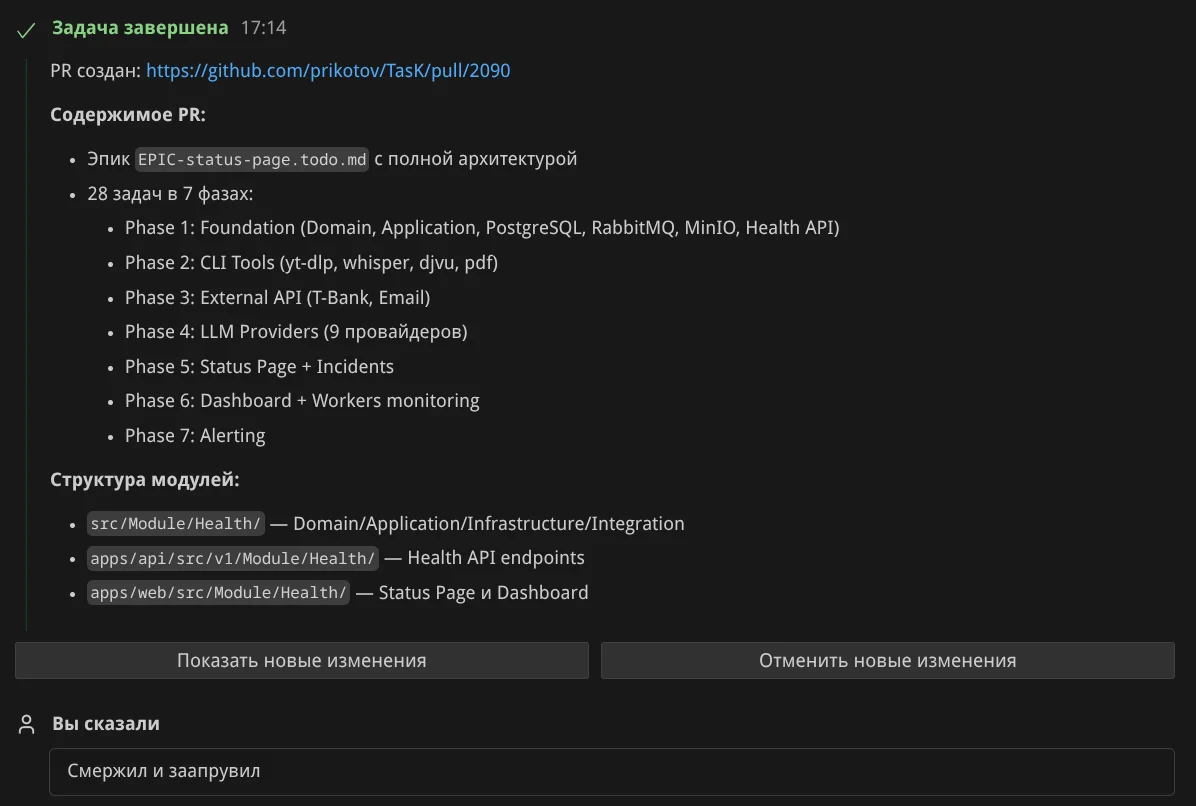
Завершение. Агент понял что работа завершена, удалил ветку, переключился на master, запустил composer install, проверил что всё чисто:
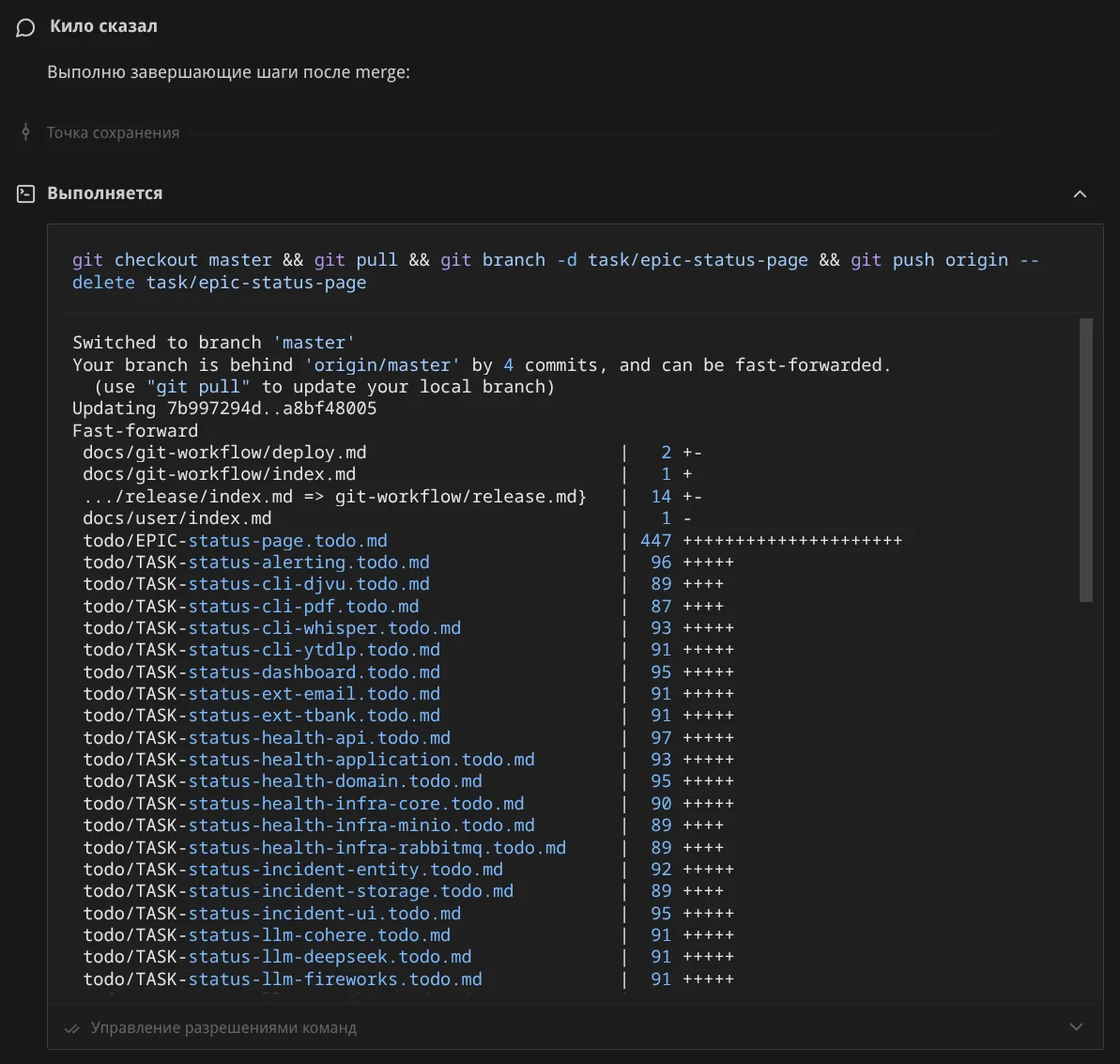
И предложил приступить к задачам из эпика:
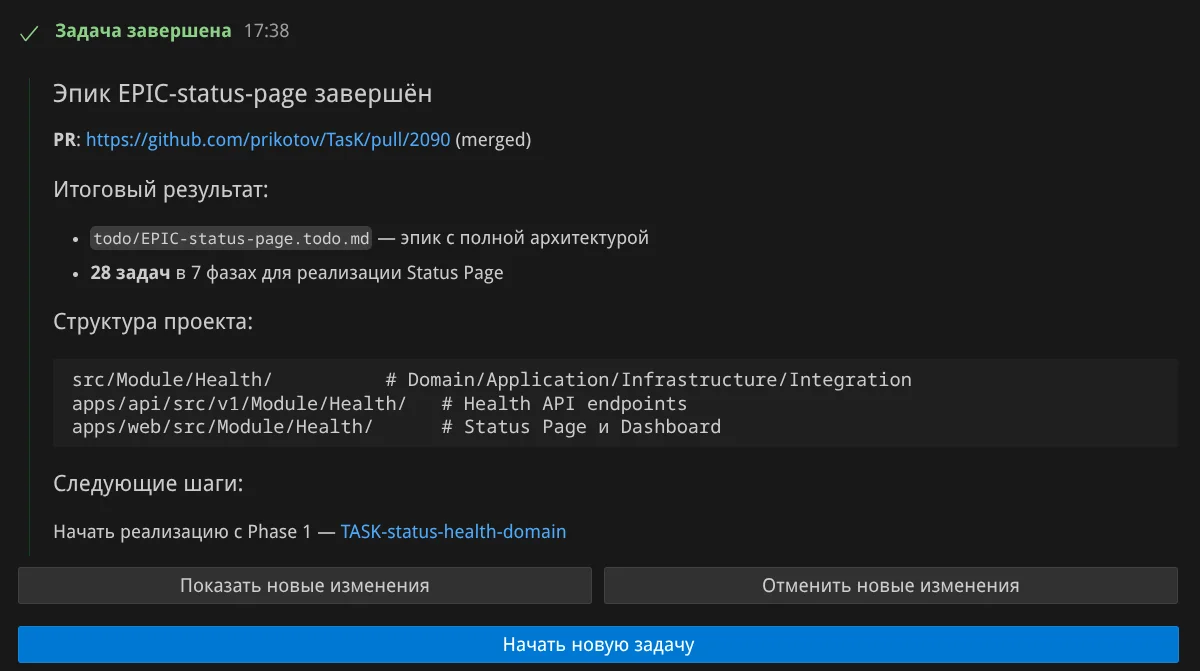
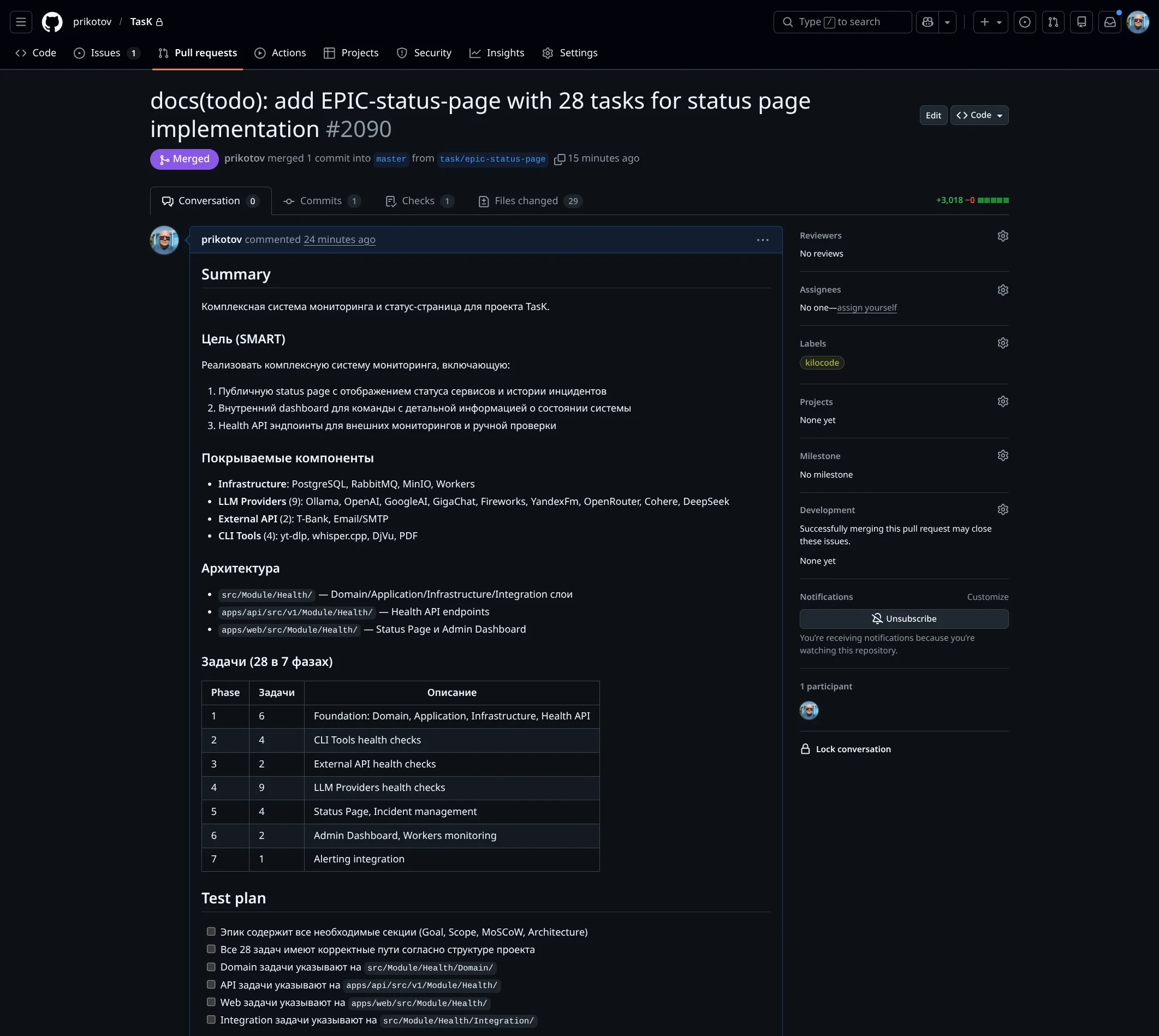
Оформление PR Агентом. Агент создал PR с заголовком "docs(todo): add EPIC-status-page with 28 tasks for status page implementation". В описании: цель задачи по SMART, покрываемые компоненты (Infrastructure, 9 LLM Providers, External API, 4 CLI Tools), архитектура модуля Health, таблица задач по фазам, test plan:
Пример работы над задачей
Запрос к агенту: Твоя роль [Бэкендер](docs/agents/roles/team/backend_developer.md). Возьми в работу задачу из todo/EPIC-status-page.todo.md

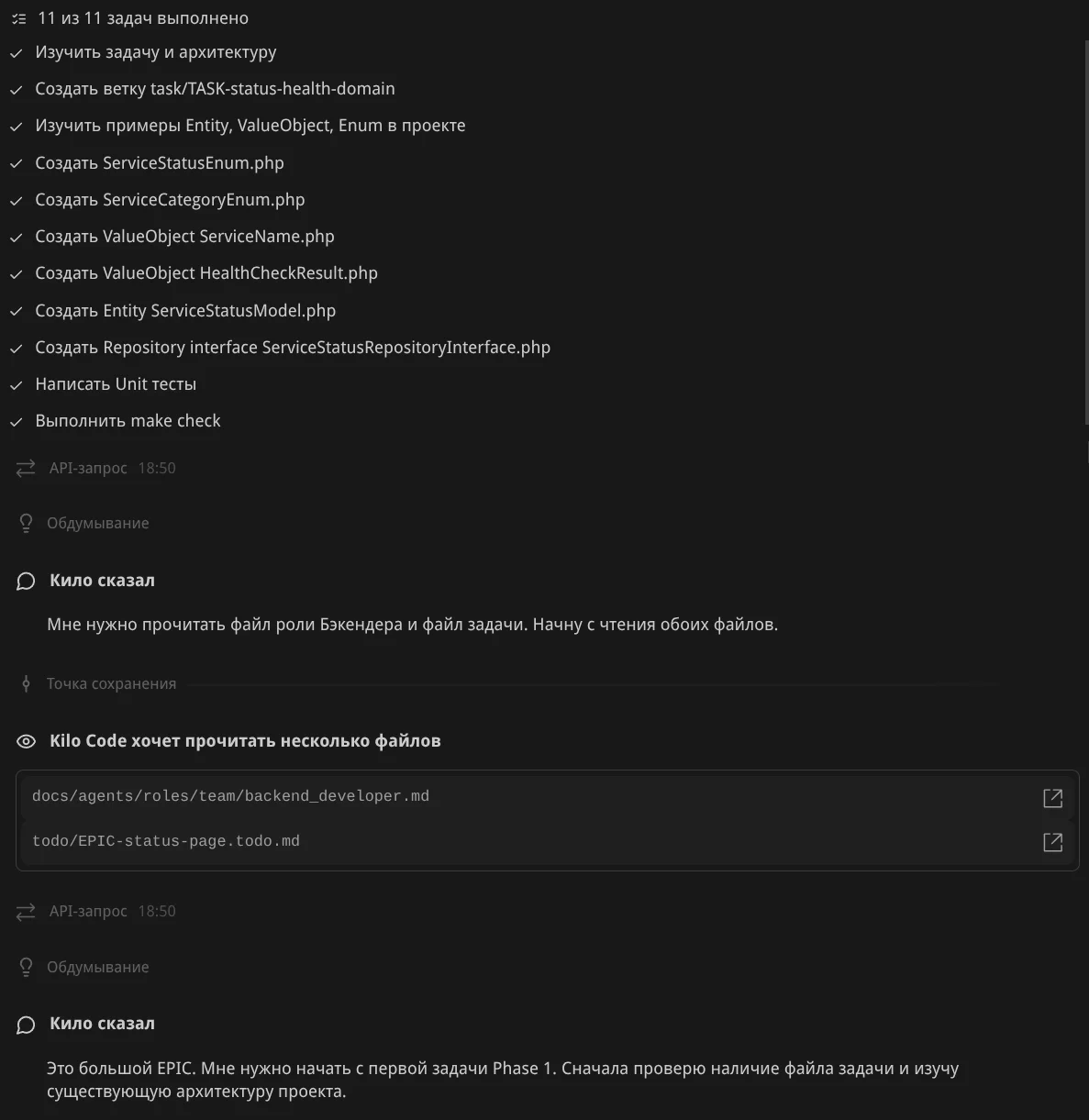
Планирование работы. Агент создал план из 11 пунктов: анализ задачи и архитектуры, создать ветку, изучить примеры Entity/ValueObject/Enum, создать ServiceStatusEnum, ServiceCategoryEnum, ServiceName, HealthCheckResult, ServiceStatusModel, Repository interface, написать Unit тесты, выполнить make check:
Пошаговые итерации опускаю — процесс аналогичен планированию эпика. Покажу финальный результат — PR.
Оформление PR Агентом. Агент создал PR "(Health): add Domain layer for Health module #2092" с 6 коммитами, +1028 -26 строк:
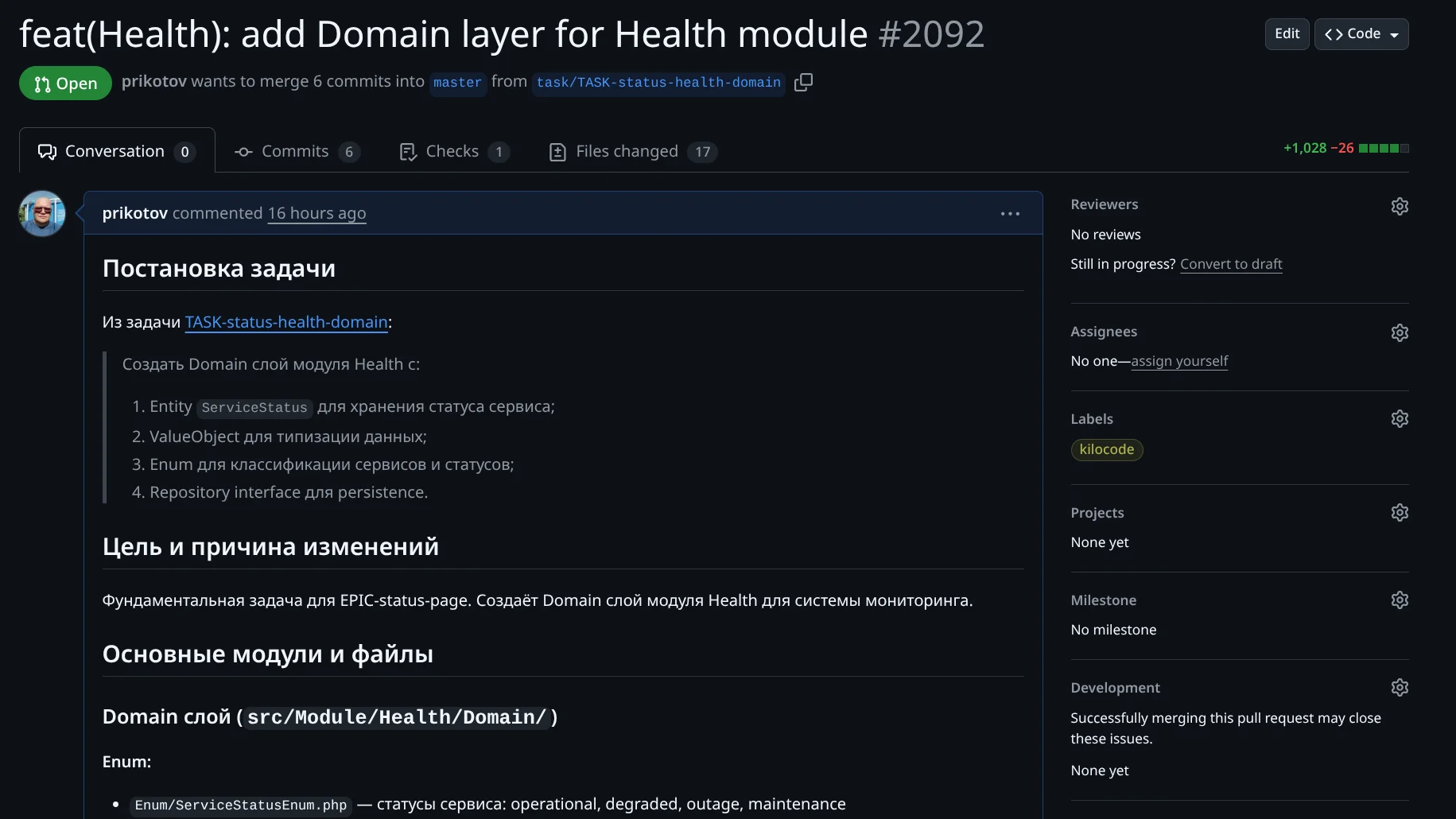
Полное описание PR:
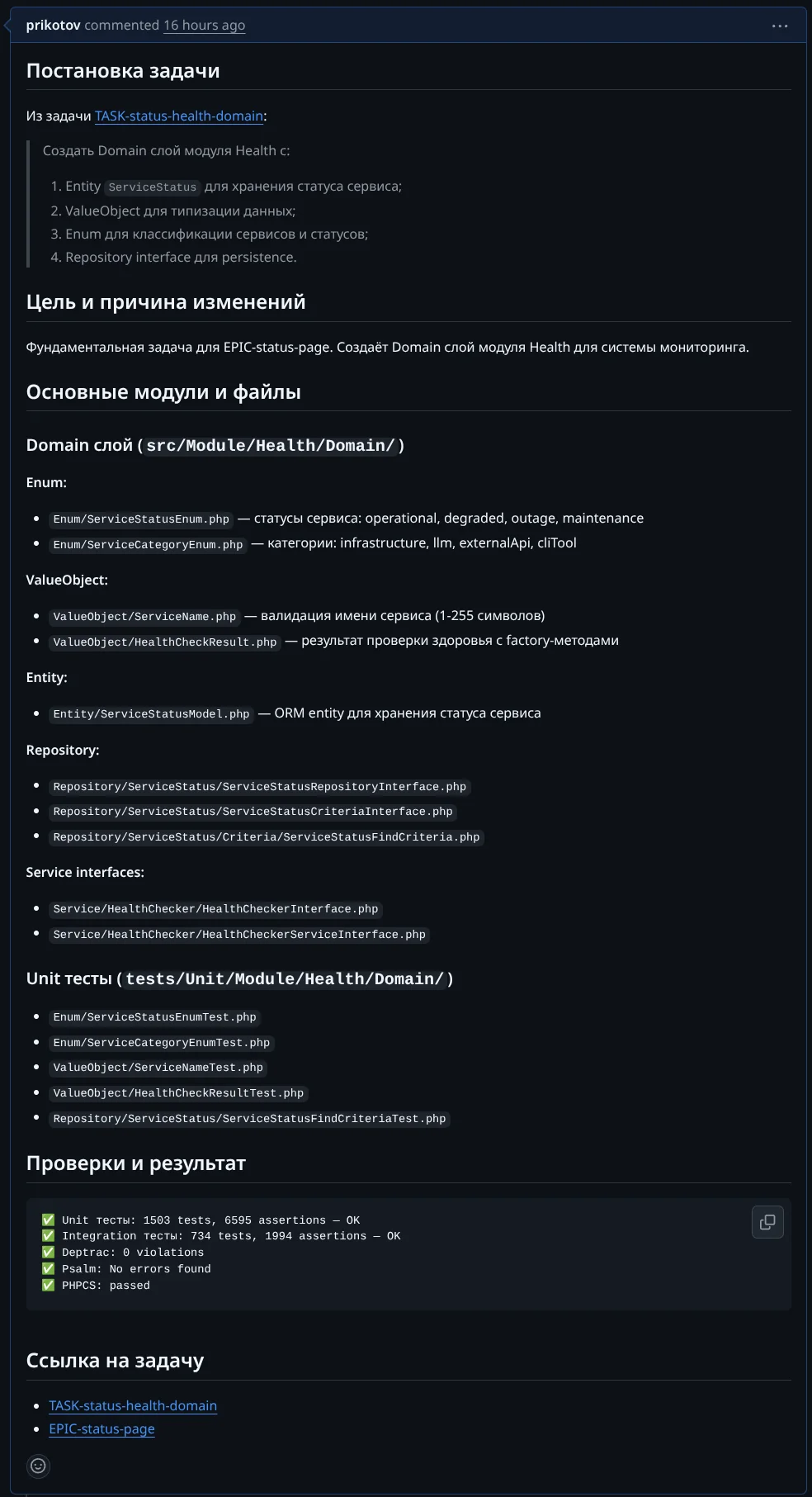
В PR есть:
- Постановка задачи с ссылкой на файл задачи TASK-status-health-domain
- Цель и причина изменений — фундаментальная задача для EPIC-status-page
- Основные модули и файлы: Enum (ServiceStatusEnum, ServiceCategoryEnum), ValueObject (ServiceName, HealthCheckResult), Entity (ServiceStatusModel), Repository interfaces, Service interfaces, Unit тесты
- Проверки и результат: Unit тесты (1503 tests, 6595 assertions), Integration тесты (734 tests), Deptrac, Psalm, PHPCS — все OK
- Ссылки на задачу и эпик
Такое оформление экономит время на ревью: сразу видно что сделано, где расположены файлы, какие проверки пройдены. Это повышает доверие к решению — агент не просто «сделал», а показал что он делал, результаты прогона тестов и статического анализа.
Особенности интерфейса Kilo Code
Kilo Code активно использует диаграммы при подготовке ответов — это улучшает восприятие и помогает понять сложные решения.
Режим Ask
Пример запроса с архитектурными вопросами:

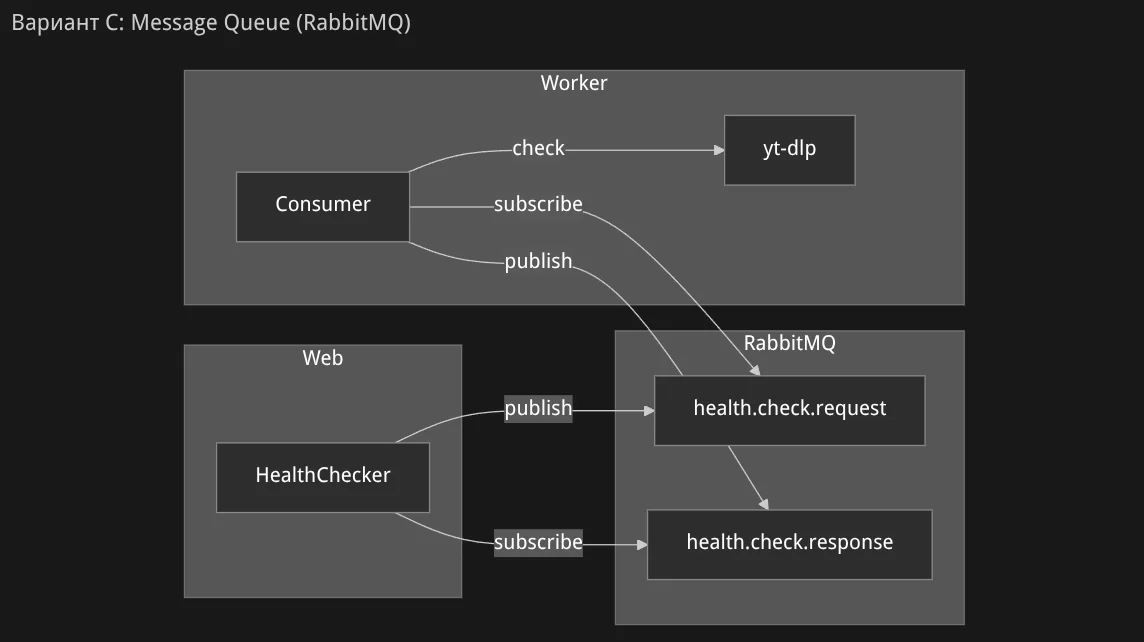
Агент строит диаграмму проблемы:


Показывает возможные решения с диаграммами:
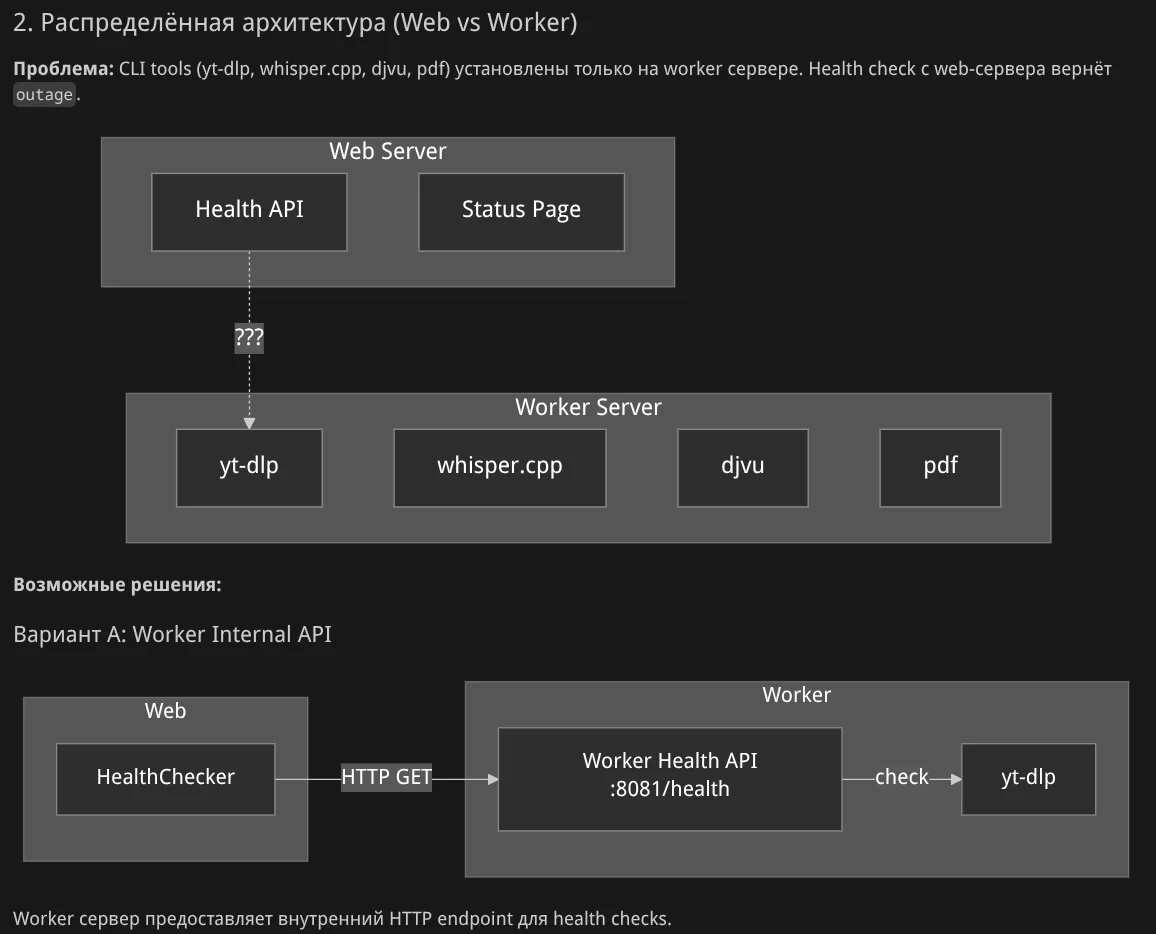
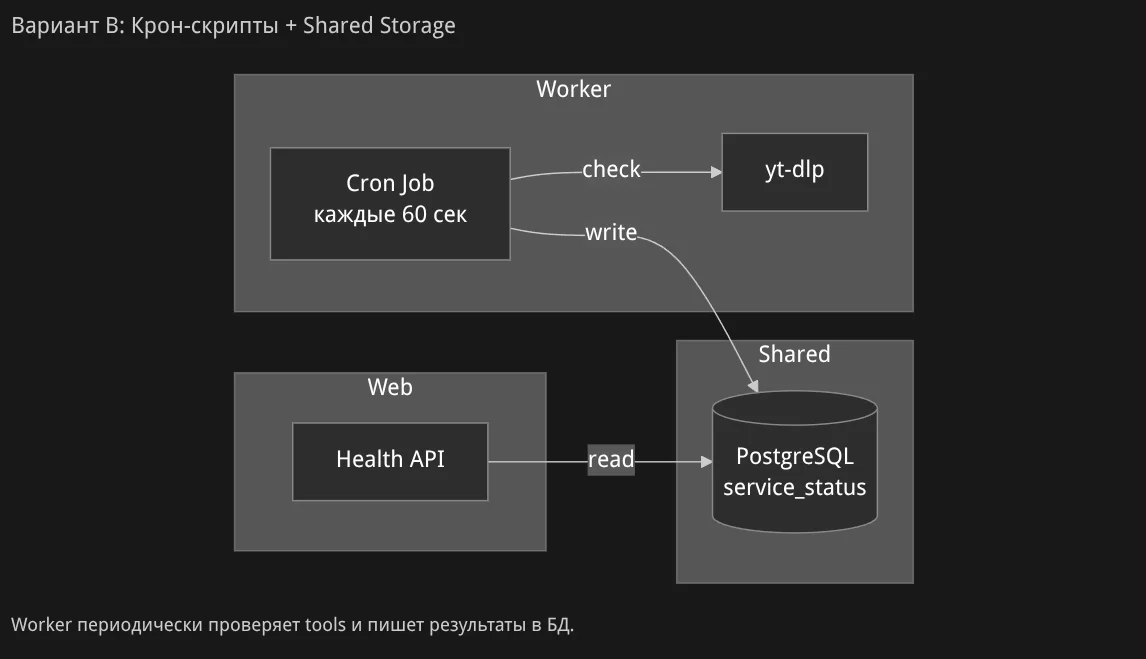

Агент предлагает варианты с ответов:
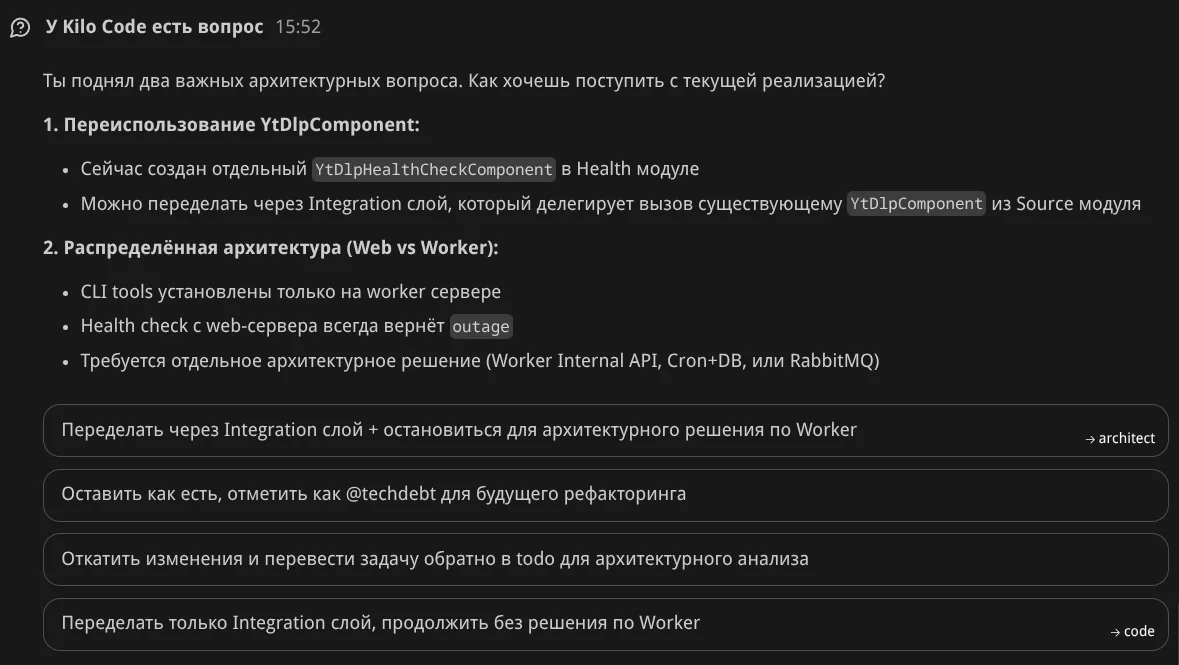
Я выбрал первый вариант — режим архитектора, подкорректировав запрос на "Integration слой + Cron+DB":

Режим Архитектора
Агент приступил к работе:

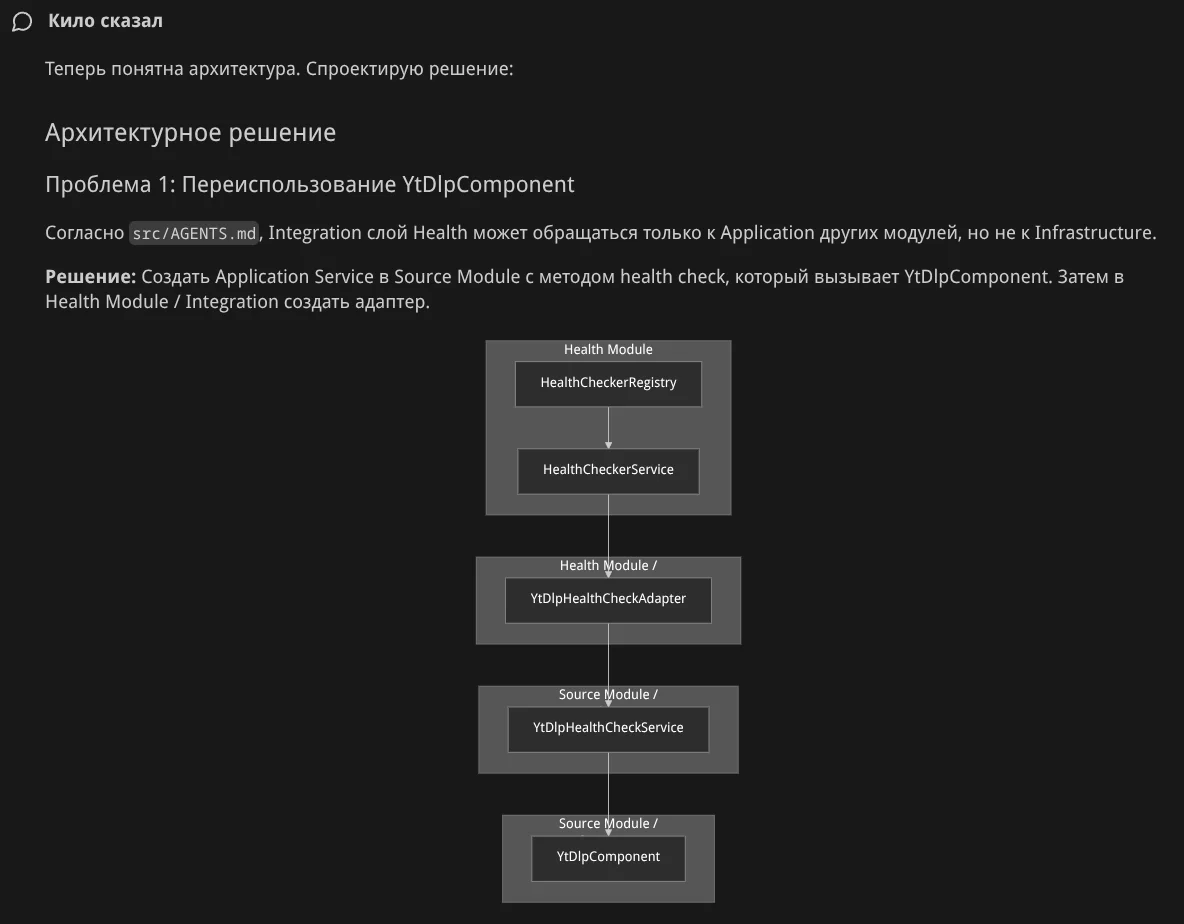
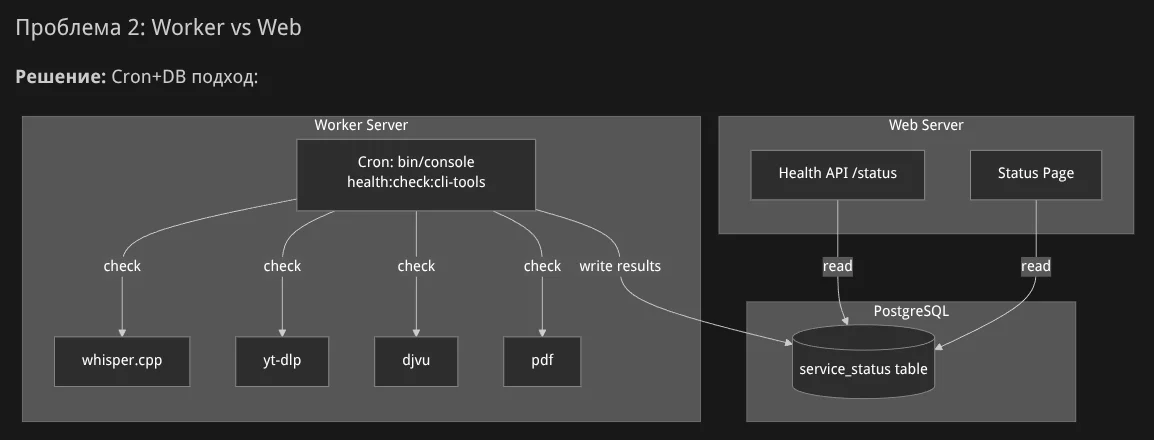
После итераций с замечаниями я получил доработанные тексты задач.
Такое оформление с диаграммами и кнопками выбора ответа я не встречал ни в одном другом кодовом агенте. Выглядит как киллер-фича — только ради неё стоит попробовать Kilo Code.
Режимы и оркестратор
Kilo Code позволяет создавать свои режимы агента и тонко их настраивать. Есть режим оркестратора — он может запускать другие роли агентов. С оркестратором можно добиться большей автономности. Я планирую перенести свои процессы и роли из AGENTS.md в режимы работы через оркестратор.
Поддержка PHPStorm. Kilo Code также работает с PHPStorm, но есть блокирующий баг: в русской раскладке не работает перевод строки.
Результат
UPD от 3 марта 2026: Вот результат того что получилось: https://task.ai-aid.pro/status
Примеры кода и задач, в следующем разделе.
📂 Примеры реализации
Чтобы лучше понять, как работают эти правила на практике, вы можете изучить реальные примеры, созданные AI-агентом:
-
Эпик — полноценная спецификация крупной фичи (Status Page), созданная агентом в роли Аналитика.
-
Задачи — в
todo/и вtodo/done/находятся файлы конкретных задач, на которые был декомпозирован этот эпик. -
Основной код — реализация логики в коде, написанная агентом по этим задачам:
-
Тесты созданные агентом для проверки реализации:
- Core Tests — unit и integration тесты.
- Web Tests — unit и e2e тесты.
Выводы по GLM-5
GLM-5 неплоха, особенно в связке с Kilo Code и его семантическим поиском. Модель слушается, контекста хватает.
Сравнение с Codex
Codex тоже ошибается, но меньше. Ощущение, что он копает глубже и замечает больше деталей.
GLM-5 пишет комментарии в коде — за Codex такого не замечал:
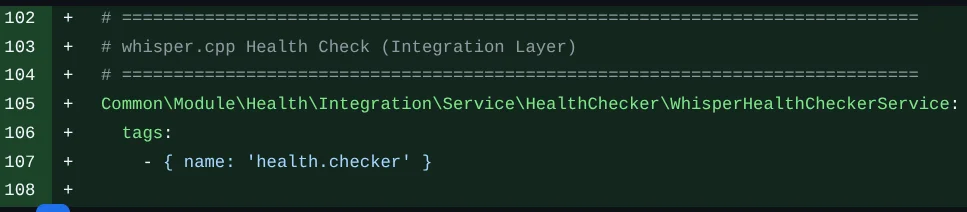
Резюме
В целом впечатление о GLM-5 положительное. Да и к использованию ИИ в кодинге я отношусь позитивно. Год назад я не предполагал, что перестану писать код руками, и насмехался над заявлениями "90% кода будет писать ИИ".
Типовые проблемы решаемы — правилами в AGENTS.md, наличием тестов и статического анализа. Я вижу путь к снижению степени своего участия в написании кода через повышение уровня автономности агента.
AI-кодинг: практика и результаты
Моя продуктивность
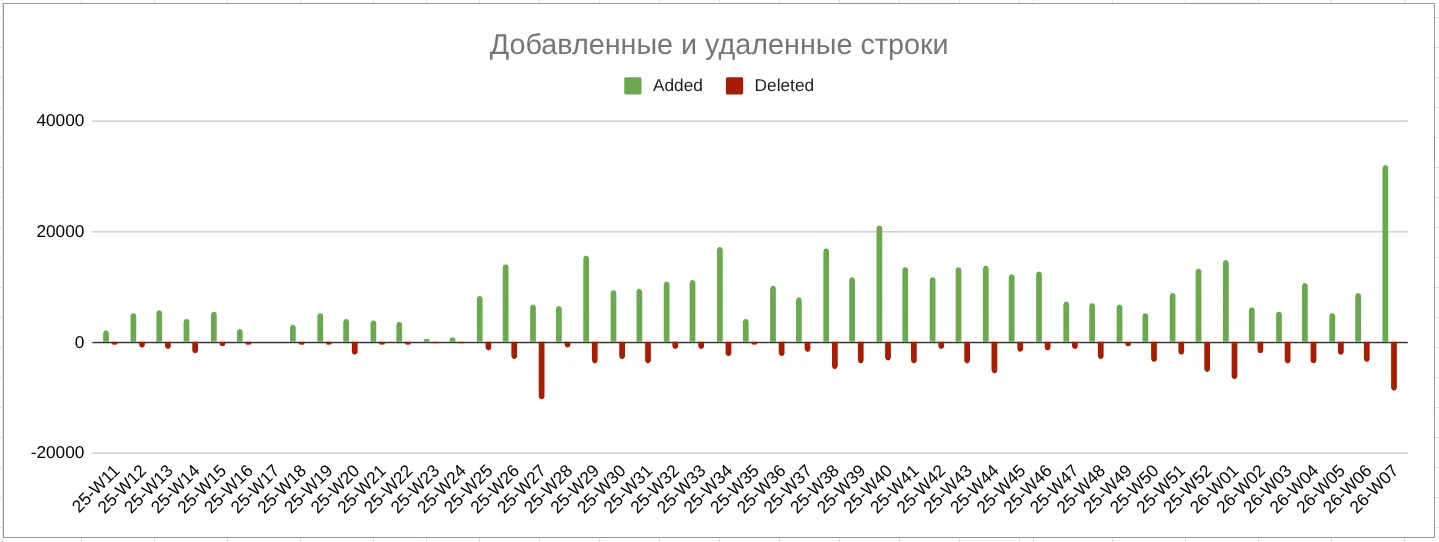
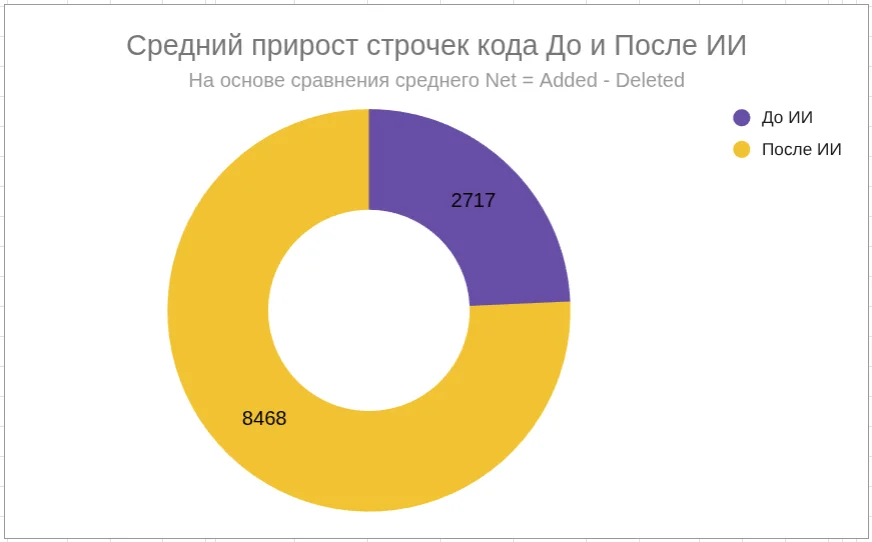
С марта 2025 года я собираю данные по динамике изменений в коде проекта в Google Sheets.
ИИ-агентов начал использовать на 25-й неделе 2025 года (с 16.06.2025), на диаграммах виден рост метрик после этой даты
Динамика добавленных и удалённых строк:
Динамика доли кода, написанного агентами:
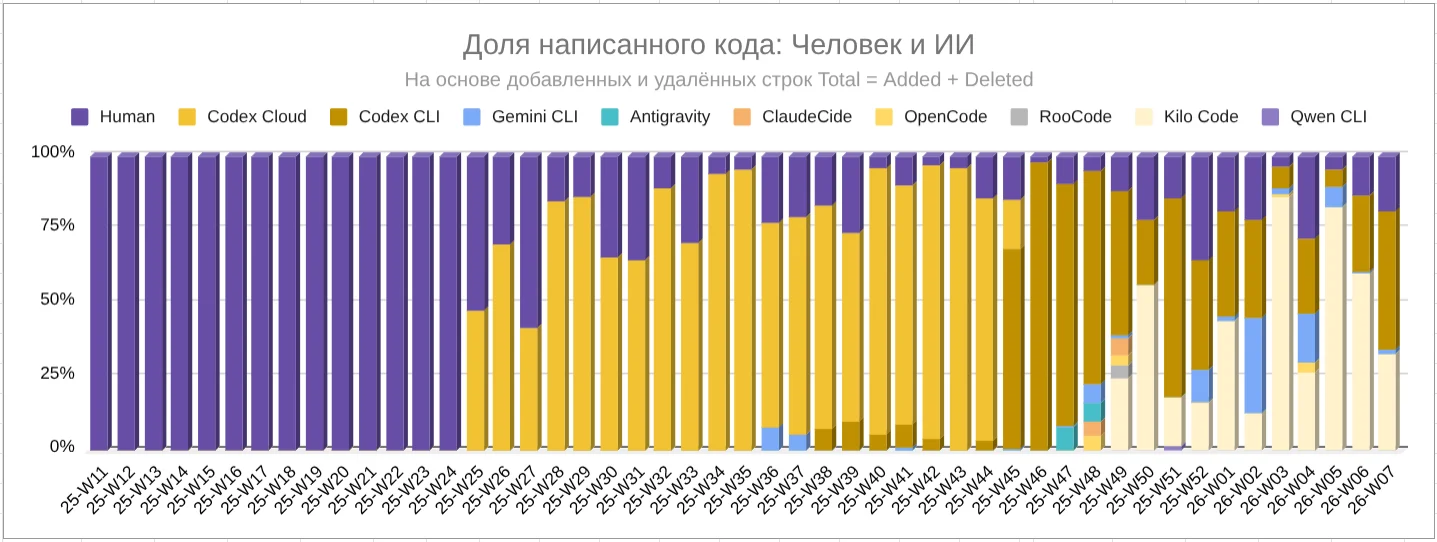
* Доля кода, написанного человеком, считается неточно — учитываются непринятые PR от ИИ-агентов. В реальности руками я уже месяцев 5 почти не пишу код.
Динамика прироста строк кода по неделям:
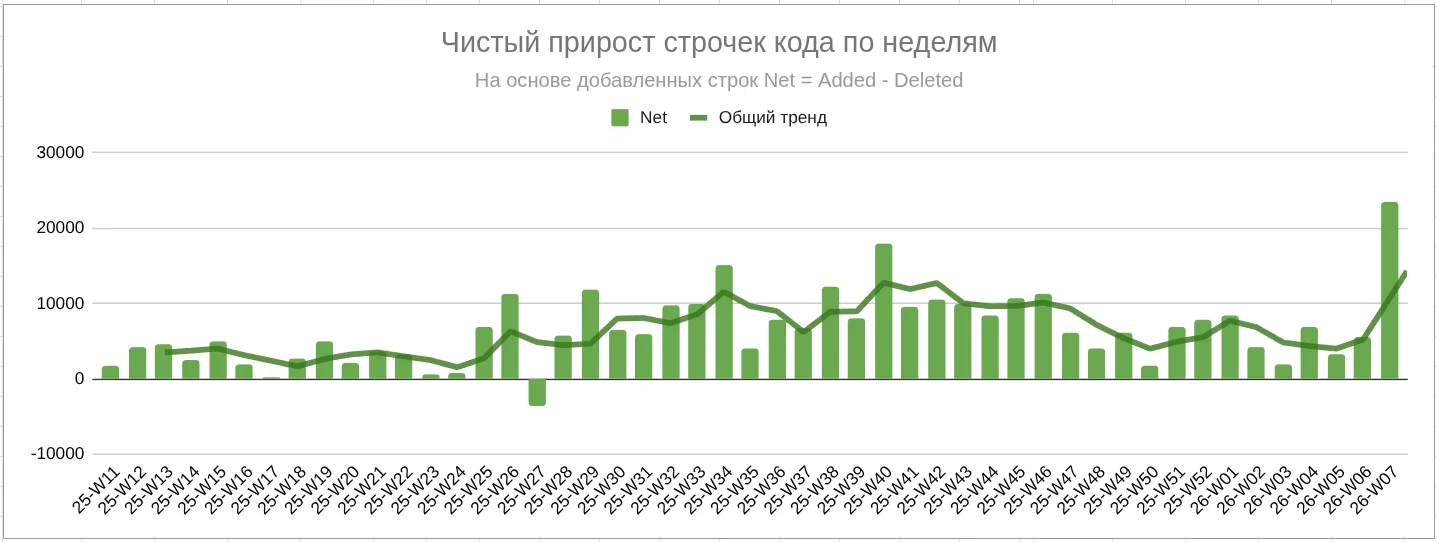
Последняя неделя показательна — я запускал задачи параллельно в Codex CLI и Kilo Code.
Итог: средний прирост кода после перехода на ИИ-агентов — в 3,1 раза.
Изменения, которые приносит AI-кодинг
Шифт в архитектуру, продукт и менеджмент. Происходит эволюция навыков: выстраивание процессов кодинга, умение ставить задачи агентам — переход от написания кода к управлению им.
Вспоминаю предыдущее место работы: владелец продукта ставил мне задачи, иногда вместе сидели над кодом для финансовых расчётов. Я для него был исполнителем, который пишет код. Теперь я в его роли, а ИИ-агент — в моей. Это и есть шифт.
Деградации нет — если правильно подходить. Видите в решении что-то непонятное? Спрашивайте: "Почему так?", "Что это?". Задавайте вопросы, пока не станет ясно. Перепроверяйте в других источниках. Тогда деградации не будет.
ИИ-агент — следующий уровень абстракции. Раньше программировали в машинных кодах, на перфокартах, на ассемблере. Раньше я писал микропрограммы для МК-61, код на ассемблере для Z-80. Сейчас ставлю задачи на человеческом языке.
Программист + ИИ = экзоскелет. ИИ усилит программиста и изменит его работу.
Полезные советы
Меньше контекста — выше качество. Модель работает лучше, когда не перегружена:
- Декомпозиция на мелкие задачи
- Оркестрация: один агент передаёт задачу другому, основной контекст остаётся чистым
- Точная терминология: вместо "красивый код" говорите SOLID, вместо "хорошая архитектура" — называйте паттерны
- Ограничьте контекст в настройках:
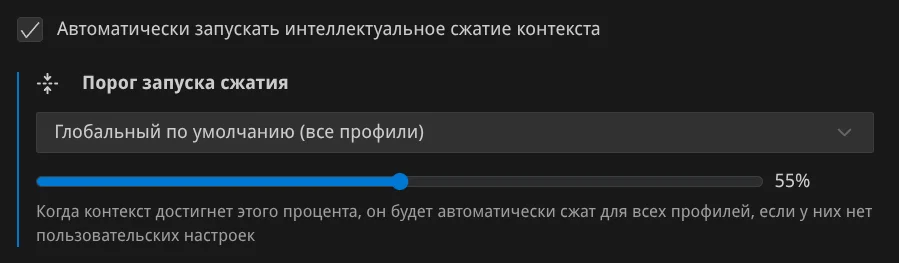
Пришёл к этому после исследований: чем больше контекст, тем ниже качество.
Звуковые уведомления. Включите в Codex CLI и Kilo Code — запустили задачу, переключились на другое, услышали сигнал — вернулись. Так не теряете время в ожидании:
В ~/.codex/config.toml: notify = ["/home/dp/bin/scripts/codex_notify_done.sh"]
Звуковые паки. На openpeon.com есть стандарт звукового сопровождения для кодинг-агентов и готовые паки. Мои любимые: юниты из Warcraft 3 ("Опять работа", "Чё надо, хозяин?"), GLaDOS ("I'm a potato" при лимитах), мурлоки ("Mrglglgl!").
Фоновое редактирование. Включите в настройках: агент правит файлы в фоне, не открывает вкладки и не забирает фокус. Иначе он будет дёргать вас каждый раз, когда что-то меняет:

Разные модели для разных задач. Ставьте задачу одной моделью, реализуйте другой. GLM-4.7 ставит — Codex делает. Или наоборот. Разные модели по-разному смотрят на задачу.
Не пропускайте плохой код. Агент учится на примерах из проекта. Пропустили говно — получите говно². Я три недели разгребал интеграционные тесты от Codex: не запускал их в пайплайне, и они накапливались. Фиксите техдолг сразу или записывайте в md-файл и решайте планомерно.
Что делать, пока агент работает
Агенту нужно время. Пока он трудится:
- Проработайте следующие задачи, улучшите правила в AGENTS.md
- Встаньте, пройдитесь, подумайте — запишите идеи
- Разомнитесь: турник, приседания, брусья
- Посмотрите развивающие ролики на YouTube (используйте TasK, чтобы агрегировать знания)
- Подумайте над стратегией проекта
- Запустите параллельно другого агента на другую задачу
Эта статья написана в промежутках между ожиданиями агентов.
Важно: держите голову в контексте проекта. Иначе при возврате забудете, о чём просили. Мне помогают: история чата и записи на бумажке.
Прагматизм вместо религиозных войн
Вместо споров "какая модель лучше" или "ИИ отупляет" — выбирайте инструмент, учитесь с ним работать, повышайте скорость без потери качества.
Каждая сессия с агентом — новая коммуникация. Напоминает общение с новичком, который только пришёл на проект. Промптинг, настройка AGENTS.md, чёткая постановка задачи — это онбординг. Даёте агенту нужный контекст — он решает задачу.
Память агента: краткосрочная и долгосрочная
Краткосрочная память — md-файлы с описанием эпика, задачи, история чата. Подгружается в сессию по вашему упоминанию. Новая сессия — новый контекст.
Долгосрочная память — конвенции, правила, шаблоны. Хранится в AGENTS.md и связанных файлах. Подгружается в каждую сессию автоматически самим агентом.
Разделяйте: то, что агент должен помнить всегда, или между сессиями — в файлы. То, что нужно только сейчас — в промпт.
Проблемы и ограничения
Работа с ИИ-агентами не идеальна. Есть вещи, которые выводят из себя.
Единых стандартов интерфейсов нет. Каждый инструмент — свои горячие клавиши для отправки сообщения. Где-то Enter, где-то Shift+Enter, где-то Alt+Enter. В Kilo Code для PHPStorm на Linux перевод строки вообще не работает в русской раскладке — ни одним способом. Случайно нажали не ту комбинацию — отправили недописанное сообщение. Агент получил обрывок, начал генерировать ерунду, токены сожгли впустую.
Приходится переучиваться при переключении между Codex CLI, Kilo Code, OpenCode. Мышечная память не работает, приходится останавливаться и задумываться какую кнопку нажать чтобы отправить сообщение агенту - это выбивает из потока.
Единых стандартов конфигураций нет. У каждого агента свои файлы настроек: GEMINI.md, CLAUDE.md, AGENTS.md, SKILL.md, .rules. Выглядят общими, но не переносятся между инструментами. Приходится дублировать правила. Я пошёл по пути работы с агентами, которые поддерживают AGENTS.md, и прописываю инструкции в отдельных файлах — агент подгружает их сам, когда нужно. Это обеспечивает переносимость правил.
Копирование плохих паттернов. Агент учится на примерах из вашего кода. В проекте есть антипаттерн — агент его подхватит и начнёт тиражировать. Приходится вычищать не только код, но и "заражённые" им новые куски.
Нецелевые траты токенов. Агент ушёл не туда, начал делать не то. Смотришь — а токены тают, лимиты кончаются. Обида и разочарование. Подписка дорогая, а результат нулевой. Как написал один чувак в Telegram: "Когда кончаются лимиты — начинается ломка".
FOMO. Новые инструменты и модели выходят постоянно. Всё не проверить, но кажется, что упускаешь что-то важное. Приходится подписываться на каналы в Telegram и YouTube, чтобы следить за новинками. Голова гудит.
Потеря контекста при параллельной работе. Запустили 2-3 сессии в разных агентах. Переключились на одну — забыли, о чём просили в другой. Вернулись — а что там было? История чата выручает, но каждый раз приходится заново погружаться. Мозг устаёт держать несколько контекстов одновременно.
Дальнейшие планы
Цель: прийти к процессу, где достаточно поставить задачу — и агент самостоятельно доводит её до конца. От анализа до мержа и деплоя. Без моего постоянного контроля, не в ущерб качеству решения.
Что планирую делать:
- Повышать уровень качества кода. Через увеличение количества правил накрывающих конвенции в статический анализе, тестах и улучшения промптинга. Агент будет отдавать код, который проходит все проверки.
- Внедрить оркестратора с ролями. Сейчас я вручную переключаю агента между ролями: аналитик ставит задачу, архитектор проектирует, бэкендер пишет код. Хочу автоматизировать эти переходы — это увеличит автономность ии-агентов.-
- Автоматизировать релиз. Сейчас подготовка релиза (тег, changelog, деплой) требует моего участия. Хочу отдать это агенту.
- Глубже изучить OpenCode. Продукт активно развивается, там появляются новые возможности. Хочу выжать максимум.
Сейчас фактически роль оркестратора выполняю я: выбираю задачи, передаю контекст между ролями, контролирую качество. Это занимает время и требует постоянного внимания. Нужно передать эти функции агенту.
Присоединяйтесь
Проект TasK развивается на энтузиазме — без инвесторов. Ищу таких же энтузиастов, которым интересен опыт работы с ИИ-агентами в AI-First продукте.
Что могу предложить:
- Практический опыт работы с ИИ-агентами в архитектурно зрелом проекте
- Опыт выстраивания процессов AI-кодинга
- Командная работа плечом к плечу
Если вам это интересно — присоединяйтесь.
Новости разработки проекта, обсуждения, вопросы — в Telegram-канале: t.me/ai_aid_pro
Ссылки
Мои предыдущие статьи:
- Мой опыт с Codex: Влияние на продуктивность
- Лимиты Codex Cloud
- Эффект Даннинга–Крюгера у больших языковых моделей (LLM)
- Командная система ИИ-агентов для разработки приложений
- Память и контекст: уроки из художественных историй для сознательного ИИ
GLM-5:
Инструменты из обзора заслуживающие внимания:
Полезное:
- Мои AGENTS.md, правила и инструкции для ИИ-агентов
- openpeon.com — звуковые паки для агентов
- Исследование про контекст и качество
Мои проекты:
- TasK — система для агрегирования знаний
Эта статья написана в Obsidian с помощью OpenCode на GLM-5 на основе материалов и инструкций, предоставленных автором.




