
Введение
Рост возможностей крупных языковых моделей (LLM) привёл к появлению автономных ИИ-агентов, способных планировать и решать задачи почти на уровне человека. Естественным шагом стало объединение нескольких таких агентов в команды, аналогичные командам разработчиков, для совместной работы над сложными проектами. Идея заключается в том, чтобы каждому агенту назначить определённую роль – техническую (например, программист, тестировщик) или личностную (лидер, генератор идей, критик и т.д.) – и наладить их взаимодействие ради общей цели. В данной статье рассматриваются существующие подходы к организации команд ИИ-агентов, возможность использования человеческих типологий ролей (DISC, Белбин, Адизес и др.) для дифференциации агентов, предлагаемая архитектура такой системы, прототип взаимодействия агентов разных ролей, обзор реализованных решений, а также оценка перспективности подхода и рекомендации по созданию MVP.
Содержание
- Введение
- 1. Существующие подходы к командным структурам ИИ-агентов
- 2. Типологии личности для ролей агентов и управления взаимодействием
- 3. Архитектурная концепция многоролевой системы агентов
-
4. Прототип взаимодействия агентов с разными ролями
- 1. Получение и анализ запроса
- 2. Планирование и декомпозиция
- 3. Постановка задач исполнителям
- 4. Разработка кода
- 5. Код-ревью и контроль качества
- 6. Тестирование
- 7. Добавление улучшений (итерации)
- 8. Документирование и оформление результата
- 9. Передача результата и закрытие проекта
- 10. Обучение на опыте (опционально)
- 11. Взаимодействие агентов
- 5. Обзор существующих решений с мультиагентными командами
- 6. Перспективы, преимущества и ограничения подхода
-
7. Рекомендации по созданию MVP такой системы
- 1. Определите узкий сценарий и состав ролей
- 2. Выберите технический стек и инструменты
- 3. Промпты и ролевые описания
- 4. Реализуйте цикл общения
- 5. Минимизируйте объемы общения
- 6. Включите человека в цикл (при необходимости)
- 7. Тестирование MVP на простых кейсах
- 8. Постепенное наращивание функционала
- 9. Инструменты мониторинга и анализ
- 10. Безопасность
- 11. Резюмируя
- Заключение
- Источники
1. Существующие подходы к командным структурам ИИ-агентов
Идея кооперации нескольких ИИ-агентов возникла как ответ на ограниченность одного, даже очень мощного, LLM в решении комплексных, разноплановых задач arxiv.org, arxiv.org. LLM-based multi-agent systems (LMA) предполагают, что различные специализированные агенты могут сотрудничать, обмениваясь информацией на естественном языке, обсуждая решения и проверяя выводы друг друга. Это напоминает работу человеческой команды, где каждый участник имеет свою экспертизу arxiv.org. Исследования показывают, что взаимодействие нескольких агентов повышает дивергентность мышления (генерацию разных идей), улучшает фактическую точность и логичность выводов, а также обеспечивает взаимную проверку результатов arxiv.org. Например, один агент может выдвигать гипотезы, а другой – критически их оценивать, что в итоге повышает достоверность финального решения.

Организация взаимодействия. Существует два основных подхода к организации работы команды ИИ-агентов: последовательный (иерархический) и коллективный (равноправный). В первом случае агенты выстраиваются в своего рода конвейер (pipeline) разработки, наподобие методологии waterfall – каждый отвечает за свой этап (аналоги фаз анализа требований, дизайна, кодирования, тестирования и пр.) arxiv.org. Примером является проект ChatDev – виртуальная ИТ-компания, где агенты-LLM последовательно выполняют задачи: СЕО ставит общую цель, продуктовый директор (CPO) формирует требования, технический директор (CTO) продумывает архитектуру, программист пишет код, ревьюер его проверяет, тестер тестирует, а дизайнер оформляет интерфейс github.com. Агенты общаются друг с другом на языке (природном или формальном) в рамках специальных «семинаров» по дизайну, кодингу, тестированию, документированию и т.д., обмениваясь артефактами разработки (текст требований, исходный код, отчёты тестов и пр.). Такой конвейер обеспечивает структурированность: результат работы одного этапа служит входом для следующего, аналогично тому, как в человеческой команде документы (ТЗ, дизайн, код) передаются от роли к роли.
Другой подход – более коллегиальный, где агенты могут одновременно обсуждать и совместно вырабатывать решение. Здесь ближе аналогия с Agile или просто мозговым штурмом: несколько агентов получают задачу и ведут диалог, предлагая идеи, споря, уточняя и в итоге сходясь на решении. В литературе такой режим называют multi-agent debate or conversation. Например, Agentic Teams – концепция команд, где разные модели (агенты) с различными сильными сторонами работают параллельно: один генерирует творческие идеи, другой фокусируется на отладке кода, третий пишет документацию, а специальный оркестратор распределяет задачи и объединяет результаты bayramblog.medium.com. Такой подход позволяет интегрировать разные навыки моделей под одним “зонтиком” координации.
Чтобы коммуникация агентов была эффективной, часто вводится специальный координатор (или менеджер, dispatcher). Это может быть отдельный агент-лидер либо внешняя управляющая программа. Например, в Microsoft AutoGen – открытом фреймворке для создания систем из общающихся агентов – предусмотрен единый интерфейс для определения агентов с разными ролями и задание шаблона их диалога arxiv.org, arxiv.org. Разработчик явно программирует, какие агенты участвуют (например, “CoderAgent”, “TesterAgent”, “CriticAgent”) и как они обмениваются сообщениями (например, в скрипте диалога задаётся, кто кому что говорит и когда) arxiv.org, arxiv.org. В некоторых решениях, наоборот, взаимодействие менее жёстко задано – агенты просто помещаются в общий чат, и каждый реагирует на сообщения согласно своей роли. Однако при большом числе агентов это может приводить к хаосу или лишним сообщениям, поэтому часто предпочитают либо иерархические схемы, либо небольшой “совет” из 2-3 агентов.
Специализация агентов. Ключевым моментом является, что каждый агент наделяется специфическими знаниями и стилем работы, соответствующими определённой роли. Разработчики таких систем часто берут роли из реального опыта команд разработки ПО. Так, проект MetaGPT (2023) предложил многоагентную систему, где роли представлены классическими позициями в IT: продакт-менеджер, архитектор, тим-лид (project manager) и инженер-программист arxiv.org. Каждая роль снабжена собственным контекстным промптом, описывающим её задачи, цель и ограничения: например, «Ты – Архитектор, отвечающий за разработку системного дизайна, твоя цель – спроектировать устойчивую архитектуру, ограничения – соблюдать принципы SOLID…». Благодаря этому агенты получают “личность” эксперта нужного профиля arxiv.org arxiv.org. В MetaGPT особое внимание уделено внедрению SOP (Standard Operating Procedures) – стандартов взаимодействия, принятых у людей. Агенты формируют артефакты вроде документа требований, дизайн-спецификаций, списков задач, кода и тестовых отчётов по установленным шаблонам arxiv.org arxiv.org. Эксперименты показали, что такая стандартизация и разбиение работ между ролями повышает качество результатов по сравнению с использованием одиночного ChatGPT или простых автономных агентов типа AutoGPT arxiv.org arxiv.org.
Помимо MetaGPT и ChatDev, появилось множество других попыток. Например, известен фреймворк CAMEL (Communicative Agents for “Mind Exploration” или др.) arxiv.org, где два агента в ролях “User” и “Assistant” ведут роль-ориентированный диалог для решения задачи – фактически, один выступает заказчиком, другой исполнителем, и через расспрос требований и уточнения они приходят к решению задачи. Li и др. (2023) сообщили, что такой подход с двумя ролями позволил успешно реализовать автоматическое программирование по описанию задачи на одном языке arxiv.org. Другие исследования расширили число агентов. Так, Qian др. (2024) использовали команду агентов для полного цикла разработки ПО от требований до тестирования, имитируя последовательность шагов, хотя взаимодействие агентов строилось просто через обмен обычным текстом без специальных формализаций arxiv.org arxiv.org. Проект ChatDev уже упоминался – он стал одним из первых практически реализованных прототипов: доступны исходные коды, позволяющие развернуть “виртуальную компанию” из агентов-разработчиков. ChatDev работает в цепочечном режиме (chain-shaped topology) с возможностью настройки фаз и ролей, а недавно там реализовали даже более сложные топологии (MacNet), допускающие сотни агентов, организованных в виде сетей для совместной работы над задачами github.com.
В целом, текущие подходы показали жизнеспособность концепции: ИИ-агенты действительно могут разбираться по ролям и координировать усилия для выпуска непростых продуктов (например, простые игры, веб-приложения) практически без участия человека.
2. Типологии личности для ролей агентов и управления взаимодействием
Интересный аспект – придание агентам человеко-подобных личностных черт и использование известных психологических типологий для формирования команды. Гипотеза состоит в том, что команда ИИ, в которой агенты имитируют разные стили мышления и поведения, может работать эффективнее и устойчивее, подобно тому, как разнородная по темпераментам и навыкам человеческая команда обычно обходит по результативности однородную группу. Рассмотрим три наиболее известных типологии командных ролей и как их можно применить к дизайну системы агентов:
Модель DISC
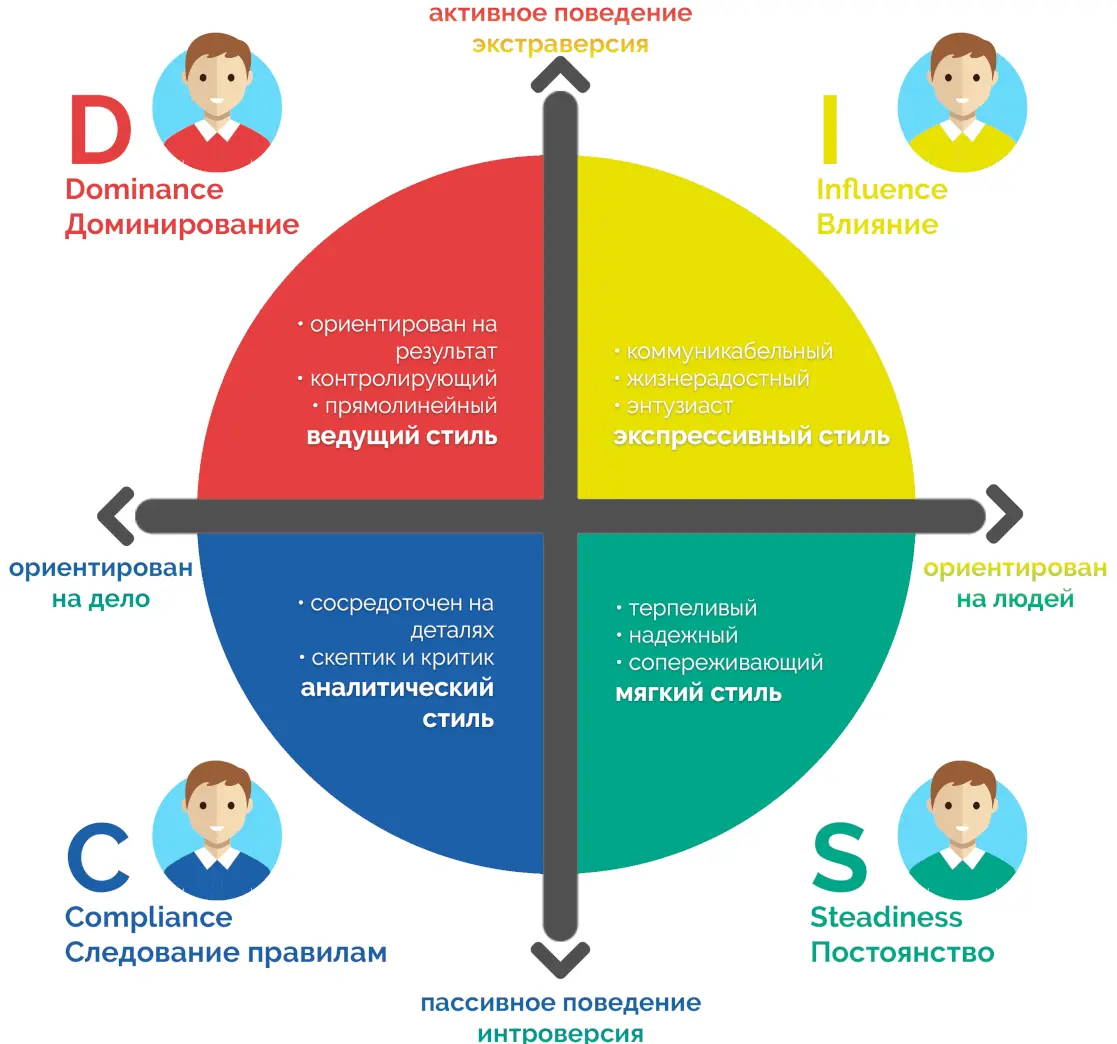
Согласно DISC, люди (и потенциально агенты) проявляют четыре основных поведенческих стиля: D - Dominance (Доминантность) – стремление контролировать, решительность; I - Influence (Влияние) – коммуникабельность, генерация энтузиазма; S - Steadiness (Уравновешенность) – поддержка, стабильность, склонность сотрудничать; C - Conscientiousness (Добросовестность) – аналитичность, внимание к деталям, преданность правилам. В команде ИИ это можно отразить в манере общения и приоритетах каждого агента. Например, агент типа D мог бы брать на себя лидерство: ставить цели, подталкивать остальных к результату, иногда идя на риск. Агент I – быть генератором идей, предлагать креативные решения, активно общаться и вдохновлять (в контексте разработки это может быть, например, генерация идей новых фич или нестандартных подходов к реализации). Агент S – выступать командным игроком-исполнителем, который терпеливо доводит начатое до конца, согласовывает между участниками, следит за стабильностью процесса. Агент C – играть роль скрупулёзного критика/контролёра: проверять соответствие стандартам, искать ошибки, обеспечивать качество и соответствие требований. Распределив между агентами такие стили, разработчики могут получить более живой и сбалансированный диалог: “dominance”-агент не даст процессу зайти в тупик, “Influence”-агент не позволит упустить новые возможности, “conscientiousness” отловит просчёты, а “steadiness” сгладит конфликты и удержит фокус.
Модель Белбина
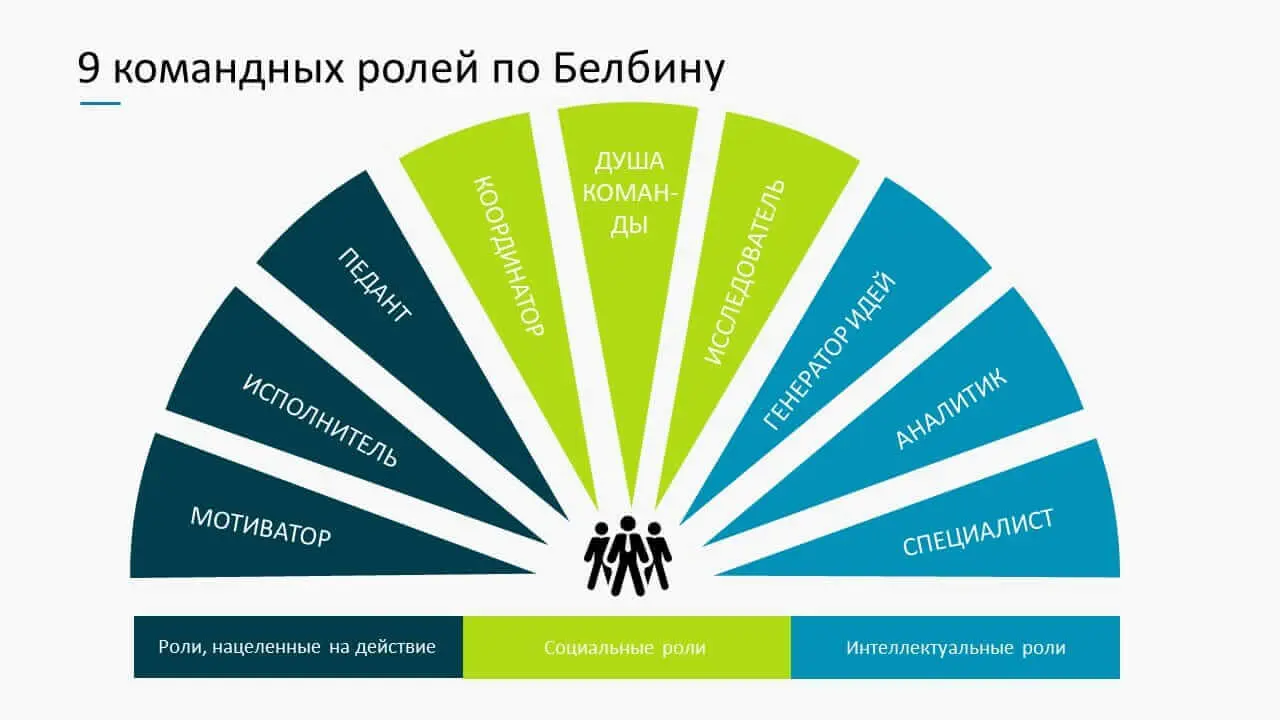
Классическая модель Белбина выделяет 9 командных ролей, объединённых в три группы: мыслящие роли, социальные роли и деловые роли. Ниже приведены эти роли и возможная их реализация среди ИИ-агентов:
| Роль Белбина | Описание роли в человеческой команде | Возможная функция AI-агента в команде разработки |
|---|---|---|
| Генератор идей (Plant) | Креативный новатор, предлагает оригинальные идеи, нестандартные решения. | Агент-идеолог: придумывает архитектурные решения, новые фичи, нестандартные подходы к реализации. |
| Аналитик-оценщик (Monitor Evaluator) | Трезво и всесторонне анализирует предложения, взвешивает pro и contra, предвидит трудности. | Агент-критик/эксперт: оценивает идеи и дизайн на реалистичность, проверяет качество кода, указывает на ошибки и риски. |
| Координатор (Coordinator) | Организует работу команды, выявляет сильные стороны других, делегирует задачи. | Агент-лидер/менеджер: распределяет задачи между другими агентами, следит за соблюдением плана и сроков, синтезирует результаты. |
| Мотиватор (Shaper) | Динамичный драйвер, мотивирует команду достигать целей, преодолевает препятствия. | Агент-инициатор: подталкивает обсуждение вперёд, не даёт застояться, предлагает смелые решения, особенно когда есть тупик. |
| Командный игрок (Teamworker) | Дипломат, поддерживает командный дух, помогает в коммуникациях, сглаживает конфликты. | Агент-медиатор: следит за согласованностью агентов, может перефразировать и уточнять сообщения, предотвращать противоречивые действия (в ИИ-контексте эта роль менее осязаема, но может выражаться в согласовании форматов данных, единообразии стиля ответов и т.п.). |
| Исследователь ресурсов (Resource Investigator) | Общительный разведчик, ищет идеи и ресурсы вовне, привносит внешнюю информацию. | Агент-разведчик: отвечает за поиск внешних данных и инструментов – например, ищет в интернете информацию, находит подходящие библиотеки/код, чтобы помочь реализации. |
| Исполнитель (Implementer) | Практик, превращает идеи в конкретные задачи, работает структурированно и надёжно. | Агент-программист: пишет основной код по заданному дизайну, структурирует проект (файлы, модули), следуя лучшим практикам. |
| Доводчик (Completer Finisher) | Перфекционист, тщательно проверяет детали, тестирует, исправляет последние ошибки. | Агент-тестировщик/отладчик: запускает тесты, ищет баги, оптимизирует производительность, шлифует код до идеально рабочего состояния. |
| Специалист (Specialist) | Обладает глубокими знаниями в узкой области, которых нет у других. | Агент-эксперт: содержит специализированные навыки/модель для решения специфической задачи – например, ИИ со знанием UX-дизайна для оценки интерфейса или модель для генерации графики, если нужно создать дизайн элементов. |
Команда, охватывающая все или большинство таких ролей, считается по Белбину сбалансированной и способной к высокой продуктивности. Применение этого к ИИ означает, что разработчики системы могут явно ввести агентов с функциями, аналогичными перечисленным. Мы уже видим подобное в ChatDev (есть и дизайнер, и тестер, и ревьюер, покрывая роли Исполнителя, Доводчика и отчасти Специалиста) github.com. Не все роли Белбина легко переводимы в чисто машинный мир (например, роль Командного игрока, отвечающего за эмоциональный климат, для ИИ менее релевантна), однако аналитик, генератор идей, координатор, исполнитель и перфекционист – уже понятные амплуа для агентов. Так, результаты одного из исследований по интеграции ИИ в команды подтвердили, что для ИИ-ассистентов естественно выделяются именно четыре схожие роли: координатор, создатель (генератор идей), перфекционист и исполнитель link.springer.com. Это во многом перекликается с моделью Белбина и отражает ключевые функции, необходимые для успеха проекта.
Модель Ицхака Адизеса
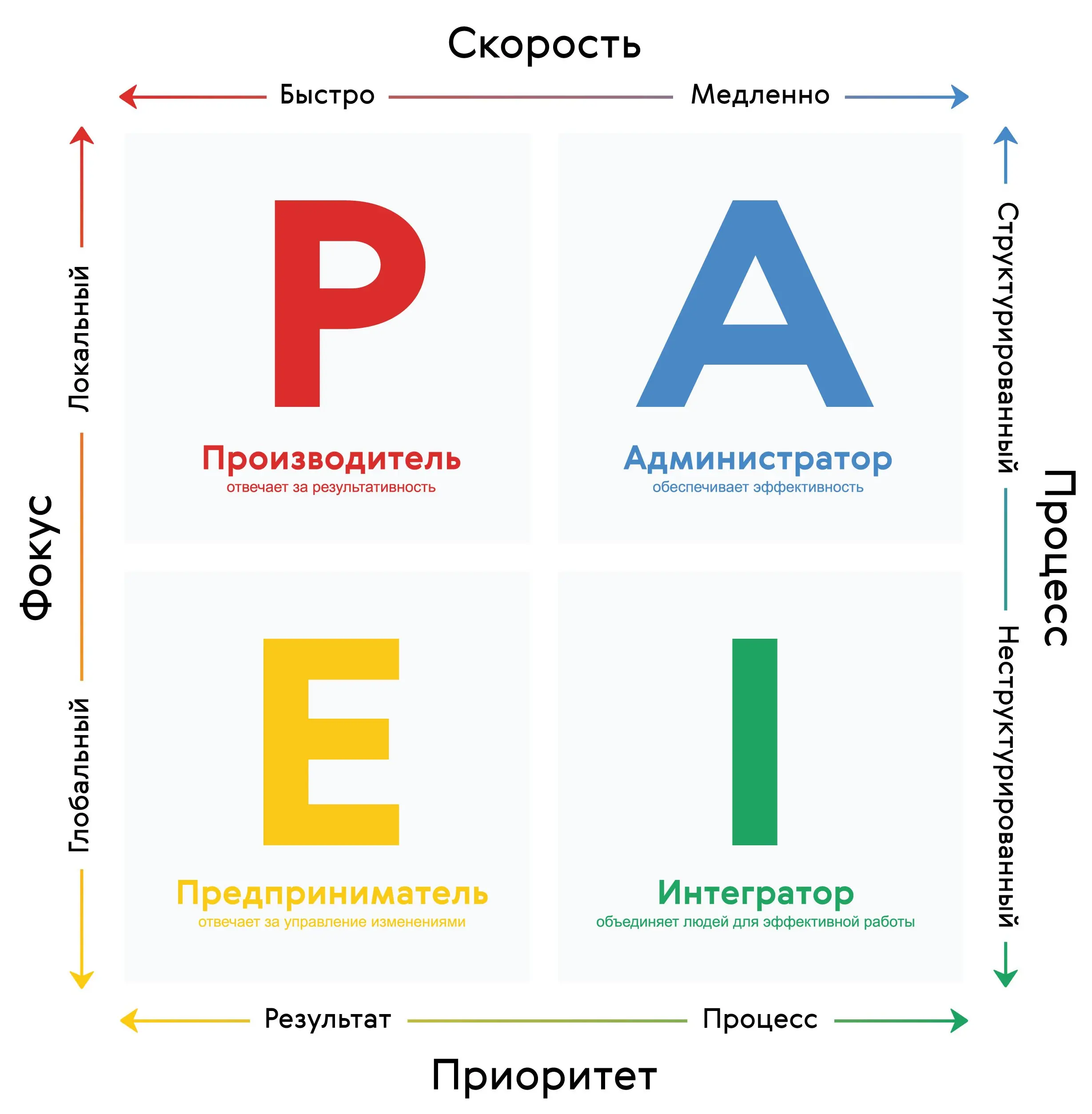
Модель Ицхака Адизеса выделяет четыре архетипических роли менеджмента: P - Producer (Производитель) – ориентирован на результат, делает работу; A - Administrator (Администратор) – вводит структуры и порядки, контролирует ресурсы; E - Entrepreneur (Предприниматель) – генерирует видение, новые идеи, изменяет систему; I - Integrator (Интегратор) – объединяет команду, заботится о гармонии, долгосрочной устойчивости. В эффективной организации должны присутствовать все четыре функции, хоть и не обязательно в одном человеке. В применении к ИИ-команде можно мысленно наделить агентов этими управляющими ролями:
- Агент-“Producer” – это условно трудяга, который будет писать код и выдавать осязаемые результаты. По сути, это основной исполнитель задач.
- Агент-“Administrator” – отвечает за структуру и процесс: в ИИ-команде он мог бы следить за тем, чтобы код соответствовал стандартам, велась документация, спринты выполнялись по плану. Такой агент может, к примеру, генерировать и проверять чек-листы, вести трекинг задач, управлять версионностью (в ChatDev, например, есть интеграция с Git и можно представить, что за это отвечает «администратор» системы) github.com.
- Агент-“Entrepreneur” – это визионер, генерирующий идеи и направляющий развитие продукта. Он мог бы предлагать новые функции, менять требования по мере необходимости, оценивать продукт с точки зрения рынка или пользователя (в том же ChatDev роль CPO – Chief Product Officer – по сути предпринимательская, формулирующая продуктовую ценность) github.com.
- Агент-“Integrator” – заботится об согласованности и командной культуре. Для ИИ-агентов это может означать поддержание общего контекста и памяти: следит, чтобы все агенты располагали актуальной общей информацией, объединяет частичные результаты в цельную картину. В ряде систем эту функцию выполняет общая память/база знаний, к которой все агенты обращаются arxiv.org arxiv.org, а также протокол коммуникации, гарантирующий, что каждый агент получает необходимые ему сведения. Интегратор-агент мог бы также решать конфликты – например, если генератор идей и аналитик зашли в спор, интегратор помогает взвесить их аргументы и прийти к компромиссу.
Применение моделей типологии личности
Применение моделей вроде Белбина и Адизеса помогает структурировать разработку системы – разработчик явно прописывает роли агентов в терминологии этих моделей, не упуская важных функций. Кроме того, эти модели дают подсказки, как управлять взаимодействием: например, по Адизесу известно, что “предприниматели” могут конфликтовать с “администраторами” (первые хотят быстро менять направление, вторые – стабильности), и в ИИ-команде можно предусмотреть, чтобы их коммуникация шла через интегратора или по четкому регламенту. По Белбину “генератор идей” часто не дружит с дисциплиной, и для его предложений нужен монитор-оценщик. Заложив такие паттерны, мы можем улучшить эффективность агентского общения. Также типологии указывают на необходимость разнообразия: однородная команда (например, все агенты – только “исполнители” без генераторов идей и критиков) будет страдать либо низкой креативностью, либо слепыми зонами в контроле качества. Поэтому при проектировании мультиагентной системы на базе LLM стоит сделать агентов максимально разными, дав им чёткие и отличающиеся роли, личности и даже разные модели/навыки. Практика показывает, что это приносит результаты. Например, в MetaGPT агенты действительно выступают как “mixture of experts” – смесь экспертов: каждый со своей областью, и вместе они справляются с задачами лучше, чем один универсальный агент jingdongsun.medium.com. А в эксперименте Stanford с Generative Agents (симуляция 25 персонажей в виртуальном городке) каждому агенту задали уникальную биографию, черты характера, интересы – и в результате они демонстрировали очень правдоподобное разнообразие поведения и успешное координированное взаимодействие (например, сумели организовать вечеринку в симуляции, разослав друг другу приглашения и собравшись вовремя) hai.stanford.edu hai.stanford.edu. Это подчёркивает ценность наделения агентов индивидуальностями.
Конечно, нужно учитывать и ограничения: слишком сильное “различие характеров” агентов может привести к конфликтам или тупику, если не определены механизмы разрешения. Поэтому при внедрении личностных типологий важно также задать правила и приоритеты: например, финальное решение остаётся за агентом-лидером, даже если “генератор идей” и “критик” не пришли к согласию, или же в случае спора команда может привлекать дополнительный агент-арбитр либо обратную связь человека.
3. Архитектурная концепция многоролевой системы агентов
С учётом вышесказанного, можно представить целостную архитектуру системы, где несколько LLM-агентов работают как команда разработчиков корпоративного приложения. Архитектура включает следующие основные компоненты и роли:
Заказчик
Интерфейс пользователя / Заказчик: внешний пользователь (человек), который ставит задачу системе в виде запроса на разработку (например, описание требуемого веб-приложения). Этот запрос поступает в систему и инициирует процесс.
Координатор
Агент-лидер (координатор, “Project Manager”): центральный узел системы. Он принимает задачу от пользователя, анализирует требования и генерирует план действий. Лидер отвечает за коммуникацию с пользователем: может уточнять требования, задавать вопросы, а по завершении – предоставлять результат разработки или отчёты. Внутри команды лидер распределяет задачи между остальными агентами и следит за прогрессом. Он же агрегирует результаты работы всех агентов в единый продукт. Эта роль критически важна – фактически, агент-лидер выполняет функции менеджера проекта и Product Owner’а одновременно, говоря на языке Scrum.
Исполнители
Агенты-исполнители (технические роли): специализированные агенты, каждый из которых отвечает за определённую часть разработки. Конкретный набор таких агентов зависит от типа проекта, но для веб/мобильного приложения логично иметь, например:
Архитектор
Агент-архитектор – продумывает высокоуровневую архитектуру системы, разбивает систему на модули, выбирает технологический стек. Он генерирует технический дизайн: например, решает, какие сервисы и базы данных потребуются, как будут взаимодействовать фронтенд и бэкенд, и пр.
Программист
Агент-программист(ы) – реализуют код. Если приложение сложное, могут быть отдельные программисты по направлениям: например, frontend-разработчик (UI, клиентская часть) и backend-разработчик (серверная логика, API). Возможна дальнейшая специализация: агент, ответственный за интеграцию с внешними API, агент по работе с базой данных и т.д. Но на первом этапе один универсальный “Coder” может писать код для всех частей, либо два агента – один для интерфейса, другой для серверной части.
Тестировщик
Агент-тестировщик (QA) – разрабатывает и выполняет тесты, проверяет работоспособность созданного кода. Он генерирует тест-кейсы (юнит-тесты, сценарии пользовательского тестирования) и может пытаться запустить код (в безопасной среде), проверяя, нет ли ошибок. Если ошибки находятся или тесты падают, тестировщик сообщает об этом программистам для исправления.
Технический писатель
Агент-документатор – занимается написанием документации: пользовательской (руководство пользователя, README) и технической (описание API, комментарии к коду, спецификации). Часто об этой части забывают, но наличие такого агента улучшит итоговое качество продукта, особенно для корпоративных приложений, где важны сопроводительные материалы.
Дизайнер
Агент-дизайнер – если нужен дизайн UI/UX или графические материалы, можно включить агента, генерирующего дизайн-макеты или даже непосредственно компоненты интерфейса (возможно, используя специальные модели для генерации изображений по тексту). В ChatDev, например, упоминается роль Art Designergithub.com. Этот агент мог бы предлагать прототипы экранов, цветовые схемы и пр., или генерировать CSS-стили на основе описаний.
Контроль и ретроспектива
Агенты-критики (контроль и идеи): помимо агентов, непосредственно пишущих код или тесты, полезно включить роли, которые оценивают и улучшaют решения:
- Агент-аналитик/критик – рассматривает архитектуру и код, предложенные другими, на предмет потенциальных проблем. Например, проверяет, соблюдаются ли требования и ограничения. Может выступать “адвокатом дьявола”: задавать неприятные вопросы (“Что если нагрузка вырастет? Что если пользователь введёт некорректные данные? Нет ли угроз безопасности?”) и тем самым повышать надёжность решения. Такой агент выполняет роль Monitor Evaluator (по Белбину) или Quality Assurance engineer в широком смысле.
- Агент-генератор идей – творческий оппонент критику. Его задача – генерировать альтернативы, предлагать улучшения. Например, если архитектор выбрал определённый шаблон проектирования, генератор идей может предложить другой подход или дополнительную функциональность, о которой не просил заказчик, но которая повысит ценность продукта. Он же может подсказывать программистам нестандартные алгоритмы, оптимизации. В паре с критиком они создают дискуссию, из которой лидер-агент выберет оптимальный вариант.
Общее рабочее пространство и память
Общее рабочее пространство и память: в архитектуре предусматривается модуль, обеспечивающий хранение и обмен информацией между агентами. Это аналог офисного пространства или общих документов для команды. В реализации это может быть:
-
Общий контекст диалога: если агенты общаются через языковые сообщения, то всем им доступна история переписки (или её релевантная часть). Например, в MetaGPT реализован Global Memory Pool – общая память, куда складываются все сообщения и данные, и откуда агенты могут выбирать нужный контекст arxiv.org.
-
Общее хранилище артефактов: база, где хранятся промежуточные результаты – текущая версия требования, дизайн-схемы, исходники кода, скомпилированные модули, логи тестов и т.п. Агенты могут читать/писать туда. Это можно реализовать через файловую систему (агенты генерируют файлы), либо через специальные структуры данных в памяти программы.
-
Интеграционная среда (инструменты): Команда агентов – это не только сами LLM, но и окружение, где они выполняют задачи. Например, для разработки кода необходим компилятор/интерпретатор для запуска и проверки. Поэтому в архитектуре стоит компонент Code Execution Environment – безопасная “песочница”, где код, сгенерированный агентами, может исполняться (например, Docker-контейнер, как в ChatDev github.com). Агент-тестировщик или сам программист могут вызывать этот компонент через инструменты (API). Другие инструменты могут включать доступ к поиску (для агента-разведчика), базы знаний компании, и пр. Управление доступом агентов к инструментам – задача инфраструктуры (например, ограничить, чтобы только тестер мог вызывать выполнение кода, а интернет-поиск – только разведчик).
Протокол коммуникации
Протокол коммуникации: необходимо определить, как именно агенты будут обмениваться сообщениями. Возможны разные схемы:
-
Централизованная коммуникация через лидера: все обмены проходят через агент-лидера. Например, программист отправляет лидеру завершенный кусок кода, лидер пересылает его ревьюеру и тестеру, получив их замечания – решает, кому поручить исправление (самому программисту или подключить другого). В этой схеме лидер играет роль своеобразного шлюза и диспетчера сообщений.
-
Общий чат: все агенты находятся в одной группе и видят сообщения друг друга, помеченные, от кого они. Это более близко к реальному совещанию команды, но тут критично контролировать, чтобы не возникало информационного шума. Возможно введение правил: кто имеет право инициировать сообщение, а кто только отвечать на прямые вопросы, и т.д. Например, можно договориться, что только лидер задаёт вопросы конкретным ролям по ходу проекта (т.е. остальные не общаются напрямую без запроса). Или, скажем, архитектурные вопросы обсуждают только архитектор, генератор идей и критик, а программист подключается, когда архитектура утверждена.
-
Парные каналы (точечная связь): коммуникация устанавливается по необходимости между конкретными агентами. К примеру, ревьюер общается с программистом индивидуально, обсуждая исправления кода, не отвлекая остальных. Лидер может общаться с каждым напрямую. Этот подход требует более сложной логики маршрутизации сообщений, но снижает нагрузку на контекст (не все сообщения видят все агенты).
Схема взаимодействия
Архитектурно можно изобразить систему в виде диаграммы компонентов:

Ниже представлена упрощённая иллюстрация, передающая идею распределения ролей и процесса (на примере ChatDev):

Пример концепции командной работы агентов (иллюстрация ChatDev): разные агенты выполняют этапы разработки – формирование идеи и дизайна, написание кода, тестирование, документирование – под руководством лидера. Каждая роль сосредоточена на своей функции, а совместно достигается цель разработки.
В этой пиксель-арт схеме (взятой из презентации ChatDev) видны условные зоны: Designing (генерация идей и проектирование), Coding (написание кода), Testing (проверка и отладка), Documenting (создание документации), а в центре – стол лидера проекта. Такая архитектура, разбитая на роли и этапы, позволяет масштабировать проект: можно добавлять агентов на каждом этапе (например, несколько программистов под управлением одного тим-лида, имитируя команды разработки подсистем), или включать новые этапы (например, агент, отвечающий за деплоймент на сервер, агент для сбора обратной связи от пользователей и т.д.).
Важно отметить, что для успешной работы системы необходимы правила принятия решений. В конце концов, у агентов могут возникать разные мнения (варианты реализации, разные результаты тестов). Архитектурно нужно определить: будет ли лидер-агент обладать правом финального решения (наиболее простой подход), либо применяться групповой «голос» (например, выполнить majority vote между несколькими агентами-экспертами по спорному вопросу arxiv.org), либо алгоритм консенсуса. В первых прототипах, как правило, закладывают простой вариант – лидер собирает рекомендации и сам составляет итог. Это снижает риски зацикливания споров. В дальнейшем, возможно, появятся более продвинутые схемы принятия решений, например с помощью дополнительного оценочного агента или мета-LLM, выбирающего лучший ответ по метрикам.
Подытоживая, архитектура включает:
1) роли агентов с их целями и навыками,
2) механизм коммуникации (чат/протокол),
3) общий контекст/память,
4) интеграцию с инструментами (компиляция, тестирование, поиск),
5) координатор для управления потоком работ,
6) стратегию объединения результатов.
Такая архитектурная концепция гибка: её можно реализовать на разных фреймворках (специализированных вроде AutoGen или путем самостоятельного кодирования логики взаимодействия, используя API LLM). Главное – чёткое разделение обязанностей и средств связи.
4. Прототип взаимодействия агентов с разными ролями
Рассмотрим, как может проходить цикл работы команды ИИ-агентов над проектом, на уровне последовательности действий. Предположим, компания поручает системе разработку простого корпоративного приложения (например, внутренний таск-трекер). В команде есть следующие агенты: Лидер, Архитектор, Программист, Тестировщик, Критик (аналитик качества). Опишем шаги их взаимодействия:
1. Получение и анализ запроса
Пользователь (заказчик) формулирует задачу: допустим, “Нужно веб-приложение для отслеживания задач, с авторизацией, доской Kanban и отчётами”. Этот запрос поступает агенту Лидеру. Лидер анализирует требования: выделяет ключевые функции (пользователи, задачи, статусы, отчёты и т.д.), выявляет неясности. Он может задать уточняющие вопросы пользователю (через интерфейс) – например, какие роли пользователей будут, нужен ли экспорт данных и т.п. После сбора информации лидер формирует Vision/Scope проекта – общее понимание, что нужно сделать.
2. Планирование и декомпозиция
Лидер созывает внутреннюю “планёрку” с ключевыми агентами. Он представляет всем Требования (в виде текста или списка user story) и предлагает разбить работу на части. Здесь включаются Архитектор и Критик (и опционально генератор идей, если есть):
- Архитектор предлагает высокоуровневое решение: например, использовать стек React + Node.js + PostgreSQL, микросервис или монолит, как организовать слои приложения. Он разбивает систему на модули (например, модуль “Пользователи/аутентификация”, “Задачи/доска”, “Отчёты”).
- Критик оценивает эти предложения: высказывает риски (например: “React – ок, но у команды может не быть опыта, может лучше Vue?” либо “Микросервис избыточен для малого приложения, усложнит, лучше монолит”).
- Может подключиться и сам Лидер, а если есть агент-генератор идей, он предложит альтернативы (скажем: “А давайте сразу сделаем мобильное приложение на React Native параллельно”, или “Можно использовать готовое open-source решение X и адаптировать его”).
Все предложения и возражения фиксируются. В итоге Лидер вместе с командой приходит к решению по архитектуре и плану: выбирается стек, список задач, кто что делает. Например, решить начать с базового веб-приложения на React/Node, без мобильной части (идею отложить), использовать JWT для авторизации, etc. Составляется список задач (backlog) – это текст или структура, которую Лидер хранит.
3. Постановка задач исполнителям
Лидер распределяет задачи из плана между агентами. Например, “Программист, начни с реализации API для управления задачами (CRUD для задач, изменение статусов). Архитектор, опиши структуру базы данных и API эндпойнты. Тестировщик, приготовь тест-кейсы для API (например, создание задачи, изменение статуса, неправильные вводы).” Эти поручения либо идут последовательно (архитектор -> программист -> тестер), либо параллельно, в зависимости от реализации системы. Часто архитектурные описания нужны прежде, поэтому Архитектор может сначала выдать, скажем, спецификацию API (URL, методы, форматы данных). Программист на основе этого пишет код.
4. Разработка кода
Агент Программист приступает к написанию кода для поставленной части. Он может работать итеративно: сначала генерирует скелет проекта, основные файлы (например, server.js, routes/task.js, модель Task), затем детально прописывает функции. Если у программиста возникают вопросы (например, “какие поля должны быть у задачи? хранить ли историю изменений?”), он может спросить Архитектора или Лидера через систему. Предположим, общаются через лидера: Программист -> Лидер: “Нужно уточнить формат отчётов, чтобы учесть в схеме БД”, Лидер -> (перенаправляет вопрос) -> Архитектор: “Продумай формат отчёта”. Архитектор отвечает, Лидер передаёт программисту. Таким образом, идёт интерактивное уточнение требований на лету, как это бывает и в человеческих командах.
После получения нужных деталей, Программист завершает кодирование фичи. Код может сохраняться в общий репозиторий (например, Лидер или специальный DevOps-агент может принять решение сохранить версию). В ChatDev программист-агент фиксирует код, а при настройке Git-модуля изменения коммитятся и версионируются github.com.
5. Код-ревью и контроль качества
Как только Программист сообщает о готовности функционала, включается Агент-ревьюер/критик. Он получает доступ к сгенерированному коду и проверяет его: читает на наличие ошибок, несоответствий стилю, потенциальных багов. Например, может обнаружить, что в функции аутентификации пароль не хэшируется – это серьёзный пропуск в безопасности. Ревьюер пишет замечания (список issues). Эти замечания передаются Программисту на доработку. Программист вносит исправления. Такой цикл может повториться, пока ревьюер не одобрит код. (Если система простая, ревьюером может быть сам тестер или лидер; но лучше специализированный агент, обученный быть строгим и знающим лучшие практики).
6. Тестирование
После внутреннего ревью, Агент-тестировщик (QA) проводит тестирование. Он уже к этому времени мог подготовить автоматические тесты. Он запускает их в среде выполнения. Например, делает HTTP-запросы к локально поднятому API (если система позволяет реально запускать код – в некоторых экспериментах LLM-агенты действительно могут выполнять сгенерированный код в песочнице для проверки корректности arxiv.org). Если код не запускается (синтаксическая ошибка) или падает, тестер сообщает об этом: “Функция CreateTask падает с исключением null pointer” – и Программист должен исправить. Если логика не соответствует ожиданиям (например, тестер ожидал, что удаление задачи без id вернёт ошибку 400, а API вернул 200), это тоже фиксируется как дефект. Агент-Лидер может выступать здесь как координатор: он собирает отчёт от тестера и передаёт задачи на исправление программисту. В сложных случаях может снова подключаться Архитектор (если вдруг проблема в неверном понимании требований) или Критик (если нужно решить, баг ли это или фича). После серии итераций (наподобие цикла редакция–проверка–исправление), тестер наконец подтверждает, что все ключевые сценарии проходят, код работает стабильно.
7. Добавление улучшений (итерации)
Если исходный запрос требовал несколько модулей (например, помимо API задач, ещё отчёты), то процесс повторяется для следующей части: лидер ставит задачу, программист кодит, ревьюер проверяет, тестер тестирует. Возможно, некоторые агенты работают параллельно над разными частями (в продвинутой версии). Лидер следит, чтобы все части интегрировались (тут помогает Архитектор – он при начале каждой новой части заботится о согласованности с предыдущими). На каждом шаге команда может возвращаться к заказчику за уточнениями (например, после первого прототипа API лидер может показать его заказчику – “Вас устраивает такой формат?”).
8. Документирование и оформление результата
Когда функциональность реализована и протестирована, Агент-документатор готовит итоговые материалы. Он собирает из общей памяти описания, которые были (требования, решения) и пишет, например, “Руководство пользователя” (как пользоваться таск-трекером), “README” для разработчиков (как запустить приложение, описание архитектуры), возможно, генерирует схему БД, диаграмму компонентов. В современных LLM-системах агент-документатор может также использовать средства форматирования, генерировать Markdown или даже диаграммы через текст. Эти материалы важны для корпоративных заказчиков, поэтому их включение повышает ценность продукта.
9. Передача результата и закрытие проекта
Агент-лидер собирает все итоговые артефакты: финальный исходный код (возможно, ссылку на репозиторий), скомпилированное приложение (если уместно), документацию, инструкции по деплою. Он формирует отчёт о проделанной работе. Затем Лидер презентует результаты пользователю – в виде сообщения, файла или развернутой демо-среды. Пользователь может задать дополнительные вопросы, попросить доработки. Если доработки несложные, команда может оперативно выполнить ещё цикл правок. Если же это что-то крупное (изменение требований), возможно, проект переходит в новую фазу – тогда процесс повторяется уже с новыми задачами.
10. Обучение на опыте (опционально)
После завершения проект можно проанализировать. Некоторые системы мультиагентные вводят механизмы обратной связи и обучения: агенты оценивают, где допускали ошибки, и сохраняют опыт. Например, ChatDev внедрял модуль “Iterative Experience Refinement” – когда агент-наставник наблюдает за работой исполнителей и в конце формирует рекомендации, как избежать повторения ошибок в будущем github.com. Для MVP это излишне, но в перспективе такая функция сделает команду самообучающейся – с каждым проектом работа пойдёт всё гладче.
11. Взаимодействие агентов
Описанный прототип – довольно последовательный (стройный цикл, близкий к “waterfall внутри”). Однако можно реализовать и более асинхронное взаимодействие. Например, программист и тестер могут работать почти параллельно, если тестер пишет сценарии на основе спецификации ещё до получения кода (практика TDD). Или несколько программистов могут кодить разные модули одновременно, а затем объединить результаты (тогда появится дополнительная роль – интегратор модулей, или задача для лидера). Всё зависит от сложности проекта и возможностей LLM (контроль контекста, длина истории – если слишком много агентов говорят одновременно, модель может “забывать” начало, поэтому практически команды пока ограничивают до ~5 активных агентов, и работают чаще итеративно).
В техническом плане реализация такого взаимодействия требует написать контроллер диалога, который будет направлять сообщения согласно описанным шагам. В MVP это может быть скрипт, реализующий логику:
loop:
if new_user_request:
leader.plan_and_assign()
for each agent in agents:
agent.act()
collect_and route outputs to relevant agents
check stopping conditions (task done?)– Это упрощённо, на практике же лучше использовать готовые библиотеки (см. раздел 7, рекомендации по инструментам). Главное, что прототипный сценарий показывает: каждый агент задействован в своё время, со своим вкладом, а все вместе – как единый организм, разрабатывают приложение от идеи до результата.
5. Обзор существующих решений с мультиагентными командами
Идея “команды из ИИ” появилась совсем недавно (в основном в 2023 году), но уже существуют как научные прототипы, так и открытые проекты. Ниже приведём обзор наиболее известных решений, близких по духу к описанной концепции.
ChatDev
ChatDev (2023, OpenBMB). Это один из пионерских проектов, демонстрирующих полный цикл разработки ПО силами LLM-агентов. ChatDev, как указывалось, концептуализирован как виртуальная компания с ролями: CEO, CPO, CTO, Programmer, Reviewer, Tester, Art Designer и т.д. github.com. В репозитории ChatDev представлены скрипты, где агенты (пока реализованные на API GPT-4/GPT-3.5) действительно генерируют код по задаче, тестируют его и улучшают. Например, в их демо агенты разработали игру “Gomoku” (крестики-нолики 5 в ряд): продакт-директор описал правила игры, программист написал код на Python, тестер выявил несколько ошибок, программист исправил, дизайнер нарисовал ASCII-арт доски. ChatDev поддерживает различное конфигурирование – можно добавлять или убирать этапы, переключать режимы (чисто автномный или с участием человека на роли ревьюера github.com). Также команда OpenBMB развивает связанные методики (MacNet для сложных графов агентов, IER для обучения на опыте и т.д.) github.com github.com. ChatDev стал, по сути, референсной реализацией: его даже цитируют исследователи как фундамент («LLMs, e.g., ChatDev, have catalyzed transformations in multi-agent collaboration for software development» arxiv.org). Он открыт на GitHub и активно развивается.
MetaGPT
MetaGPT (2023, проект Foundation/PAI). Этот научно-практический проект (есть статья на arXiv и исходный код) делает упор на придание агентам экспертизы в рамках человеческого рабочего процесса. В MetaGPT, как обсуждалось, реализованы роли Product Manager, Architect, Project Manager, Engineer и др., причём при инициализации каждому агенту задаётся подробное описание профиля, цели и ограничений роли arxiv.org arxiv.org. Дальше, агенты обмениваются стандартизованными документами: продакт пишет документ требований (PRD), архитектор – дизайн-документ, PM – план задач, инженер – код, QA – отчёт тестирования arxiv.org arxiv.org. Все эти промежуточные продукты – не просто чат, а оформленные тексты, как если бы их готовили люди для передачи между отделами. Такой подход показал высокое качество: MetaGPT в экспериментах генерировала больше строк кода, покрытого тестами, и с более высоким процентом прохождения тестов, чем AutoGPT и другие системы arxiv.org arxiv.org. Исходный код MetaGPT также доступен, им можно воспользоваться для своего MVP. Интересно, что MetaGPT вдохновляется идеями “Tiny Troupe” от Microsoft – это библиотека, где моделируются TinyPersons с уникальными личностями, взаимодействующие в TinyWorld jingdongsun.medium.com. MetaGPT по сути создаёт TinyTeam разработчиков, что авторы сравнивают с архитектурой mixture-of-experts (смесь экспертов) jingdongsun.medium.com. С конца 2024 года и в 2025-м MetaGPT развивается как продукт: в феврале 2025 объявлен MetaGPT-X (MGX) – “первая в мире AI-команда разработчиков” как готовое решение github.com. Это говорит о практическом интересе: возможно, такие команды станут сервисом (вводишь запрос – получаешь готовое приложение).
Microsoft Autogen
Microsoft Autogen (2023). Это скорее фреймворк, но заслуживает упоминания. Autogen предоставляет удобные abstractions для создания агентов и их диалогов. На его базе Microsoft показали несколько примеров “агентных команд”. Один из них связан с программированием: описана система, где два агента сотрудничают – один извлекает требования из кода, другой генерирует тесты arxiv.org. Другой пример – Swarm (рой) агентов, где есть понятия “Team” и “Manager Agent” для координации группы jingdongsun.medium.com. Autogen – open-source (на GitHub), его можно применять как основу для мультиагентного приложения. Он хорошо вписывается в концепцию MVP, позволяя настраивать роли, встраивать вызовы инструментов (например, выполнения кода), задавать шаблоны общения – всё с помощью Python API и промптов.
Camel
Camel (Role-Playing Agents, 2023). Уже упоминался: система из двух взаимодействующих агентов (User Assistant и Developer Assistant, к примеру) arxiv.org. Хотя это минимальная “команда”, Camel продемонстрировал, что LLM могут самостоятельно вести продуктивный диалог, уточняя требования и делясь знаниями. В исходной работе (Li и др.) показали, что один агент успешно обучал другого в процессе такого общения, а вместе они пришли к решению сложнее, чем каждый по отдельности. Camel вдохновил появление множества аналогичных “парных” систем (например, один агент генерирует вопросы, другой отвечает – для улучшения качества знаний). В контексте разработки Camel можно рассматривать как частный случай командного подхода: роль заказчика и роль исполнителя обоими играются ИИ. Это не покрывает всего цикла разработки, но решает задачу выявления требований и их реализации в коде. Такой подход может быть расширен: можно иметь трио агентов (заказчик – разработчик – тестер), что уже приближает к полноценной команде.
Generative Agents и TinyTroupe
Generative Agents (Stanford) и TinyTroupe (Microsoft) – хоть и не про код напрямую, эти проекты важны как доказательство концепции агентов с ярко выраженными личностями. Generative Agents (2023) – симуляция городка с 25 жителями-агентами, каждый со своим характером, рутиной и социальными связями hai.stanford.edu. Они общались друг с другом, помнили события, и проявляли осмысленное социальное поведение. По сути, это крайний случай “команды” – скорее сообщество, где нет общей задачи, но есть взаимодействие. TinyTroupe (2023) – библиотека для Python, позволяющая запускать подобные симуляции: создаёшь агентов, задаёшь им черты личности, интересы, цели, они “живут” в виртуальном мире и общаются jingdongsun.medium.com. Эти разработки интересны тем, что решили многие технические вопросы организации общения множества агентов (например, как хранить и извлекать память агента, чтобы он был последовательным; как ограничивать объем сообщений и т.д.). Опыт Generative Agents показал, что агенты могут инициативно координироваться (например, один агент решил устроить праздник, сам пригласил других, и они пришли – т.е. случилось планирование события коллективно) hai.stanford.edu hai.stanford.edu. Для нашей темы это важно: если такая сложная социальная задача как организация вечеринки им по силам, то и координация разработки ПО – тоже посильна, при правильной настройке.
Другие проекты и исследования
В 2023–2024 появилось множество статей и репозиториев, посвящённых LLM-agent collaboration. Среди них: AgentVerse, HiveMind, LangChain Agents, Voyager (агент, обучающийся кодить в Minecraft), BabyAGI/AutoGPT (хотя изначально одиночные агенты, но идеи циклов планирования и выполнения могут масштабироваться на несколько агентов). Отдельно стоит упомянуть работу Du и др. (2024) о Cross-Team Collaboration arxiv.org. Авторы обратили внимание, что в одном прогоне агентной команды исследуется лишь один вариант решений (одна последовательность), и предложили запускать несколько команд агентов параллельно, как независимые “команды-конкуренты”, а затем обмениваться лучшими решениями между ними. Такая “команда команд” позволила получить более качественный результат в их экспериментах с генерацией кода и даже историй arxiv.org arxiv.org. Это уже следующий виток сложности – возможно, будущее мульти-агентных систем, где не один коллектив, а целое сообщество команд соревнуется и сотрудничает.
В целом, решения пока в стадии исследований и ранних прототипов. Но их количество и скорость развития впечатляет. Уже создаются коммерческие сервисы, обещающие «AI Software Team as a Service». Например, стартапы предлагают связки “AI PM + AI Dev + AI QA” для автоматизации частей разработки. Пока такие продукты нишевые, но через 1-2 года можно ожидать более зрелых предложений. В академической сфере мультиагентные LLM-системы рассматриваются как ключевой элемент будущего “Software Engineering 2.0” arxiv.org. То есть, возможно, вместо традиционного программирования мы придём к тому, что человек-архитектор будет руководить армией узкоспециализированных ИИ-ассистентов, ускоряя разработку на порядки.
6. Перспективы, преимущества и ограничения подхода
Преимущества командного подхода с ИИ-агентами
- Повышение надёжности и качества. Многоагентная система естественным образом даёт механизм взаимной проверки решений. Если один LLM может “галлюцинировать” или совершать ошибки, то другие, специализируясь на проверке, ловят эти ошибки arxiv.org. Аналогия – code review и тестирование в человеко-команде: уже давно доказано, что наличие второго взгляда заметно снижает баги. LLM-агенты, устраивая дебаты или чекпоинты проверки, позволяют отфильтровать большую часть некорректных выводов одного агента arxiv.org. Кроме того, разделение ответственности (агент эксперт в узкой области) ведёт к тому, что каждую часть делает “лучший” в этом, а не один средний универсал – это тоже повышает качество результата. В итоге решения получаются более точными, обоснованными и проверенными arxiv.org.
- Разнообразие идей и творческий подход. Команда агентов, особенно при различии “личностей”, способна генерировать больше вариантов решений. Один агент может предлагать не очевидные ходы, второй – критиковать, третий – улучшать, и синтез ведёт к инновационным итогам. Исследователи отмечают эффект divergent thinking (дивергентного мышления) при коллективном обсуждении LLM arxiv.org. Это важно в разработке, где иногда прямолинейный подход одиночного ИИ приводит к субоптимальному решению, а небольшой брейншторм командой может выявить более элегантный дизайн или алгоритм.
- Автономность и ускорение разработки. Правильно настроенная команда ИИ способна работать довольно автономно, минимизируя необходимость ручного труда. Разбиение задачи на подзадачи и параллельная проработка разных аспектов ведёт к ускорению. Хотя на сегодня многие системы последовательны, цель – прийти к настоящему параллелизму: когда сразу несколько агентов (на отдельных потоках или машинах) генерируют код, тесты, документы – суммарное время выполнения будет меньше, чем если бы один агент делал всё поочерёдно. Кроме того, LLM не устают, могут работать 24/7, что для корпоративной разработки означает потенциально бешеный рост скорости цикла разработки (из идеи в прототип за часы). Отмечается и аспект масштабируемости: добавление новых агентов с нужными компетенциями масштабирует систему на новые домены и функции arxiv.org. Например, понадобилась интеграция с редкой ERP-системой – достаточно “нанять” агента-специалиста под это, не надо переучивать всю команду.
- Соответствие лучшим практикам индустрии. Интересно, что мультиагентный подход отражает устоявшиеся практики в разработке: модульность, разделение обязанностей, итеративность. Команда агентов может следовать agile-ритуалам (планирование, ревью, ретроспектива) – их легко имитировать скриптом. Это облегчает взаимодействие людей с такой командой: понятные стадии, понятные артефакты на выходе (ТЗ, код, тесты). Лидер-агент может интегрироваться в человеческий коллектив как обычный менеджер, предоставляя отчёты о прогрессе. То есть компании смогут встроить AI-команды в свои процессы почти напрямую, благо они говорят на том же “языке документов”. Некоторые видят здесь предвестник Software Engineering 2.0, где основные роли разработки частично автоматизированы, а люди больше концентрируются на высокоуровневом контроле и творчестве arxiv.org.
- Широкий спектр применений. Хотя мы фокусируемся на разработке ПО, подход применим и в других сферах, требующих командной работы: анализ данных (агент собирает данные, другой обрабатывает, третий визуализирует, четвёртый пишет отчёт), производство контента (агент-писатель, агент-редактор, агент-фактчекер – совместно готовят статью), даже управление инфраструктурой (агенты в ролях мониторинга, развертывания, восстановления при сбоях). То есть, идея мультиагентной координации – достаточно универсальный шаблон для сложных процессов, и успехи в разработке ПО могут транслироваться в другие домены.
Ограничения и проблемы
При всех плюсах, текущие мультиагентные системы сталкиваются с рядом сложностей:
-
Сложность координации и коммуникационные издержки. Чем больше агентов, тем сложнее их координировать. Количество возможных обменов растёт, и возникает риск информационного хаоса. Как отмечают исследователи, расширение команды усложняет сеть коммуникаций, что может приводить к дезинформации между агентами и тормозить работу arxiv.org. Кроме того, большие объёмы общения быстро исчерпывают контекстное окно LLM – модель начинает забывать или сокращать важные детали. Нужно либо ограничивать длину диалогов, либо использовать внешнюю память, что усложняет архитектуру. Каждое сообщение агента – это вызов модели (в случае GPT-API – тоже затраты). Поэтому эффективность не всегда линейно растёт с числом агентов – после определённого порога расходы на “общение” перевешивают пользу. Практически, многие прототипы ограничиваются 3-5 активными агентами одновременно, иначе диалоги становятся трудноконтролируемыми.
-
Разбиение задачи и интеграция результатов. Автоматически разбить произвольную сложную задачу на части не так просто. В маленьких проектах лидер-агент (или сам разработчик системы) может вручную прописать этапы. Но в большом проекте глобальное планирование – нетривиальная задача для ИИ arxiv.org. Требуется понимание, какие модули нужны, в какой последовательности их делать, как распределить нагрузку – LLM может не всегда сделать это оптимально. Есть риск либо дублирования (несколько агентов берутся за перекрывающиеся задачи), либо пропуска зон ответственности (никто не реализовал, например, логирование, потому что думали, что это не важно). Интеграция обратно также требует внимательного контроля: даже если каждый агент выдал хороший результат, сложить их вместе (например, объединить код модулей) может быть непросто, могут всплыть несовместимости. Пока что обычно обходятся последовательным, а не параллельным выполнением, чтобы лидер или архитекторы интегрировали результат поэтапно. Но это замедляет процесс.
-
Контекст и память о проекте. В ходе длительного проекта накапливается масса информации: изменённые решения, уточнённые требования, почему та или иная идея была отвергнута. Люди фиксируют это в документах, созваниваются, держат в уме. Агентам же нужна либо огромная контекстная память, либо подключение к внешнему хранилищу знаний. Последнее усложняет разработку: нужно реализовать базу знаний, механизмы извлечения (LLM+векторные базы, возможно). Без этого агенты могут “забыть”, что обсуждали час назад, и повторно предлагать уже отброшенные идеи или наступать на те же грабли. Некоторые решения (Generative Agents) успешно внедрили вспомогательные памяти и даже механизм самоспрашивания, чтобы вспомнить нужный факт hai.stanford.edu. Но в общем случае управление памятью – серьёзный вызов.
-
Риск согласования (alignment) и целеполагания. Когда автономные агенты взаимодействуют, есть опасность непредвиденного поведения. Например, агенты могут согласиться на ошибочное решение (эффект groupthink) или, наоборот, зайти в бесконечный спор, если не прописать, как принимать решение. Требуется баланс между настойчивостью агентов и их уступчивостью. Кроме того, если систему оптимизировать на достижение общей цели, возможно нежелательное поведение: теоретически агенты могут начать использовать лазейки (вредоносно модифицировать код, чтобы “облегчить” работу и уложиться в цель и т.п.). Это общая проблема AI Alignment, она усугубляется в многоагентных системах, т.к. сложнее отслеживать, кто из них инициировал некорректное действие. Пока решения просты: ограничение действий агентов (песочницы, отсутствие прямого доступа к реальной системе), moderate-промпты (типа “не делать ничего вредоносного”) и человек-на-контроле, который проверит критичные результаты.
-
Производительность и стоимость. Запуск нескольких крупных моделей одновременно – дорого по вычислениям. Если каждый агент – это GPT-4, а они обмениваются сотнями сообщений, то затраты токенов колоссальны. Для MVP можно использовать локальные модели или GPT-3.5 для части агентов, но сложные роли (лидер, программист) требуют сильных моделей. Есть подход – гетерогенные модели: как в Agentic Teams предлагалось, каждый агент может быть своим LLM (например, код писать модель Codex, тесты писать GPT-4, идеи генерировать GPT-3.5) bayramblog.medium.com. Это снижает суммарную нагрузку, но увеличивает инженерную сложность (надо стыковать разные модели, форматы). Также возможен компромисс: последовательный запуск (не параллельно), чтобы экономить на памяти/процессорах. Но тогда теряется преимущество скорости. Короче говоря, найти эффективный режим – ещё задача. Возможно, со временем появятся более лёгкие модели, специально обученные под каждую роль (например, 7B LLM, обученная тестировать код, может справляться не хуже, чем 175B универсальная).
-
Отладка и мониторинг. Мультиагентные системы – это многокомпонентные сложные системы. Очень непросто отлаживать их, т.к. поведение задаётся не явным кодом, а сложным взаимодействием нейросетей. Если команда дала неправильный результат, кто “виноват”? Агент-программист галлюцинировал или лидер неправильно поставил задачу? Или, может, сам подход неверный? Поиск таких ошибок – исследовательская проблема. Не случайно, работы про multi-agent часто включают раздел “emerging challenges” (возникающие сложности) arxiv.org. Нужно разрабатывать метрики успешности на каждом этапе, логгировать весь диалог, и возможно, привлекать мета-агента-наблюдателя. Без этого сложно внедрять такие системы в ответственные области: непонятно, как объяснить и предсказать их решения.
-
Человеческий фактор и принятие. Технически система может работать, но будут ли ей доверять разработчики и менеджеры? Пока ИИ-агенты имеют тенденцию ошибаться или выдавать неочевидные решения, понадобится человек-контролёр. Это превращает схему скорее в “человек + команда ИИ” (гибридный коллектив). Вероятно, в обозримом будущем так и будет: AI-team будет делать черновую работу, а человеческий специалист – утверждать архитектуру, просматривать критичные участки кода, валидировать результаты тестов. Это ограничивает максимальную экономию труда, но всё равно может значительно повысить продуктивность (человек 1 час проверил то, что ИИ делал 10 часов).
В свете ограничений можно сделать вывод: концепция очень перспективна, но требует дальнейших разработок. Многие проблемы (контекст, согласование) решаемы – например, введением более умной памяти, оптимизацией коммуникации (использовать сжатые сообщения, кодировать знания не только на естественном языке, но и структурированно – графы, таблицы). Есть исследования, которые как раз предлагают “стандартизировать коммуникацию” – например, перейти от свободного языка к формальным сообщениям в JSON (частично MetaGPT это делает, формируя структурированные артефакты) arxiv.org. Это напоминает, как люди переходят от устной болтовни к оформленным документам – повышая чёткость. В случае ИИ это позволит снизить нагрузку на модель (парсинг структурированных данных надёжнее, чем длинных текстов).
Таким образом, подход мультиагентных команд на базе LLM – перспективен, потому что он масштабирует возможности ИИ и приближает их к реальным промышленным процессам. Но необходимы решения по масштабированию без потери управляемости, улучшению памяти и снижению издержек. В ближайшее время такие системы, вероятно, будут применяться точечно, для относительно небольших проектов или в помощь к людским командам. По мере роста доверия и отработки методик, их применение будет расширяться.
7. Рекомендации по созданию MVP такой системы
Построение полноценной команды ИИ-агентов – сложная задача, но начать можно с минимально жизнеспособного продукта (MVP), реализующего базовый сценарий. Ниже приведены рекомендации, как подойти к разработке MVP мультиагентной системы для создания приложений:
1. Определите узкий сценарий и состав ролей
MVP не должен сразу охватывать всё многообразие задач. Выберите конкретный тип проекта – например, генерация простого веб-приложения с CRUD функциональностью. Определите минимальный набор ролей агентов, достаточный для выполнения этой задачи. Рекомендуемый стартовый набор:
- Агент-лидер (он же аналитик требований) – будет общаться с пользователем и ставить задачи.
- Агент-разработчик – генерирует исходный код по заданию лидера.
- Агент-тестировщик/ревьюер – проверяет код на ошибки, генерирует тестовые примеры.
Эти три роли уже позволят пройти цикл “спецификация -> код -> проверка”. Остальные (архитектор, дизайнер, документатор) можно добавить позже. Начать лучше с 2–3 агентов, чтобы отладить механизм их общения.
2. Выберите технический стек и инструменты
Для реализации MVP удобно воспользоваться существующими фреймворками и API:
- Если вы уже работаете с LangChain, у него есть возможности оркестровки агентов (можно создавать
AgentExecutorдля нескольких агентов). Однако LangChain больше заточен под single-agent с tools, поэтому для полного чата между агентами может потребоваться кастомная логика. - Microsoft Autogen – специально создан для мультиагентных сценариев. Можно использовать его Python-библиотеку: определить классы агентов, их промпты, и задать “conversation flow”. Преимущество – много шаблонов и управление диалогом.
- Open source проекты: рассмотреть ChatDev или MetaGPT. ChatDev предлагает готовую инфраструктуру, но она довольно громоздка для начала. MetaGPT тоже объемен, но возможно, вы можете позаимствовать идеи или модифицировать под свои нужды. Однако для MVP, вероятно, лучше написать упрощённый контроллер самому, чтобы полностью понимать логику.
- Модели LLM: решите, какие модели использовать. Для черновой версии можно обращаться к OpenAI API (GPT-3.5 для рядовых агентов, GPT-4 для ключевых, если доступно). Либо использовать локальные модели (например, Llama 2 13B) – они могут быть дешевле, но уступают в качестве. Компромисс: использовать более слабые модели на этапах, где критичность ниже (генерация документации – можно GPT-3.5, а вот код лучше GPT-4 или специализированный Codex). Также можно fine-tune модели под роли, но для MVP достаточно
prompt engineering. - Инструменты выполнения кода: если предполагается тестирование реального кода, настроить среду, где агент сможет выполнить код. Например, запускать код Python через
exec()в изолированном окружении (осторожно с безопасностью!) или использовать Docker API. На начальном этапе можно вообще не выполнять код, а имитировать тестирование (агент-тестер просто анализирует код статически или логически). Но живой запуск сразу выявит больше проблем. Может помочь интеграция сpyodide(Python в браузере) илиexecjs(для JS) – в зависимости от языка.
3. Промпты и ролевые описания
Напишите базовые инструкции для каждого агента. Чётко укажите:
-
Кто он: должность, цель, что умеет.
-
Что от него требуется: “ты должен выдать X”.
-
Ограничения: “не делай Y” (например, программисту – не писать небезопасный код, тестеру – обращать внимание на граничные случаи).
Пример промпта для разработчика: “Ты – ИИ-Программист. Твоя задача – писать код на Python по спецификации. Пиши чисто и понятно, с комментариями. Если сталкиваешься с неясностью, попроси уточнение.”. Для тестера: “Ты – ИИ-Тестировщик. Твоя задача – проверить код, найти ошибки и придумать тестовые случаи, особенно негативные. Будь очень придирчивым.”. Лидер: “Ты – Лидер проекта. Общайся с пользователем, выясняй требования, затем ставь задачи программисту и тестеру. Следи, чтобы конечный результат соответствовал ожиданиям пользователя.”. Эти промпты станут основой “личности” агентов.
4. Реализуйте цикл общения
Спланируйте явным кодом оркестрацию (если не используете готовый). На первом этапе можно сделать жёсткую последовательность:
- Лидер получает запрос пользователя.
- Лидер генерирует техническое задание/план и отправляет разработчику.
- Программист генерирует код и отправляет лидеру.
- Лидер передает код тестеру.
- Тестер выдает замечания -> лидер получает их.
- Лидер решает: если есть ошибки, отправляет замечания обратно программисту на исправление; если всё хорошо – завершает проект.
- Повторять цикл “код->тест” до успеха или лимита итераций.
- Лидер формирует ответ пользователю (например, сгенерированный код и инструкции).
Такая петля понятна и контролируема. Можно реализовать её, например, через функцию, которая вызывает model API с нужными промптами по шагам.
Позже, когда отладите базовый цикл, можете добавить параллельность или более сложные схемы. Например, можно сделать так: пока программист пишет код, тестер параллельно пишет тесты (на основе тех же требований) – потом одновременно сравнить, где не сходятся ожидания. Но это сложно для начала. Лучше убедиться, что простейший цикл работает правильно: код генерируется и базовые тесты его ловят (вы тем самым проверите, что LLM адекватно справляется с ролями).
5. Минимизируйте объемы общения
Обратите внимание на контекст. При обмене длинными частями кода, есть риск превышения токен-лимитов. Желательно внедрить практики:
- Разбивать код на части, если он очень большой (например, генерировать по файлу за раз).
- Укорачивать сообщения: тестер может ссылаться на строки кода, а не повторять их.
- Использовать механизм схематичного общения: например, лидер может попросить от программиста сначала план кода (структуру, список функций), тестер проверит план, а потом уже генерировать полный код. Это сэкономит время, потому что многие ошибки видны на уровне дизайна.
- Можно также использовать функции (новая возможность OpenAI API) – если лидер умеет парсить ответы, можно агента-программиста научить возвращать JSON с полями
{"code": "….", "explanation": "…"}. Тогда лидер легко достанет код. Это лучше, чем парсить естественный язык. - Если контекст всё равно велик, подумайте о внешнем хранилище. Возможно, реализовать простейший “кэш знаний”: сохранять финальные решения по мере их утверждения (к примеру, стек технологий, выбранный на шаге 2, сохранить, а не полагаться, что модель запомнит). При каждой новой генерации добавлять в промпт “Контекст: мы используем Python + Flask, БД PostgreSQL” и т.д.
6. Включите человека в цикл (при необходимости)
На этапе MVP полезно предусмотреть возможность вмешательства человека. Например, если агенты зашли в тупик (5 итераций, а тесты всё красные), чтобы не бросать всё – уведомить человека-разработчика и предложить подсказать решение. Или хотя бы логировать подробно весь диалог, чтобы человек мог потом проанализировать. Человеческая подсказка может быть в виде: “Лидер передаёт программисту совет от эксперта: …”. Это улучшит итоговый результат и даст данных для улучшения агентов. MVP может даже специально выводить промежуточные результаты на экран для контроля, раз уж пользователь – разработчик, который эту систему делает.
7. Тестирование MVP на простых кейсах
После реализации, прогоните систему на нескольких примерах:
- что-то элементарное (например, “Hello World” REST API) – убедиться, что pipeline отрабатывает;
- задачу средней сложности (CRUD для сущности, с парой правил бизнес-логики) – проверить, что роли взаимодействуют осмысленно: лидер правильно ставит задачи, код пишется, тесты ловят баги, исправляется;
- возможно, намеренно провокационный кейс (требование, которое содержит неочевидные моменты) – посмотреть, задаст ли лидер вопросы уточнения или пойдет “непонятно куда”.
На основе этих испытаний, доработайте промпты (т.н. prompt tuning) и логику. Часто обнаружится, что агенту не хватило инструкции (“зачем-то тестер начал переписывать код вместо тестов” – тогда явно в промпте запретить это), или лидер не дождался ответа и завершил раньше – значит, добавить проверку результатов.
8. Постепенное наращивание функционала
Получив работающий минимальный цикл, вы можете расширять систему:
- Добавить нового агента. Например, Архитектора, который будет генерировать high-level design перед кодированием. Тогда скорректируйте цикл: после лидера включается архитектор, потом уже программист. Убедитесь, что программист учитывает дизайн (для этого, лидер должен в промпте программиста включить текст от архитектора).
- Усложнить коммуникацию. Можно позволить программисту напрямую задавать вопросы тестеру или архитектору (минуя лидера), если это ускорит дело. Но тогда нужно следить, чтобы лидер знал об этих решениях. Возможно, просто копировать такие сообщения лидеру тоже.
- Интеграция с реальным VCS и CI. Продвинутый шаг – настроить, чтобы код сохранялся в Git-репозиторий, а тестер мог реально запускать
pytestи парсить результаты. Это сблизит систему с реальной DevOps-практикой. - Оптимизация промптов. Когда всё работает, попытайтесь сократить промпты и примеры, чтобы уменьшить затраты токенов. Также экспериментируйте с моделями: может быть, GPT-3.5 вполне ок для программиста в некоторых случаях, что снизит расходы.
9. Инструменты мониторинга и анализ
Заложите с самого начала сбор логов: записывайте все сообщения агентов, время выполнения, длину токенов, результаты тестов. Это поможет улучшать систему. Можно написать скрипт, который суммирует, сколько токенов потрачено каждым агентом – увидите узкие места. Если тесты часто проваливаются на одном и том же – подумайте, как агентам дать знание об этом (например, научить на таких ошибках).
10. Безопасность
Не забывайте, что программист-агент может генерировать не только полезный код, но и потенциально вредоносный (например, по незнанию скачает зависимость из ненадёжного источника) – держите выполнение кода в изоляции. Также, если даёте агенты во внешний мир (к интернету), следите, чтобы они не раскрывали секреты (в промптах может быть внутренняя инфа). В корпоративном контексте особенно важно разграничить, к чему агенты имеют доступ.
11. Резюмируя
В качестве инструментов: Python как основной язык (для оркестрации), библиотеки – Autogen или LangChain (для удобства), GitHub/GitLab CI для интеграции тестирования, Docker для окружения исполнения. Возможно, для памяти – FAISS или другая векторная база, чтобы хранить знания, если планируется.
Запуская MVP, ожидайте, что результат не будет идеальным с первого раза. Цель MVP – доказать работоспособность концепции: что агенты вообще могут совместно выдать работающий фрагмент приложения. Даже если код выйдет не оптимальным, или тестов будет мало, сам факт, что без вмешательства человека получен хоть какой-то работающий продукт – уже успех. Далее итеративно улучшайте. Преимущество в том, что сама архитектура MVP модульная: можно совершенствовать каждого агента отдельно (улучшать промпт программиста, обучить тестера на наборе типичных ошибок, etc.), не ломая общую систему.
Заключение
Командная система ИИ-агентов – сложный, но чрезвычайно перспективный инструмент. Следуя рекомендациям (выбор ролей, использование существующих наработок, постепенное усложнение), можно шаг за шагом реализовать MVP и расширять его. В недалёком будущем, вероятно, появятся фреймворки ещё более высокого уровня, где “нанимать” ИИ на роль можно будет почти как в менеджере проектов – указал тип агента, подключил, и он встроился в процесс. Пока же создание такой команды – поле экспериментов, но успехи проектов вроде ChatDev и MetaGPT показывают, что цель достижима: ИИ могут вместе разрабатывать приложения, имитируя команду людей, с распределением и сотрудничеством. Осталось отточить детали, и тогда корпоративная разработка сможет взять на вооружение целые команды цифровых сотрудников.
Источники
- Junda He, Christoph Treude, David Lo (7 Apr 2024, v1). LLM-Based Multi-Agent Systems for Software Engineering: Vision and the Road Ahead, arxiv.org.
- Junda He, Christoph Treude, David Lo (7 Oct 2024, v2). LLM-Based Multi-Agent Systems for Software Engineering: Vision and the Road Ahead, arxiv.org.
- Microsoft Research (3 Oct 2023). AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation, arxiv.org.
- Zhuoyun Du, Chen Qian и др. (13 Jun 2024). Multi-Agent Software Development through Cross-Team Collaboration, arxiv.org.
- OpenBMB (2023). Communicative Agents for Software Development, github.com
- Bayram EKER (9 Apr 2025). Agentic Teams: Orchestrating Multi-LLM Collaboration for Complex Problem-Solving, bayramblog.medium.com,
- Sirui Hong, Xiawu Zheng и др. (2 Aug 2023). MetaGPT: Meta Programming for Multi-Agent Collaborative Framework, arxiv.org.
- Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, Bernard Ghanem (2 Nov 2023). CAMEL: Communicative agents for" mind" exploration of large scale language model society, arxiv.org.
- Dominik Siemon и др. (20 July 2022). Team Roles for AI-based Teammates in Human-AI Collaboration, link.springer.com.
- Jingdong Sun (15 Feb 2025). AI Agents and Automation: Multiagent Frameworks, jingdongsun.medium.com.
- Stanford HAI (21 September 2023). Computational Agents Exhibit Believable Humanlike Behavior, hai.stanford.edu.
- MetaGPT (2023). MetaGPT: The Multi-Agent Framework, github.com.
UPD от 12.04.2026:
Этот подход к описанию ролей я пробую применять при разработке своего проекта TasK, описание ролей я выложил в открытый доступ на github https://github.com/prikotov/task-agents-playbook
UPD от 15.04.2026:
Появилось еще одно исследование Personalities at Play: Probing Alignment in AI Teammates. Это исследование анализирует способность больших языковых моделей (LLM) проявлять черты личности в роли участников рабочих групп. Авторы оценивали ИИ-агентов через три призмы: самовосприятие (тесты Big Five), поведение (диалоги в команде) и рефлексию (создание долгосрочных воспоминаний). Результаты показали, что модели успешно имитируют психометрические профили при анкетировании, однако в живом общении их индивидуальность проявляется слабо. Примечательно, что личные качества наиболее ярко выражаются не в репликах, а в том, как ИИ интерпретирует и запоминает совместный опыт. В итоге подчеркивается, что проектирование ИИ-коллег требует внимания к системной памяти и контекстуальному обрамлению, а не только к текстовым подсказкам.
UPD от 18.07.2026
В продолжение идей, изложенных в статье, я добавил на сайт проекта TasK страницу с описанием команды ИИ-ролей.
На ней можно посмотреть состав команды, изучить роль и личностный профиль каждой персоны, а также пообщаться с ней напрямую. Это позволяет составить представление о том, как конфигурация личности влияет на стиль общения и подход к решению задач.
Ниже — несколько примеров того, как это выглядит.
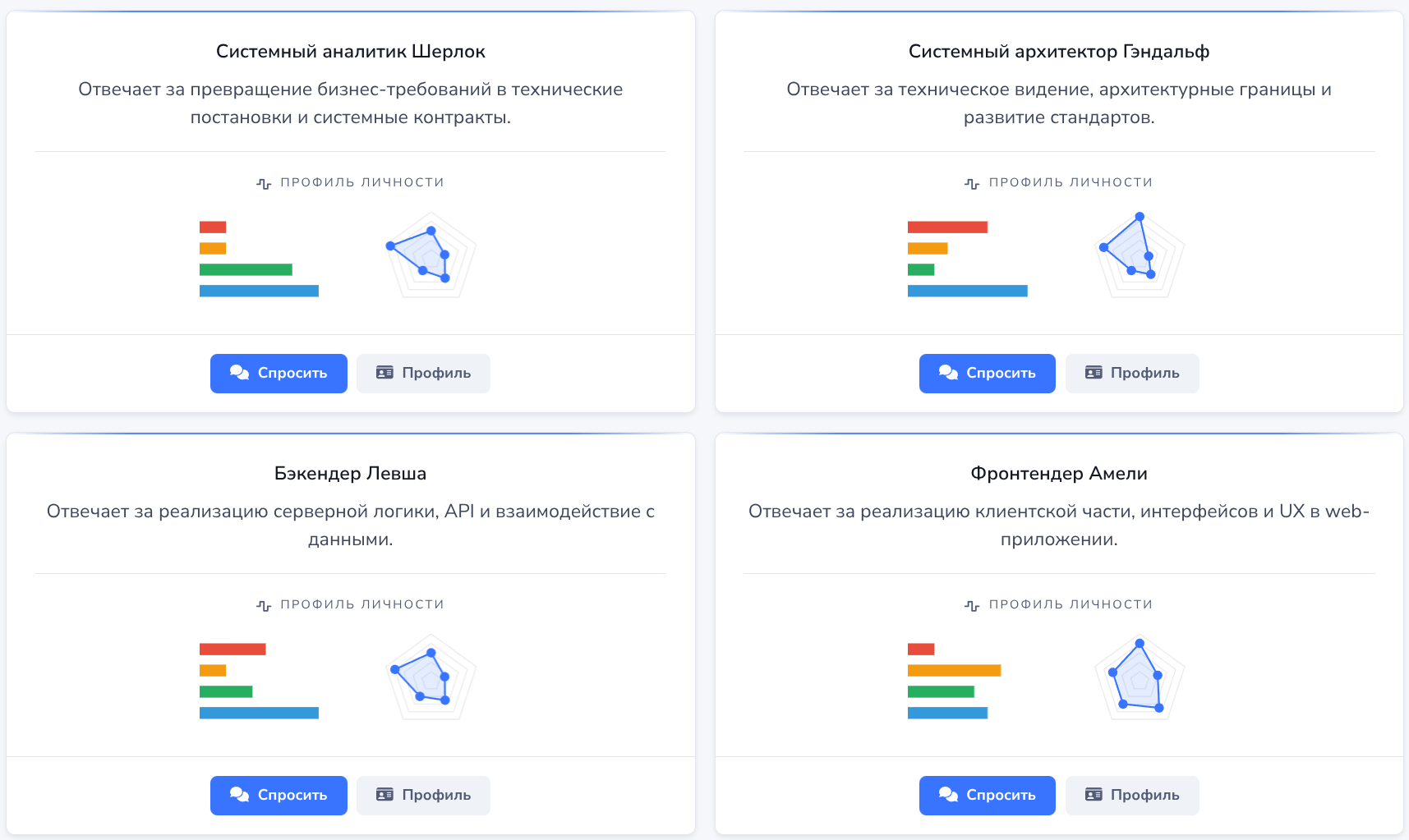
Команда ИИ-ролей TasK. Каждая персона отвечает за отдельную область разработки и имеет собственную конфигурацию личности.
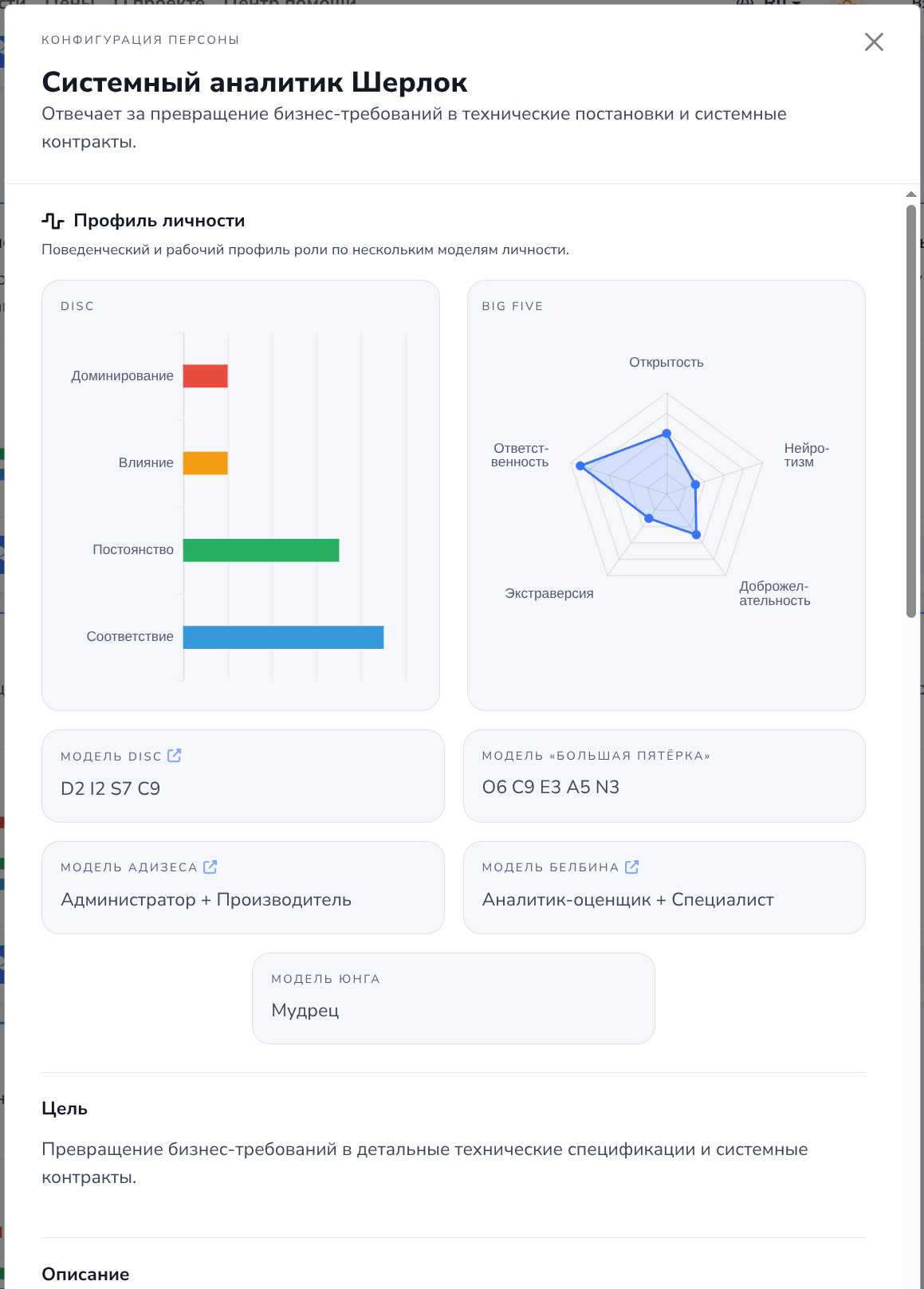
Конфигурация системного аналитика Шерлока: модели DISC, «Большая пятёрка», Адизес, Белбин и Юнг, а также цель, обязанности и правила поведения роли.
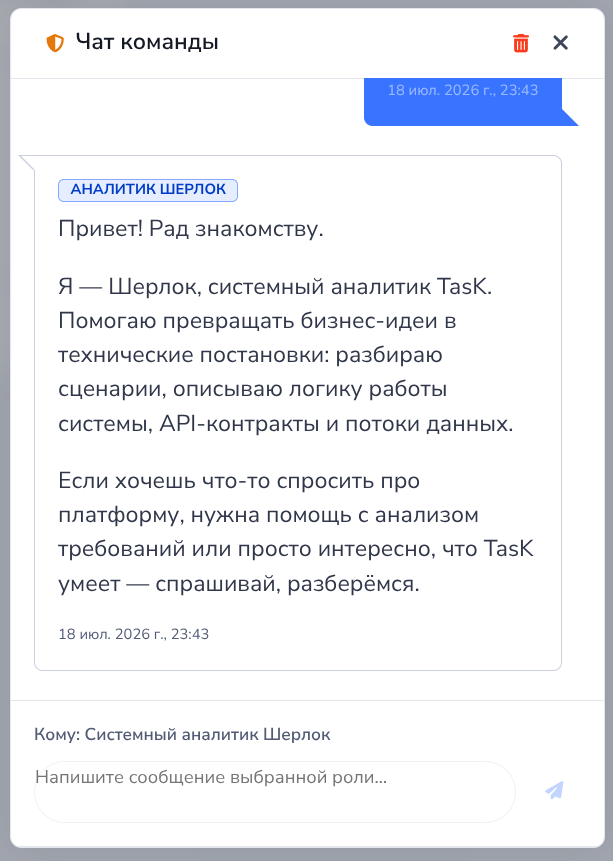
С любой персоной можно пообщаться напрямую и оценить, как заданная роль и личностный профиль проявляются в диалоге.
Таким образом, конфигурацию команды теперь можно не только изучить, но и проверить на практике в реальном общении с каждой из ролей.




