
Я долго скептически относился к идее использовать ИИ для генерации кода. Заявления о том, что «скоро ИИ заменит программистов», вызывали скорее ухмылку, чем доверие.
У меня были конкретные сомнения. Во-первых, что ИИ вообще способен работать с PHP — большинство примеров в сети касались Python, и практического опыта именно с PHP я не встречал. Во-вторых, что LLM вообще могут быть полезны на больших проектах: ведь у LLM есть проблемы с размером контекста, целый проект в контекст не поместится. Хотя как позже выяснилось — моя кодовая база, построенная по принципам DDD — со строгой изоляцией слоёв и своего рода API у каждого слоя, приводит к тому, что нет необходимости загружать в контекст весь проект.
Я постепенно начал использовать ChatGPT. Порой было проще задать вопрос по Symfony, чем копаться в официальной документации. Я также пробовал другие LLM — задавал им одни и те же вопросы, сравнивал ответы и отмечал, какая модель давала более адекватное решение.
И в какой-то момент я решил: пора проверить на практике, как ИИ повлияет на мою эффективность как разработчика. Для начала расскажу немного о себе и о проекте, на котором я проводил (и продолжаю проводить) этот эксперимент.
О себе и проекте
Я в разработке более 20 лет — работал и как программист, и как руководитель команд. В августе 2024 года начал свой проект https://ai-aid.pro, а с марта 2025 ушел из найма и полностью сосредоточился на нём. Это система извлечения текстовых знаний из разных источников: видео, аудио и текстов.
Проект — это PHP-монолит на Symfony 7.3, построенный по принципам DDD, с интеграцией различных LLM, использованием RAG, транскрибацией и диаризацией, а также поддержкой многопользовательского режима и иерархией прав доступа.
Проект глазами утилиты scc:
| Language | Files | Lines | Blanks | Comments | Code | Complexity |
|---|---|---|---|---|---|---|
| PHP | 3160 | 149922 | 23763 | 9591 | 116568 | 2735 |
| Twig Template | 174 | 10052 | 719 | 0 | 9333 | 232 |
| YAML | 134 | 4352 | 293 | 211 | 3848 | 0 |
| Markdown | 41 | 2780 | 693 | 0 | 2087 | 0 |
| Plain Text | 33 | 9791 | 0 | 0 | 9791 | 0 |
| JavaScript | 20 | 1175 | 138 | 162 | 875 | 64 |
| JSON | 13 | 9340 | 0 | 0 | 9340 | 0 |
| Shell | 9 | 412 | 37 | 21 | 354 | 7 |
| XML | 3 | 58 | 2 | 0 | 56 | 0 |
| CSS | 2 | 18 | 2 | 2 | 14 | 0 |
| Sass | 2 | 16 | 0 | 0 | 16 | 0 |
| HTML | 1 | 14 | 0 | 0 | 14 | 0 |
| Makefile | 1 | 165 | 37 | 29 | 99 | 2 |
| Total | 3593 | 188095 | 25684 | 10016 | 152395 | 3040 |
Из таблицы видно: проект насчитывает более 3 000 PHP-файлов (≈150 тыс. строк) и 174 Twig-шаблона (≈10 тыс. строк).
Кодовая база покрыта тестами и подключена к инструментам статического анализа качества: phpunit, plint, psalm, phpcs, deptrac.
Таким образом, проект можно считать сложным и зрелым, а мой опыт — достаточным, чтобы объективно оценивать влияние ИИ.
📊 Метрики
Со временем в моей подписке ChatGPT появился доступ к веб-версии Codex и я решил использовать его в работе над проектом. Чтобы оценить его влияние на мою производительность, я решил собирать метрики. Первым делом я начал собирать статистику по добавленным и удалённым строкам в PR и сравнивать продуктивность до и после использования Codex. При этом часть кода всё равно приходилось писать самому и я мог сравнить, сколько кода генерирует Codex, а сколько пишу я.
Я стал собирать данные по неделям в Google Sheets для построения метрик.
Сначала я построил общую картину динамики добавленных и удалённых строк за период с 2025-W11 (11-я неделя 2025 г., начинается — 10 марта) и до 2025-W36 (36-я неделя 2025 г., начинается — 1 сентября).
Codex я стал использовать на 25-й неделе (16.06.2025)
У меня получился такой график:
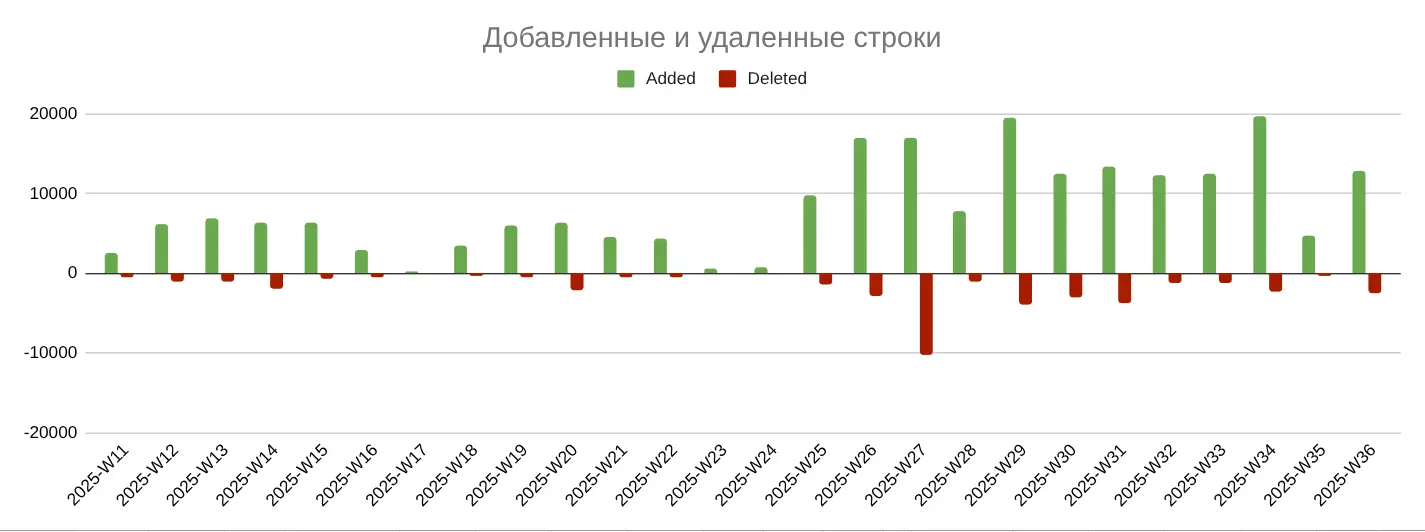
На нём видно: после 25-й недели начался рост как по добавленным строкам (Added), так и по удалённым (Deleted).
После размышлений и обсуждений с ChatGPT я выделил несколько метрик, на основании которых можно понять, как изменилась моя продуктивность после внедрения ИИ.
Доля кода ИИ vs Человек
Эта метрика отвечает на вопрос: «Сколько кода пишет ИИ по сравнению с человеком?»
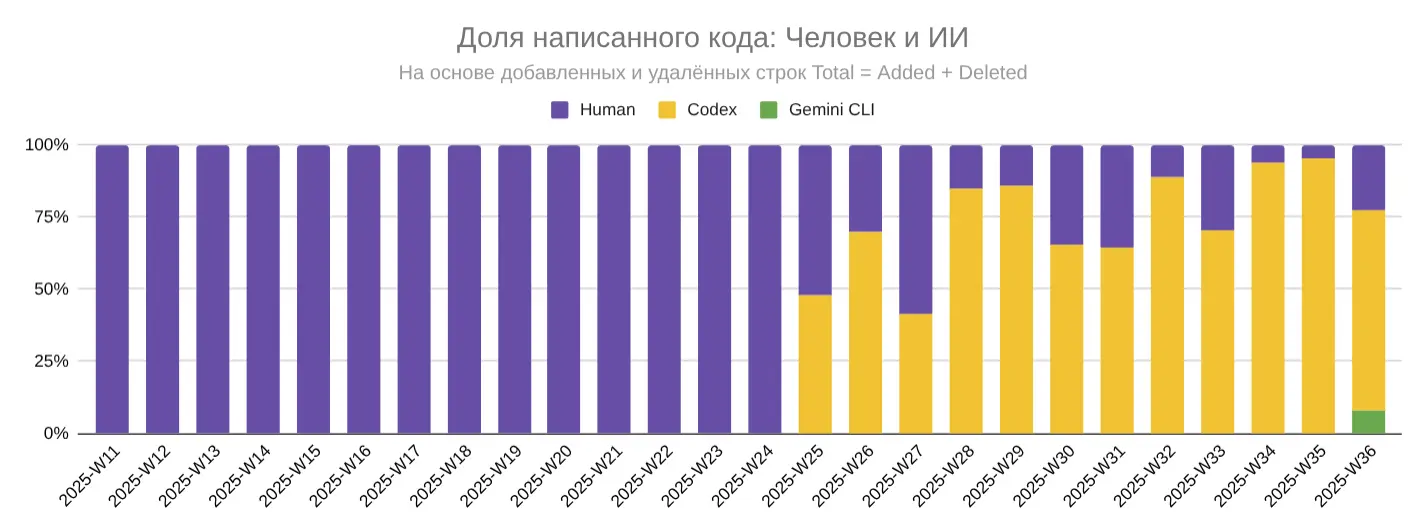
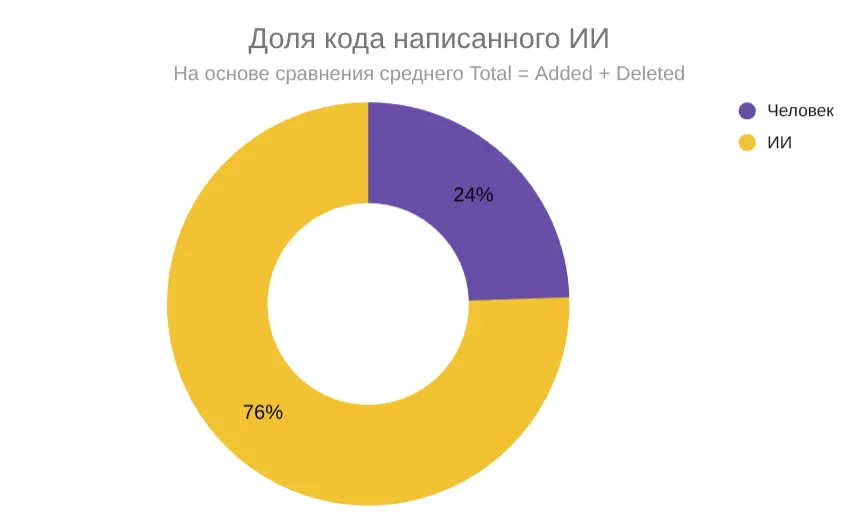
ИИ сейчас пишет порядка 75% кода на проекте. Фактически большая часть кода теперь генерируется ИИ, а человек всё больше выступает в роли архитектора и ревьюера.
Прирост кода
Эта метрика отвечает на вопрос: «Сколько кода мы доставляем в продакшен?»
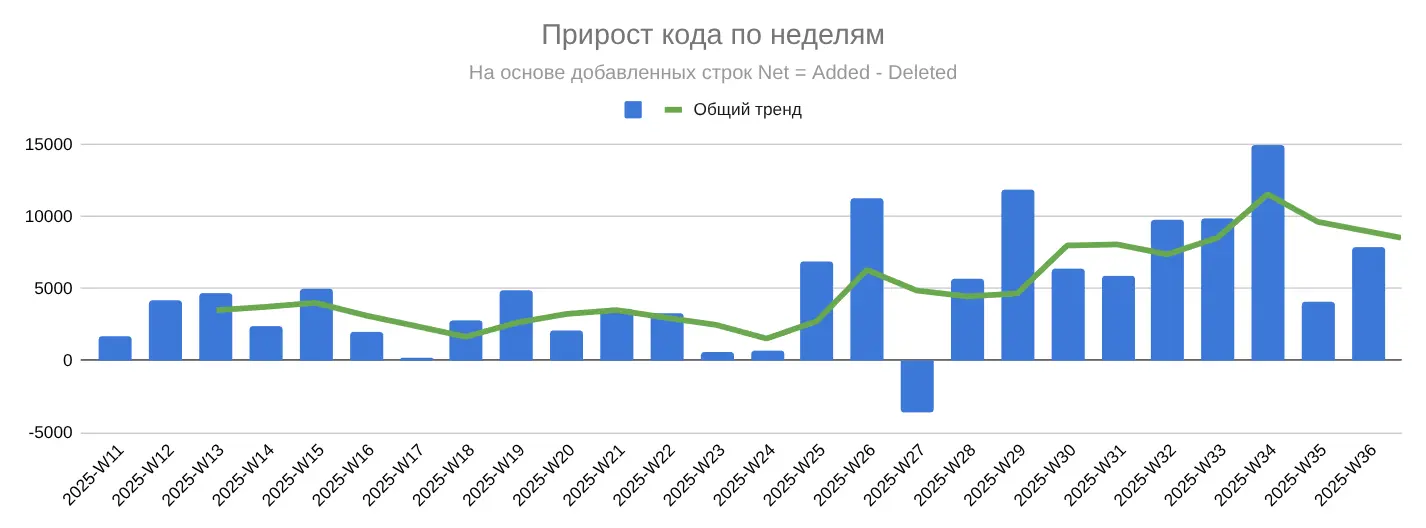
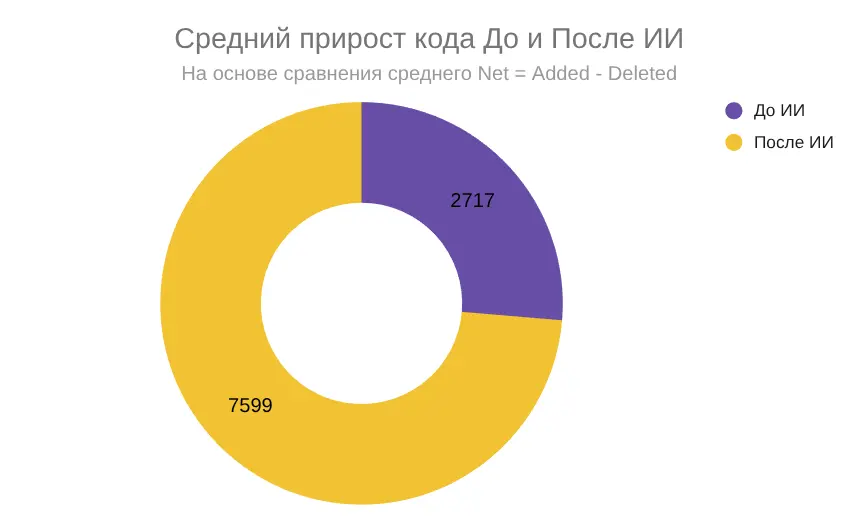
После W25 рост кода стал не всплеском, а устойчивым трендом. Средний прирост вырос почти втрое — с ~2700 до ~7600 строк в неделю. Это означает больше реализованных фич и более быстрое развитие, но одновременно требует более жёсткого контроля качества.
Доля переписываемого
Эта метрика отвечает на вопрос: «Как много правок вносится в существующий код?». Обычно это связано с доработкой, изменением функционала, рефакторингом.
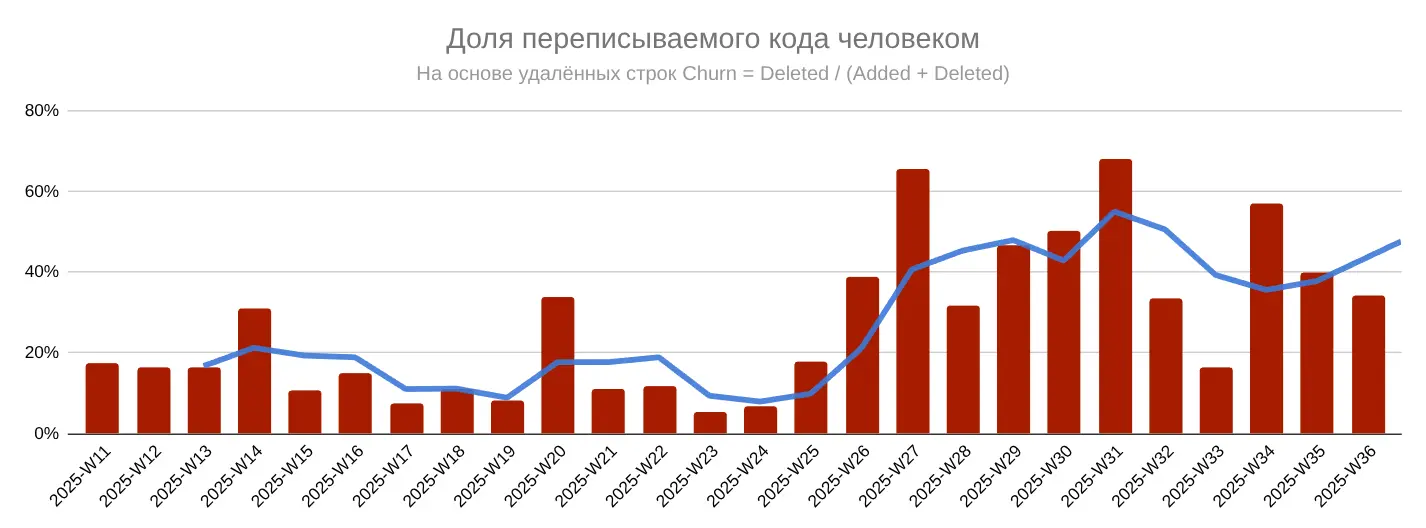
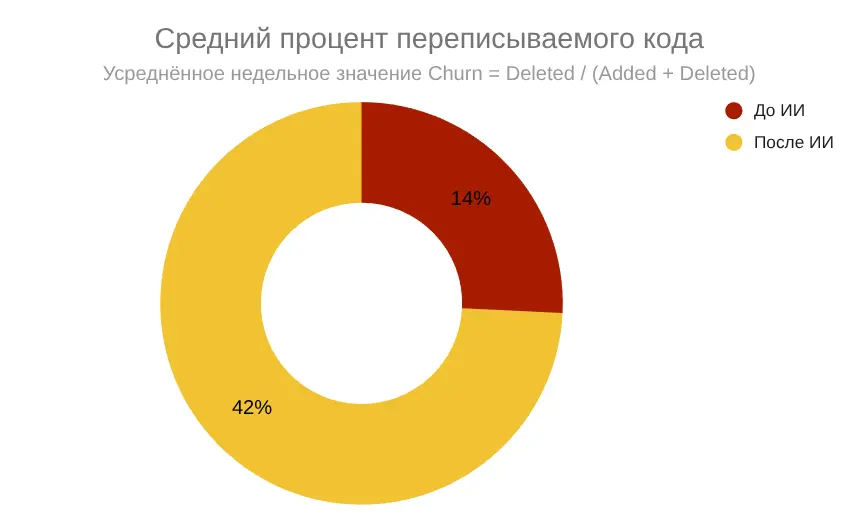
Рост с 14% до 42% отражает смещение роли: человек всё чаще выступает в роли редактора и контролёра кода. Высокий churn — индикатор того, что ИИ даёт решение, но именно человек отвечает за архитектурное качество и финальную доработку.
Итоговый анализ продуктивности разработки
Сравнение продуктивности разработки выполнено за период 2025-W10 по 2025-W36.
Ключевая точка — неделя W25 (середина июня 2025 г.), когда в процесс был внедрён ИИ (Codex, а позже и Gemini CLI). До этого момента весь код писался вручную, после — значительная часть изменений стала выполняться с помощью ИИ-ассистентов.
Влияние на объём кода
После подключения ИИ средний чистый прирост кода (Net) вырос почти в 3 раза — с 2717 строк в неделю до 7599 строк в неделю. Это видно как на динамике по неделям, так и на сравнении средних значений (рост в 2,8 раза). Вклад периода «после ИИ» составляет около 70% всего прироста кодовой базы за исследованный промежуток.
Влияние на роль разработчика
Структура работы изменилась. Доля кода, написанного человеком, снизилась до 24%, тогда как ИИ сгенерировал около 76% всех изменений. При этом Churn (доля переписываемого кода человеком) заметно увеличился — с 14% до 42%, то есть почти в 3 раза.
Помимо этого, у разработчика появились новые задачи, связанные с внедрением ИИ:
- формулировка и постановка задач для ИИ,
- проведение Code Review с учётом особенностей ИИ-кода,
- разработка и поддержка правил кодирования для ИИ (в частности, проработка файла AGENTS.md и раздела правил кодирования в проекте).
Таким образом, роль человека сместилась от написания кода «с нуля» к контролю качества, адаптации решений и управлению процессом работы ИИ.
Общие выводы
Внедрение ИИ значительно повысило продуктивность:
- увеличился темп прироста кодовой базы,
- изменился характер работы разработчика,
- человек стал меньше писать код руками, но взял на себя больше ответственности за качество, правила и контроль.
ИИ становится драйвером ускорения роста проекта, а человек — ключевым архитектором и редактором этого процесса.
⚠️ Дисклеймер по метрикам
Представленные метрики (Net, Total, Churn и доля кода Человек/ИИ) не являются идеальными показателями качества разработки. Это лишь те параметры, которые можно количественно и объективно измерить на основе статистики коммитов.
Важно отметить, что благодаря соблюдению соглашений по кодированию, наличию правил разработки и обязательному Code Review человеком, можно утверждать, что рост кодовой базы не является искусственным (например, за счёт дублирования или раздувания кода).
В таком контексте динамика показателей (сравнение периодов «До ИИ» и «После ИИ») отражает реальное изменение эффективности и продуктивности разработки, а также перераспределение роли человека и ИИ в процессе.
Наблюдение за собой в этот период
Состояние потока и когнитивная нагрузка
-
Состояние потока не возникает — работа становится итерационной, с постоянным переключением контекста. После постановки задачи ИИ приходится думать, чем заняться, ведь в среднем выполнение занимает около 10 минут (иногда до 40–60 минут).
-
Между итерациями сложно найти подходящее занятие: пробовал сериалы, обучающие ролики на YouTube, планирование задач.
-
Когнитивная нагрузка ощутимо выросла — к вечеру чувствуется усталость и информационная перегрузка.
Удерживать «поток» помогает планирование следующих задач для ИИ и для себя между итерациями. Также запуск 2–4 задач параллельно помогает удерживать концентрацию на проекте. При этом изменяется сам «поток»: он смещается от написания кода к реализации фич. Больше думаешь не о том, как сделать, а о том, что сделать. Именно в этом и нужно ловить состояние потока.
Такой подход даёт меньше усталости, больше удовольствия от проекта и драйва. Метрики тоже помогают видеть продуктивность и получать удовольствие от процесса. Постепенно начинаешь думать о том, как добиться производительности уровня 10X.
Взаимодействие с ИИ
Работа с ИИ во многом напоминает взаимодействие с новым разработчиком, который только пришёл в команду и ещё не прошёл onboarding. По уровню это скорее сильный middle: он хорошо справляется с типовыми задачами и уверенно пишет новый код там, где уже есть примеры или понятные паттерны.
Поэтому уровень делегирования можно варьировать — как в модели Бланшара. Здесь хорошо накладывается опыт, полученный на курсе "Команда. Инструменты управления" Школы Стратоплан: многие принципы управления командой работают и при взаимодействии с ИИ.
Акцент смещается с написания кода на внедрение фич (продуктовый подход). Но при этом остаётся необходимость в жёстком контроле за принимаемыми решениями:
- иногда нарушает изоляцию слоёв,
- игнорирует правила,
- может разместить тесты не там, где нужно.
Плюсы и минусы при разработке с ИИ
Плюсы Codex
-
Хорошо выполняет рефакторинг.
-
Генерация boilerplate-кода (пример с простой задачей, пример с более подробной постановкой).
-
Умеет писать тесты.
-
Может обрабатывать несколько задач параллельно.
-
Работает в изоляции (в облачном контейнере), в отличие от других ИИ-агентов — Aider, RooCode, Gemini CLI, Codex CLI. Те вносят изменения в код локально и постоянно запрашивают подтверждения действий, создавая ложное ощущение контроля. Codex выполняет задачу и выдаёт результат в виде PR. Если решение не устраивает — PR можно удалить, и проект остаётся чистым.
-
Вносит правки и в менее очевидные места — документацию, примеры кода, тесты.
-
PR Codex обычно принимаются после 1–2 раундов Code Review.
-
Главное достоинство Codex — он уточняет постановку задачи вместо галлюцинаций.
Примеры работы Codex с неопределённостью
Здесь модель уточняет постановку задачи в несколько итераций:

Здесь модель обнаруживает, что для реализации задачи не хватает данных в БД, и спрашивает, где их взять:

В этом случае модель не уверена в предлагаемом решении и просит подтвердить его:

Здесь модель тоже задаёт качественные уточняющие вопросы по реализации:

Минусы Codex
-
Поддерживает только GitHub.
-
Модель иногда демонстрирует чрезмерную уверенность в темах, в которых не разбирается.
-
Из-за изоляции мелкие задачи и правки проще внести вручную: облачное окружение запускается довольно медленно.
Немного о Gemini CLI
Ценной особенностью является возможность свободно использовать Gemini 2.5 Pro (пусть и с ограничениями) и нарабатывать опыт работы с этой моделью.
По моим субъективным ощущениям Gemini, в отличие от Codex, меньше погружается в детали и иногда предлагает нерабочие решения. Часто ошибается, но после нескольких итераций доводит задачу до рабочего состояния.
Зато с интерфейсами у Gemini выходит заметно лучше. UI лендинга ai-aid.pro я сделал целиком на Gemini CLI. Проект создавался на основе готовой темы, но если реализации Codex выглядели неудачно, то Gemini справился с первого раза.
Поэтому Gemini я использую для задач, связанных с интерфейсами, когда Codex не справляется, а также для генерации документации и текстов для сайта.
Настройка Codex
- Настраивал по этой статье (с тех пор в образе появилась поддержка PHP)
- Пользовательский промпт (слушается очень хорошо)
- Отдельные файлы AGENTS.md для разных частей проекта.
Пользовательский промпт
Отдельно про системный промпт пользователя:
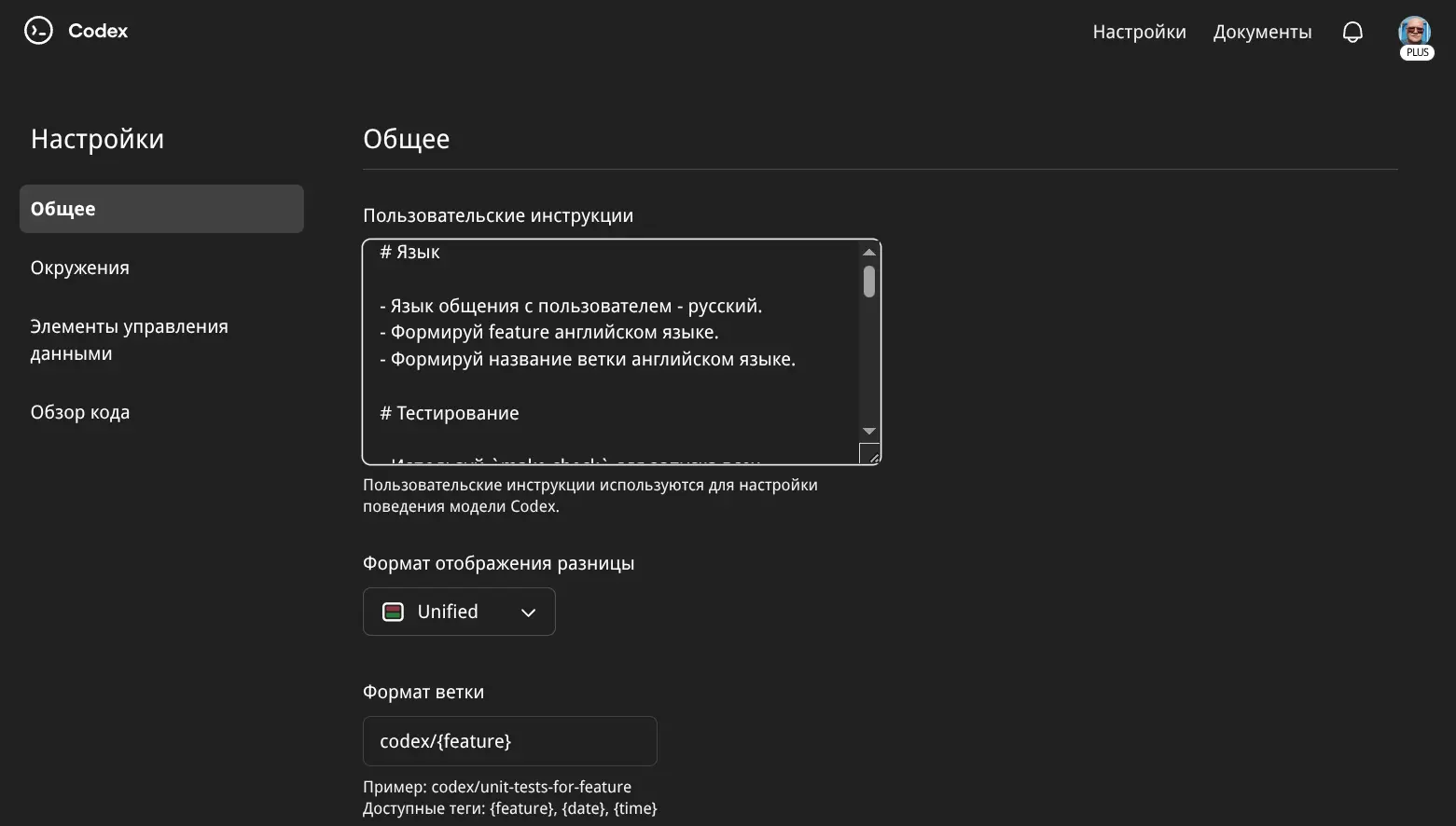
Вот его полный текст:
# Язык
- Язык общения с пользователем - русский.
- Формируй feature английском языке.
- Формируй название ветки английском языке.
# Тестирование
- Используй `make check` для запуска всех проверок (install, phpcs, psalm, tests, deptrac). Проверок в `make check` достаточно много, кодовая база большая, не прерывай выполнение, если тебе кажется что долго работает команда.
# Рефлексия
Ты — умный помощник, но знаешь, что даже опытные системы могут переоценивать свои знания.
Перед тем как решать задачу, оцени тему по трём шкалам:
1. Насколько часто ты видел такую тему в тренировочных данных?
2. Насколько сложна тема для решения?
3. Какие есть риски дать уверенно не верное решение?
Если хотя бы по одному критерию ответ сомнителен — приостановись:
- задай уточняющие вопросы,
- предположи, в чём может быть ловушка или недопонимание,
- предложи несколько альтернативных гипотез, не выбирая одну,
- обозначь, какие допущения ты сделал.
Главное: избегай уверенности, если нет высокого покрытия знаний.К такому промпту я пришёл после того как разбирался как снизить избыточную уверенность LLM-моделей.
AGENTS.md
Codex использует AGENTS.md для понимания того, как работать с кодовой базой. На первоначальную проработку этих инструкций я потратил пару дней.
Что я заметил: при написании кода Codex меньше опирается на правила из AGENTS.md, а сильнее — на соседние примеры. Поэтому решения ИИ нужно тщательно проверять на соответствие правилам и архитектуре — иначе отклонения от правил начнут копироваться, и с каждым разом будет рождаться всё больше хаоса.
Ниже — мой текущий корневой AGENTS.md:
AGENTS.md — Guide for AI agents working with TasK project
---
## Quick Start
Run the following commands to set up and verify your environment:
```bash
make checkvendor/bin/conventional-commits prepare```
Detailed rules are available in `tests/AGENTS.md` and `src/AGENTS.md`.
# Архитектура проекта
* **Ядро:** Symfony 7.3 (PHP 8.3), Domain-Driven Design (DDD)
* **Асинхронность:** Symfony Messenger для очередей и фоновых задач
* **Фронтенд:** Symfony UX (Turbo, Stimulus), AssetMapper
* **Тема интерфейса:** Bootstrap 5 Phoenix (кастомная)
* **События и контракты:** Расширяемая событийная модель, строгие DTO-контракты
* **Автозагрузка:** PSR-4 (composer.json)
## Структура проекта
/
├── apps/ # Мультиприложения: web, api, console
├── src/ # Общие модули и доменная логика
├── config/ # Глобальные настройки и DI
├── migrations/ # Миграции
├── tests/ # Тесты (unit, integration, e2e)
├── bin/, ci/ # Инструменты, CI/CD, утилиты
* **Web** (`/apps/web/`): веб-интерфейс, контроллеры, публичные entrypoints
* **API** (`/apps/api/`): REST-контроллеры, схемы, роутинг
* **Console** (`/apps/console/`): CLI-команды, крон-задачи
## Модули и слои
* Любой функционал — отдельный модуль: `src/Module/{ModuleName}/`
* **Domain**: бизнес-логика, ValueObject, Entity, интерфейсы
* **Application**: UseCases, сервисы, DTO
* **Infrastructure**: репозитории, кэш, логирование
* **Integration**: внешние API, события, адаптеры
> **Ключевой принцип:**
> **Жёсткое соблюдение слоёв и модульной изоляции.**
> Взаимодействие между слоями — только через публичные интерфейсы или Integration Layer.
---
# Tests and Validation
* **Все изменения в слоях Domain, Integration, Infrastructure обязательно покрываются тестами.**
* **Виды тестов:**
* **Unit** (`tests/Unit/`): Только бизнес-логика и ValueObject (Domain Layer, Application Layer при необходимости).
Никаких БД, файловой системы или реальных внешних сервисов.
* **Integration** (`tests/Integration/`): Проверка взаимодействия Application ↔ Infrastructure/Integration.
Используйте тестовую БД и Fake/Moq для внешних API.
Интеграционные тесты должны наследоваться от `Common\\Component\\Test\\KernelTestCase` и инициировать ядро через `self::bootKernel()` (см. `tests/AGENTS.md`).
* **End-to-End (Functional)** (`apps/*/tests/`): Сквозные сценарии через публичные интерфейсы (Web, API, Console).
* **Минимальное покрытие unit-тестами для нового кода:** **80%**
(любой PR с понижением покрытия отклоняется).
* **Обязательные проверки перед коммитом:**
Все команды должны проходить **без ошибок**:
`make psalm`, `make phpcs`, `make tests-unit`, `make audit`, `make deptrac`
* **Для AI-агентов:**
* Всегда добавляйте юнит-тесты к новым классам.
* Для Infrastructure/Integration — пишите интеграционные тесты с Mock/Fake.
* Тесты разделяйте по каталогам (`Unit`/`Integration`).
* Каждый багфикс сопровождайте тестом, воспроизводящим баг.
* Не используйте реальные сервисы или прод-данные в тестах.
* **Ключевые инструменты:**
PHPUnit, Psalm, Deptrac, PHP_CodeSniffer, Composer
| Tool | Configuration File | Purpose |
|------------------|--------------------|-----------------------------------|
| PHPUnit | `phpunit.xml.dist` | Unit, integration tests |
| Psalm | `psalm.xml` | Static code analysis |
| Deptrac | `depfile.yaml` | Static architecture code analysis |
| PHP_CodeSniffer | `phpcs.xml.dist` | Code style validation |
| Composer | `composer.json` | Dependency and security checks |
> Любое изменение без запуска тестов, статического анализа и соблюдения архитектурных слоёв — отклоняется.
---
# Working with Code
* **Вся логика разносится по слоям и модулям строго по DDD**
(Domain, Application, Infrastructure, Integration).
Нарушение слоёв и модульных границ не допускается.
* **Каждая новая фича или правка** реализуется:
* В соответствующем модуле (`src/Module/{ModuleName}`)
* В правильном слое — без «расползания» логики
* **Контроллеры только для делегирования:**
Валидация, трансформация данных, вызов UseCase — никаких сервисов или репозиториев напрямую.
* **Документируйте всё значимое:**
Новые API, публичные методы, изменения — через PHPDoc и/или модульную документацию.
* **Тестирование:**
Все изменения обязательно сопровождаются unit/integration тестами своего слоя
(см. раздел *Tests and Validation*).
* **Временные решения/технический долг:**
Явно помечайте `@todo` или `@techdebt` с датой и объяснением.
* **Рефакторинг:**
Только отдельным PR и с обновлением тестов/документации.
> **Важно:**
> Массовые рефакторинги, перемещения файлов, нарушения архитектуры или объединение разнородных изменений — только по согласованию через issue или отдельный PR с пояснением причин.
---
# Pull Requests
* **Один PR — одна логически завершённая задача** (feature, bugfix или рефакторинг).
* **Не смешивайте разные типы изменений** (например, фича и рефакторинг — только с отдельным согласованием).
* **Ветка и PR на английском:**
Формат ветки — `task/<short-description>` (например: `task/add-user-registration`).
* **Все проверки должны быть успешны:**
* Тесты (unit/integration),
* Статический анализ (`psalm`, `phpcs`, `deptrac`),
* Аудит безопасности (`composer audit`),
* Покрытие тестами не ниже 80%.
* **В описании PR укажите:**
* Цель и суть изменений (коротко и по делу)
* Аffected modules и ключевые файлы
* Особые случаи/компромиссы, breaking changes
* Результаты тестов и статического анализа (вывод из консоли)
* Ссылки на задачи/issues/разделы AGENTS.md
* **Commit messages** — строго по [Conventional Commits](https://www.conventionalcommits.org/)
(генерируйте через `vendor/bin/conventional-commits prepare` и копируйте вручную).
* **PR с понижением покрытия или без запуска тестов — отклоняется.**
* **Временные решения или архитектурные компромиссы обязательно сопровождайте пояснением и пометкой в коде.**
> **Любой PR, нарушающий эти правила, отклоняется без рассмотрения.**
---
# Временные решения
* Любое временное решение или костыль обязательно отмечайте в коде тегом `@todo` или `@techdebt`.
* Указывайте дату и кратко объясняйте причину.
* Все такие места должны быть запланированы к устранению и вынесены в задачи (issues).
---
# Документирование
* Все публичные классы, интерфейсы и методы документируются через PHPDoc.
* Любые новые API, точки входа или архитектурно значимые изменения сопровождаются кратким описанием цели и ответственности (можно в Markdown).
* Если изменяется контракт между слоями — обязательно обновите документацию и примеры использования.
* В комментариях и документации отмечайте любые breaking changes.
---
# Что запрещено
* Нарушать слоистую архитектуру и модульную изоляцию (например, вызывать Domain из Infrastructure напрямую).
* Смешивать бизнес-логику и технические детали.
* Использовать статические синглтоны, глобальное состояние, нестрогую типизацию.
* Перемещать/удалять классы и файлы без явного согласования через issue.
* Использовать реальные внешние сервисы или секретные данные в тестах.
* Объединять разные типы изменений (feature, bugfix, refactor) в одном PR.
* Вносить временные решения без тега `@todo`/`@techdebt` и объяснения.
---
# Мини-чеклист (для быстрой самопроверки)
* [ ] Логика строго в нужном слое/модуле
* [ ] Нет нарушений DDD и архитектуры
* [ ] Каждый новый код покрыт тестом нужного слоя
* [ ] Нет смешивания разных изменений в одном PR
* [ ] Документация/комментарии к публичным API обновлены
* [ ] Временные решения помечены и описаны
* [ ] Все проверки проходят (`tests`, `psalm`, `phpcs`, `deptrac`, `audit`)
* [ ] Коммиты — только Conventional CommitsУ меня также есть отдельные AGENTS.md для тестов, для apps/, src/ и tests/. Изначально был один большой файл, но по журналу стало видно, что Codex плохо работает с крупными инструкциями, поэтому я разбил их на части. Это допускается системным промптом.
Совет: анализируйте журнал агента, который формируется при работе над задачей: ищите трудности и устраняйте их промптингом, инструментами или настройками. Я прогонял журнал через ChatGPT, чтобы анализировать проблемы.
Заключение
Что важно учитывать при внедрении ИИ в процесс разработки:
При оценке влияния ИИ на производительность стоит принимать во внимание:
-
архитектурную зрелость и структуру проекта: DDD, изоляцию слоёв и собственные API у каждого модуля, которые позволяют декомпозировать задачи и минимизировать влияние правок на остальной код;
-
наличие соглашений и правил в виде текстовой документации;
-
наличие тестов;
-
использование инструментов автоматической проверки качества кода;
-
тип задач (типовые и шаблонные задачи хорошо масштабируются с ИИ);
-
сам инструмент и модель, понимание их границ применения: я пробовал RooCode, Aider, Gemini CLI, но Codex оказался заметно эффективнее.
Дальнейшие планы
-
искать способы уменьшения когнитивной нагрузки и удержания состояния потока (сейчас оно нарушается из-за постоянных переключений);
-
попробовать внедрять отдельного ИИ-агента для Code Review, оставляя за собой только финальное ревью;
-
расширять правила в deptrac для контроля нарушений изоляции между слоями и модулями;
-
глубже погрузиться в Aider, RooCode, Gemini CLI, Codex CLI и другие, чтобы понять, какие задачи и модели они решают лучше всего, собрать аналитику и сделать выводы;
-
добиться от ИИ-агента большей автономности: передать ему ревью кода, оставив за собой только финальное;
-
повысить скорость работы (сейчас выполнение одной задачи занимает 10–40 минут);
-
организовать процесс доставки задач в Codex: часть задач нельзя запускать сразу, иногда есть мелкие правки, которые нужно не забыть исправить, или рождаются новые идеи прямо в процессе — важно, чтобы агент мог их подхватывать впоследствии.
-
🚀 увеличить продуктивность работы с ИИ в 10 раз!
Лайфхаки для ускорения
-
анализировать журнал агента, искать трудности и устранять их промптингом, инструментами или настройками;
-
запускать создание PR ещё до завершения ревью (у меня этот процесс занимает время, так как в GitHub Actions запускаются тесты и статические анализаторы);
-
мелкие замечания из Code Review и небольшие задачи фиксировать вручную;
-
не накапливать технический долг: ИИ берёт за основу существующий код, поэтому важно регулярно устраивать «субботники» и поддерживать его в порядке.
Что делать, пока пишется код, чтобы не терять поток
-
запускать несколько задач параллельно (если кода много и задачи независимы) — но учитывать, что это повышает когнитивную нагрузку;
-
прорабатывать будущие фичи проекта и заранее формулировать новые задачи для агента.
Вывод
Интересно, что в исследовании METR делается вывод, что ИИ скорее мешает опытным разработчикам. Мой случай показывает иную картину — в условиях зрелого проекта и выстроенных практик ИИ становится усилителем продуктивности.
ИИ действительно может масштабировать продуктивность, но эффект сильно зависит от зрелости проекта, умения эффективно промтить и качества ИИ-инструмента.
Разработка с ИИ — это не столько про скорость, сколько про переосмысление самого подхода к созданию кода.
💡 Если тебе близка тема Codex, LLM, ИИ-агенты, RAG, векторные БД, PHP 8.4 и Symfony 7.3, — буду рад пообщаться.
✉️ dmitry@prikotov.ru
💬 Telegram: @prikotov




