
В своем пет-проектe TasK.Ai-Aid.pro для распознания аудио я использую whisper.cpp, запуская его на CPU, без использования GPU. В связи с этим мне было важно знать, как я могу более эффективно использовать whisper.cpp.
В этой статье я хочу поделится своими исследованиями влияния количества потоков на производительность whisper.cpp при запуске на CPU, без использования GPU.
Конфигурация оборудования
Для оценки производительности whisper.cpp я использовал свой домашний мини-компьютер MINISFORUM UM890 Pro. На момент тестирования (апрель 2025 г) аппаратная конфигурация была следующей:
- Процессор: AMD Ryzen 9 8945HS (8 ядер / 16 потоков) с графикой Radeon 780M
- Память: 64 ГБ DDR5 5600 MHz (SODIMM Kingston FURY Impact KF556S40IBK2‑64 – две планки по 32 ГБ)
- Диски: SSD M.2 NVMe Kingston FURY Renegade 1000 ГБ × 2 (в RAID 1)
- ОС: Linux x86-64 (Fedora 41)
Сценарий теста
Whisper.cpp — это порт модели Whisper от OpenAI, реализованный на C/C++ и предназначенный для локального распознавания речи. Проект поддерживает множество оптимизаций для современных процессоров.
Для измерения производительности использовалась версия whisper.cpp v1.7.4 с лучшей по качеству на тот момент моделью ggml‑large‑v3. Распознавание проводилось на одной русскоязычной аудио‑записи длиной 277‑секунд (4 мин 37 сек).
Команда запуска из корневой папки whisper.cpp:
build/bin/whisper-cli \
-m models/ggml-large-v3.bin \
-f ../../segment.ogg \
--language ru \
--split-on-word \
--max-len 80 \
--output-json-full \
-otxt \
-t 8Пояснение ключей
| Ключ | Значение | Комментарий |
|---|---|---|
-m models/ggml-large-v3.bin |
Модель Large v3 | Максимальная точность, но самая ресурсоёмкая |
-f ../../segment.ogg |
Входной файл | Тестовый аудиосегмент |
--language ru |
Русский язык | Исключает фазу автоопределения языка |
--split-on-word |
Деление по словам | Минимизирует обрыв слов в концах сегментов |
--max-len 80 |
Макс. длина сегмента | Оптимум для субтитров и читаемости |
--output-json-full |
Полный JSON-вывод | Все токены, вероятности и тайминги |
-otxt |
Текстовый вывод | Удобен для оценки результатов |
-t 8 |
Потоков CPU | Количество используемых потоков (в тесте варьировалось от 1 до 16) |
Тут подробная информация по ключам запуска.
Для каждого значения числа потоков от 1 до 16 запускался один прогон, а для конфигураций с 8 и 9 потоками дополнительно измерялись несколько прогонов для проверки стабильности результатов. Время измерялось в секундах с помощью встроенной статистики Whisper.
Результаты
Таблица
В таблице ниже представлены усреднённые показатели времени обработки файла, ускорения в пересчете на один поток, скорость обработки в сравнении с реальной длительностью файла
| Количество потоков | Время обработки файла (сек) | Ускорение (в раз) | Скорость обработки (× реального времени) | |
|---|---|---|---|---|
| 1 | 1169.6 | 1.00 | 0.24 | |
| 2 | 611.1 | 1.91 | 0.45 | |
| 3 | 417.6 | 2.80 | 0.66 | |
| 4 | 322.6 | 3.63 | 0.86 | |
| 5 | 265.6 | 4.40 | 1.04 | |
| 6 | 235.0 | 4.98 | 1.18 | |
| 7 | 214.8 | 5.45 | 1.29 | |
| 8 | 197.9 | 5.91 | 1.40 | |
| 9 | 202.4 | 5.78 | 1.37 | |
| 10 | 201.5 | 5.80 | 1.37 | |
| 11 | 198.8 | 5.88 | 1.39 | |
| 12 | 194.9 | 6.00 | 1.42 | |
| 13 | 195.7 | 5.98 | 1.42 | |
| 14 | 200.1 | 5.84 | 1.38 | |
| 15 | 210.3 | 5.56 | 1.32 | |
| 16 | 229.9 | 5.09 | 1.20 |
Ускорение = Время обработки одним потоком / Время обработки t потоками
Скорость обработки = Длительность аудио / Время обработки
📈 Графики
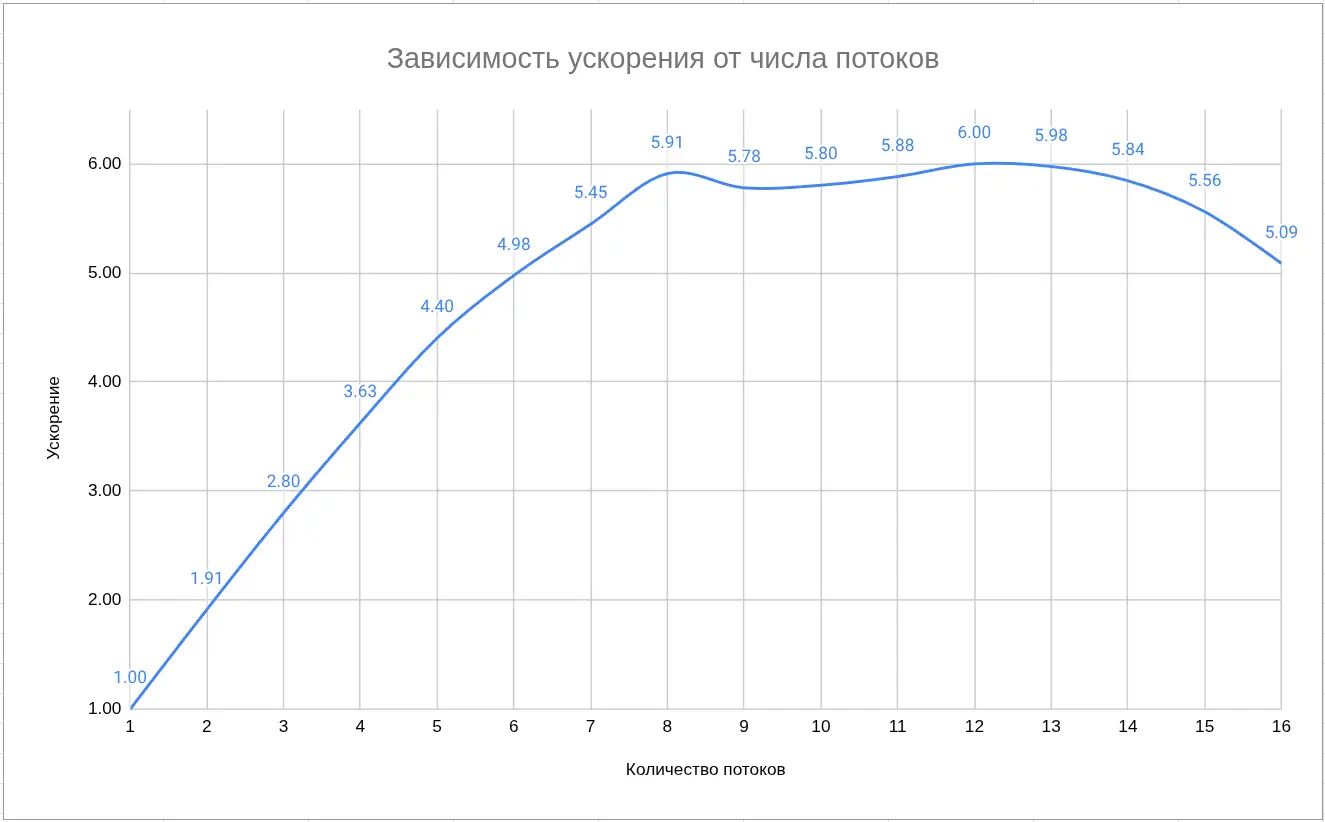
1. Зависимость ускорения от числа потоков
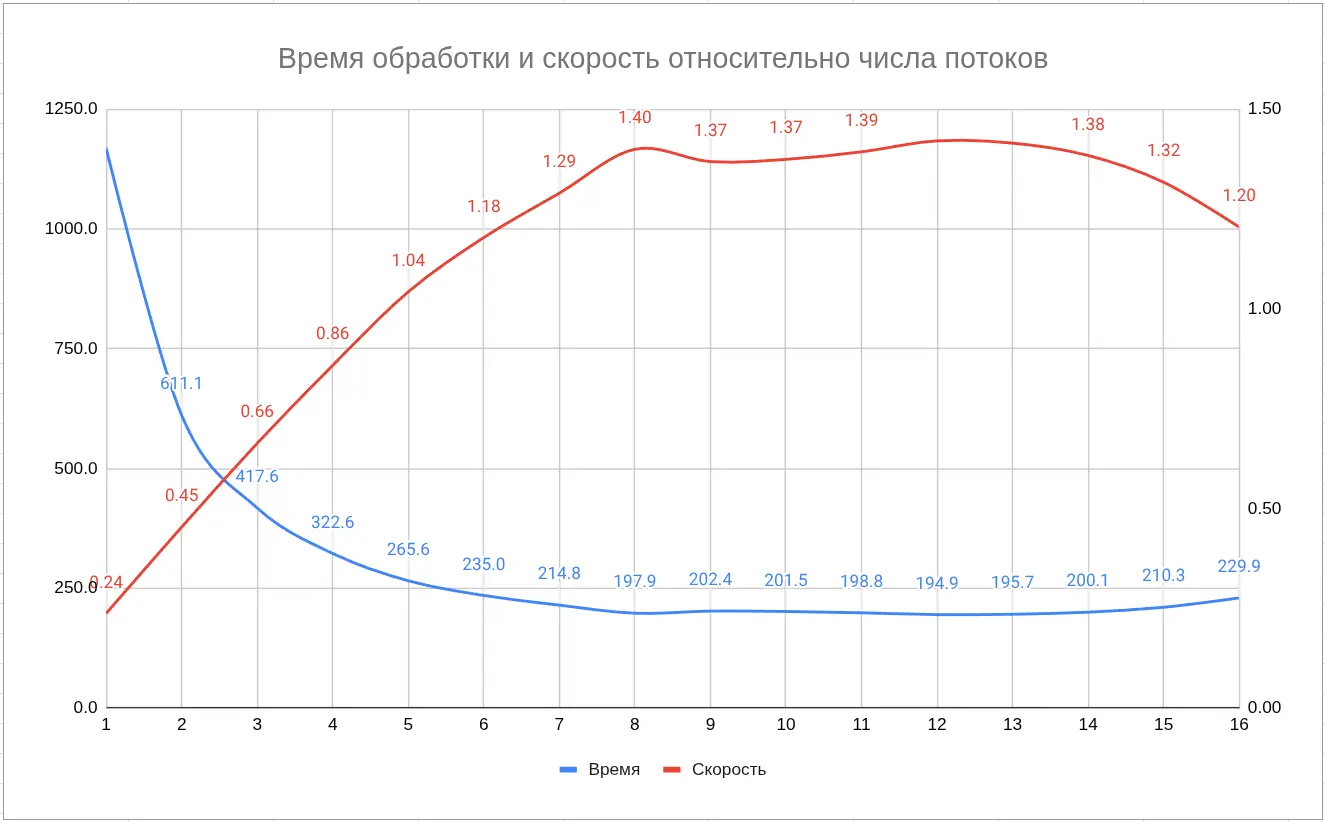
2. Время обработки и скорость относительно числа потоков
Пояснения к графикам
- Рост ускорения до 8 потоков близок к идеальному — прирост почти линейный (до 5.9×).
- После 8–10 потоков начинается плато, видимо вызванное конкуренцией за ресурсы.
- Максимальная скорость обработки ≈ 1.4× реального времени (аудио длиной 277 с обрабатывается за ≈ 198 с) на 8-ми потоках.
- Начиная с 12–16 потоков наблюдается обратный эффект — рост времени из-за переключения контекстов и падения эффективности.
Анализ: какой закон описывает поведение
-
Колонка «Ускорение» подчиняется закону Амдала, где последовательная часть кода ограничивает дальнейший прирост. Для whisper.cpp примерно P≈0.95P ≈ 0.95P≈0.95, что даёт максимальное ускорение около 6–7× при бесконечном числе потоков.
-
Если же разделить аудио на части и распознавать их независимыми экземплярами whisper.cpp, то задача может масштабироваться по закону Густафсона – Барсиса, и ускорение может расти почти линейно (до 16× и выше при многопоточном батчинге).
Практические рекомендации
- Для оптимального баланса скорости — использовать
-t 8. - При обработке длинных файлов лучше разделить аудио на сегменты и распознавать их параллельно.
- Для ускорения без потери качества можно держать модель в RAM-диске или использовать серверную реализацию whisper.cpp.
Выводы
- whisper.cpp на Ryzen 9 8945HS способен работать почти в реальном времени на самой тяжелой модели Large v3 (≈ 1.4× RT).
- Эффективность масштабирования хорошо согласуется с законом Амдала — до 8 потоков рост почти идеальный.
- Для массовых задач (батч-распознавание, подкасты, видео) лучше использовать несколько параллельных экземпляров модели.




