
«Всё как у людей».
Суть статьи: Почти год я выстраивал свой проект под разработку с ИИ-агентами для программирования. В итоге пришёл к выводу: важна не столько модель, сколько harness (инженерная упряжка, обвязка) вокруг неё — набор инструкций, правил, доступных инструментов, ролей и коротких feedback loops (циклов обратной связи) через тесты, статический анализ, self-review (самопроверку) и code review агентом. Финальное ревью остаётся за человеком. После перехода на такой процесс поток изменений вырос: сумма добавленных и удалённых строк в недельных diff стала больше в 11,3 раза, чистый прирост строк — в 4,5 раза при сохранении качества кода.
Я долго откладывал эту статью: процесс часто менялся. Сначала был Codex Cloud, потом CLI, затем появились роли, задачи в markdown, проверки, конвенции и первые эксперименты с оркестрацией. Сейчас это уже похоже на рабочую систему, которую можно показать.
Начинал я осторожно: давал агенту мелкие правки и проверял почти каждую строку. Постепенно переносил в инструкции агенту то, что раньше держал в голове: правила, нужный контекст, архитектурные ограничения и команды проверки. Так вокруг агента и модели появилась упряжка, которая помогает им работать с большим проектом.
В статье покажу, что я делаю, чтобы:
- ИИ-агент не писал плохой код;
- при добавлении нового не ломал старое;
- соблюдал инструкции;
- не забывал контекст проекта и старые решения;
- меньше времени уходило на проверку его работы;
- как использование ИИ-агентов влияет на мою продуктивность.
Содержание
Для кого эта статья
Есть две шумные крайности.
Первая: «ИИ ничего не умеет, нормальный разработчик всё сделает лучше». Тут вспоминается мем про кошек: «Не люблю кошек». — «Ты просто не умеешь их готовить». С ИИ-агентами похожая история: если кинуть задачу без контекста, без рецепта и в неподготовленный проект, агент начнёт угадывать твой вкус. Иногда угадает. Чаще приготовит так, как считает правильным сам.
Вторая: «ИИ всех заменит, разработчики больше не нужны». Менеджеры начинают мечтать о командах без программистов, программисты — о проектах без менеджеров. Звучит здорово, но реальная работа всё равно упирается в ответственность и проверку результата экспертом.
Мне ближе середина: ИИ-агент — усилитель эксперта. Я смотрю на ИИ как на инструмент: его нужно пробовать, исследовать, встраивать в работу и усиливать через него себя, команду и компанию. Для этого мало купить подписку на модель. Нужно выстраивать AI-first и AI-friendly процессы, где агент получает контекст, работает по правилам, перепроверяет результат и не остаётся без присмотра человека-эксперта.
Для первых я покажу, что я сделал, чтобы ИИ-агент начал работать лучше: какие правила дал, какой контекст вынес в файлы, какие проверки добавил и где не стоит доверять ИИ без проверки.
Для вторых — где проходит граница: что можно отдавать ИИ, а что лучше оставить себе как человеку-эксперту. Агент может писать код, гонять проверки, собирать контекст и предлагать решения. Ответственность за результат всё равно остаётся у человека.
А ещё эта статья для тех, кто идёт похожим путём: пробует, экспериментирует, меняет процесс и хочет посмотреть на чужой опыт без обещаний, что завтра все станут не нужны.
Мой опыт с агентами и моделями
Как я пришёл к ИИ-агентам
Почти год назад я начал использовать ИИ-агентов в разработке. Я сразу понимал, что этому придётся учиться самостоятельно: опыт новый, готовых правил мало. Тогда я сомневался, что ИИ сможет работать с большой кодовой базой. Простые запросы — да. Подсказать идею — да. Но писать код в реальном проекте? Тут у меня были сомнения.
Началось всё с подписки ChatGPT и облачного Codex в веб-интерфейсе. Codex CLI уже существовал, но из России его было сложнее быстро запустить. Через веб у меня всё работало, поэтому я начал с Codex Cloud. Первый опыт описывал отдельно: «Мой опыт с Codex: влияние на продуктивность».
И меня зацепило. После первых сессий я завёл в репозитории AGENTS.md — файл с инструкциями для агента. Сначала там были только базовые правила проекта, но этого уже хватало: агент лучше понимал структуру, писал код в принятом стиле и хорошо закрывал шаблонные задачи. Тогда Codex Cloud отдельно не тарифицировался, поэтому я начал использовать его почти постоянно.
Со временем я понял, что на качество кода можно влиять через AGENTS.md.
Если агент повторял ошибку, я добавлял правило в AGENTS.md. Файл рос. Через какое-то время агент начал сам жаловаться, что AGENTS.md большой и он читает его частями. Это был сигнал: я пытался запихнуть всю память проекта в один файл.
Так подход постепенно эволюционировал:
- в корневом
AGENTS.mdдержать только самые главные правила и использовать его как маршрутизатор второстепенных правил; - второстепенные правила выносить в
docs/; - хранить там информацию, которая нужна мне и агенту по проекту;
- документировать знания, которых нет в коде или которые агенту слишком дорого вытаскивать из него;
- не описывать то, что модель и так знает на базовом уровне.
Я даже пробовал проводить технические «собесы» ИИ-агентов: спрашивал про DDD, SOLID, архитектурные слои, Symfony, тесты, статический анализ и процесс работы с PR. Смотрел, где агент уверенно отвечает, где путается, где ему нужны чёткие входные данные. На основе таких ответов собирал матрицу компетенций: что агенту можно поручать, где нужны проверки, а какие правила лучше сразу вынести в документацию.
Потом в Codex Cloud ввели лимиты. Я начал вырабатывать их за 1–2 дня, а в описании расхода увидел, что CLI-инструмент потребляет меньше. Так я перешёл на Codex CLI и начал разбираться с процессом работы в консоли.
В консоли быстро вылезли бытовые неудобства:
- при работе над интерфейсом нужно как-то передавать агенту картинки;
- в Linux начинается шиза с конфликтом двух буферов обмена: один для выделения мышкой, другой для обычного копирования, из-за этого сложно нормально скопировать и вставить текст;
- привычное
Ctrl+Zостанавливает процесс в терминале вместо отмены введённого текста; - с отправкой сообщения тоже нужно привыкать:
Enter,Alt+Enter,Shift+Enter, случайное отправление послеTab.
Чтобы решить эти проблемы, я начал пробовать другие терминалы. Мой старичок xfce4-terminal для работы с TUI-агентами, похоже, морально не годится. Посмотрел Ghostty, Kitty, Warp, Tilix, Alacritty. Остановился на Ghostty.
Часть боли удалось снять настройками:
- буфер обмена привёл в порядок настройками Ghostty;
- картинки для задач по интерфейсу сохраняю на рабочий стол и перетаскиваю в терминал, чтобы вставился путь;
- агентов запускаю с расширенными правами (
yolo mode), чтобы они могли брать картинки не только из папки проекта.
Параллельно я искал источники информации, из которых можно перенять практический опыт. Информации вокруг много, но часто это новости уровня «вышла крутая модель» или «появился новый инструмент» — без деталей, как с этим жить в реальном проекте. Поэтому я смотрел новости, пробовал сам и постепенно находил более полезные источники: каналы и чаты, где разработчики делятся опытом использования агентов. Там делились статистикой активности на GitHub. Я офигел: у некоторых разработчиков через агентов проходило по несколько миллионов строк.
Постепенно я стал тратить всё больше времени не только на кодинг с ИИ-агентом, но и на поиск инструментов, погружение в них и улучшение самого процесса разработки. Стало понятно: результат зависит не только от модели, а от того, как вокруг неё устроена работа.
ИИ-агенты, которые я пробовал
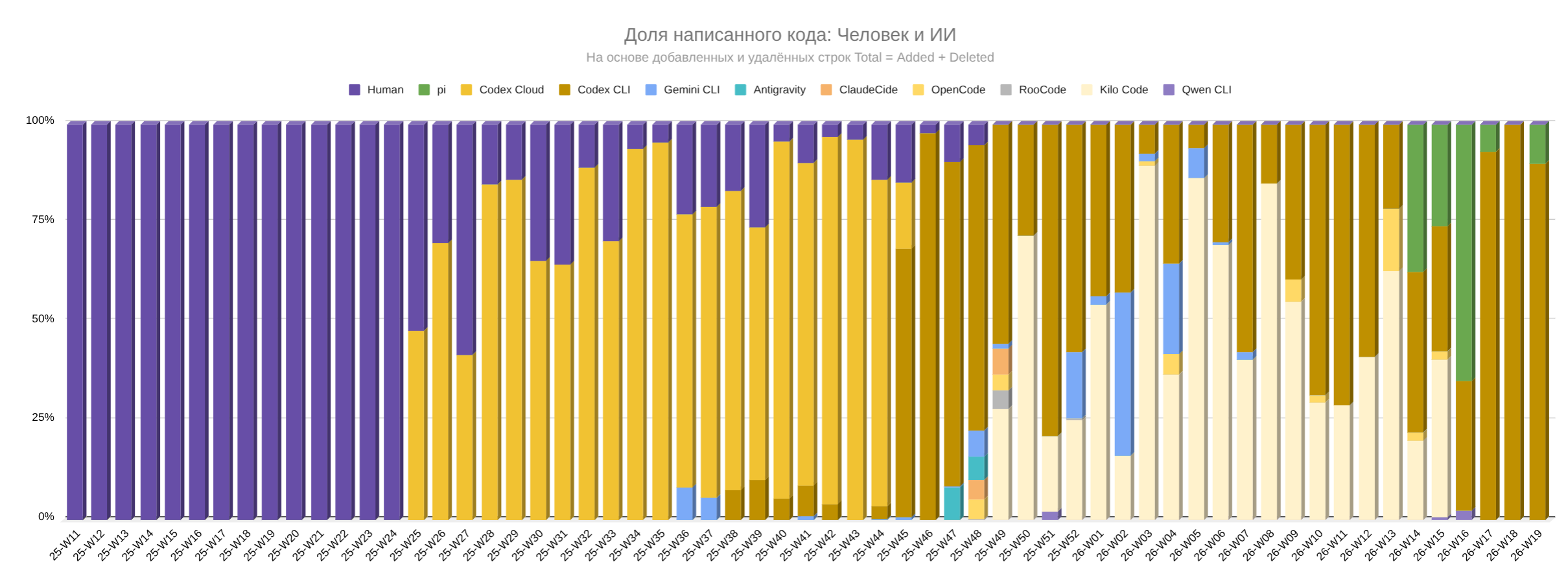
Статистика использования мной агентов на проекте TasK
Этот график — иллюстрация того, как я пробовал разные ИИ-агенты на проекте TasK. По нему видно не только рост агентского кода, но и то, как менялся набор инструментов: Codex Cloud, Codex CLI, Kilo Code, Pi и другие. Сравнивать их по обзорам не хотелось: я брал текущую задачу в своём проекте и смотрел, как агент выполняет задачу, насколько автономно и качественно он её решает.
Новых агентов и моделей выходит больше, чем у меня есть времени на тесты. Поэтому ниже — краткий субъективный отзыв: что пробовал, где задержался, где быстро отвалился и почему.
Codex Cloud — веб-агент от OpenAI: проект поднимается в облаке, ревью кода идёт прямо в приложении. Хорошо зашёл как первый опыт: изоляция и удобное ревью. Минусы вырастают из плюсов: работает медленнее, потребляет больше токенов, результат нельзя быстро «пощупать» руками в процессе. Сейчас не использую.
Codex CLI — консольный агент от OpenAI для работы с GPT-моделями. Мой основной инструмент. Работает локально и быстро, многое можно настроить. К агенту с топовыми моделями у меня сформировалось доверие, поэтому я запускаю его в yolo-режиме: агент работает с расширенными правами и не просит подтверждение на каждый шаг. Главный минус — терминальный интерфейс.
Claude Code — консольный агент от Anthropic для работы с моделями семейств Opus, Sonnet и Haiku. В нём часто первыми появляются новые агентские идеи. С «родными» моделями нормально попробовать не получилось. Связка с GLM-4.7 мне не зашла.
Сначала я смотрел на развитие Claude Code и Codex CLI и недоумевал, почему в Codex CLI так мало фич. Потом понял: то, что в Claude Code часто делается через хуки (hooks, обработчики событий) и другие механизмы, в Codex CLI можно закрывать инструкциями в AGENTS.md. Модели Codex лучше слушаются инструкций, поэтому им нужно меньше внешней обвязки.
Я согласен с мнением Mario Zechner, создателя Pi: Claude Code постепенно усложняется и превращается в «spaceship» вроде автомобиля Гомера Симпсона. Возможностей много, но в среднем пользуешься малой частью этого космического корабля, а остальное становится тёмной материей — непонятно, что делает и как влияет на результат.

Источник: фрагмент выступления Mario Zechner.
Gemini CLI — консольный агент Google под семейство Gemini-моделей. Есть free tier: у меня его обычно хватало на 1–2 задачи в день на сильных моделях. Хорош для текстов и документации. Например, помогал с текстами и переводами для task-agents-playbook. Код в моём окружении пишет слабее. Помню, как Gemini 2.5 похерил мне проект в ходе массового исправления проблем, которые нашёл Psalm после обновления.
Antigravity — IDE от Google, форк VS Code с агентом. Работает с Gemini-моделями и ограниченным набором других моделей. Когда я пробовал, был free tier. На момент моего теста продукт был сырым, с неприятными багами, и я не стал дальше им пользоваться.
Aider — один из ранних консольных агентов со своим характером. У него был свой лидерборд моделей для задач редактирования кода, и за этим было интересно следить. Последний официальный релиз был 10 августа 2025 года, но свежие коммиты в репозитории есть. Жаль, если развитие просто заглохло; возможно, это пауза перед чем-то новым.
OpenCode — консольный агент со своей экосистемой моделей и тарифами. Насколько помню, там есть бесплатные модели, свои недорогие подписки и возможность использовать локальные модели. Я довольно много пользовался им в паре с GLM-моделями от Z.ai. Продукт неплохой, но у меня заметно ел токены. Консольный интерфейс навороченнее, чем у Codex CLI, но не факт, что удобнее: в терминале часто чем проще, тем лучше. В пользу OpenCode говорит и то, что Kilo Code перешёл на его ядро. Про опыт с ним я писал в статье «ИИ-агент для финансовой аналитики» и про SKILLs в OpenCode.
Qwen Code — консольный агент, форк Gemini CLI под Qwen-модели от Alibaba. Пробовал после выхода Qwen-3.6: кодил достойно. Тогда был free tier на 1000 запросов в день, потом его убрали.
RooCode — расширение VS Code с большим количеством настроек. Есть семантический поиск по проекту: он помогает, когда не помнишь точное название класса или ищешь по документации внутри репозитория. Для больших кодовых баз это важно. Проект развивался очень динамично: иногда выходило по несколько релизов в день. Я не стал завязываться на инструмент с таким темпом изменений: боялся потерять стабильность. Жаль, потому что продукт был интересный. В 2026 году команда объявила sunsetting Roo Code и переключилась на Roomote.
Kilo Code — расширение VS Code. Изначально был форком RooCode, потом расширение пересобрали вокруг Kilo CLI, а сам Kilo CLI в README называют fork of OpenCode. Я активно пользовался Kilo до этого перехода, но в новой версии сначала не перенесли главное для меня — семантический поиск. Недавно его вернули как Codebase Indexing / semantic_search, но он пока экспериментальный, и продукт ещё сыроват. Всё равно слежу за Kilo как за достойным кандидатом: мне нравились режимы Ask и Architect, а ответы с Mermaid-диаграммами на порядок лучше объясняли ход мысли агента. Свой опыт описывал в статье «Первый опыт с GLM-5».
Pi — минималистичный консольный агент от Mario Zechner. На фоне таких монстров, как Claude Code, мне нравится его обратная философия: маленькое ядро, расширяемость, пользователь сам достраивает нужное — при желании строит свои космические корабли 😎. Разработчик Pi концентрируется на ядре, а остальное отдаёт в расширения самим пользователям. Последний месяц я активно использую Pi на проекте task-orchestrator.
Модели и мои текущие подписки
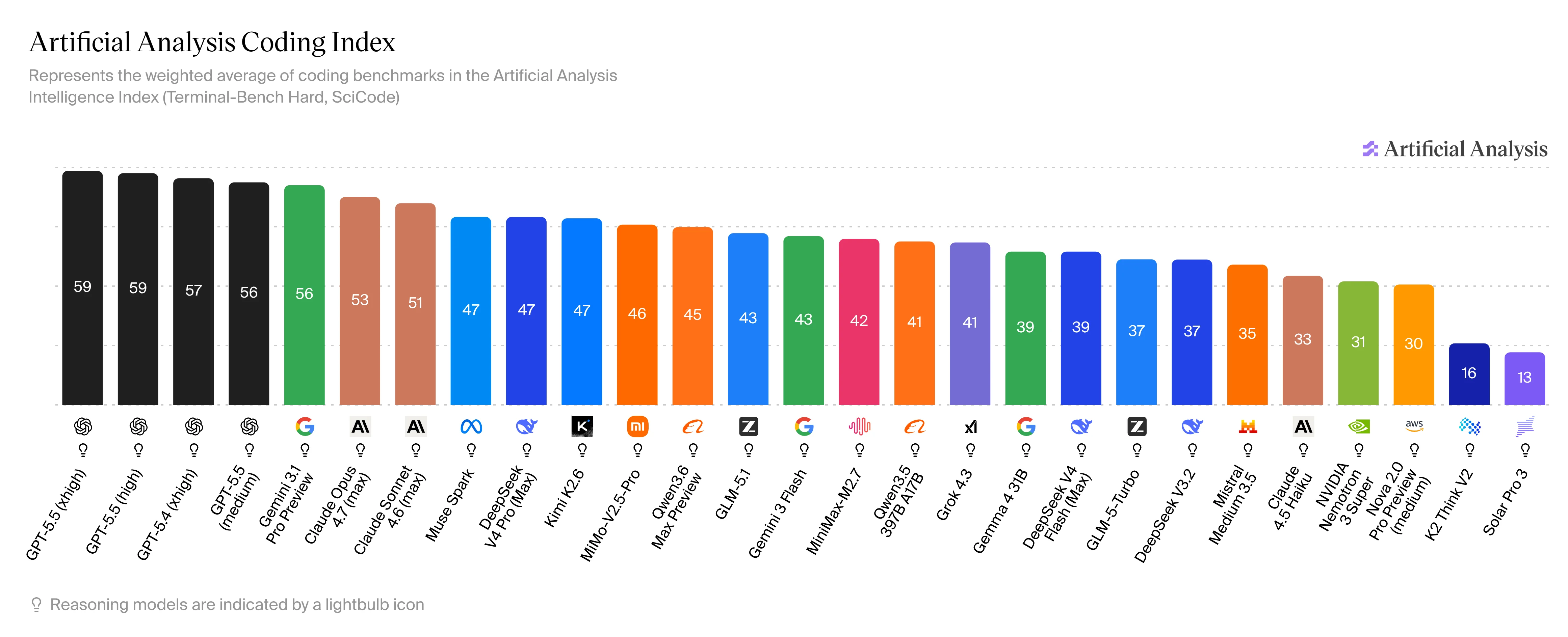
Artificial Analysis Coding Index один из ориентиров, куда смотреть по coding-моделям.
Моделей выходит слишком много, все проверить в работе не получается. После анонсов новых моделей я смотрю их позицию в рейтингах вроде Artificial Analysis Coding Index и решаю, стоит ли пробовать модель в работе.
Пробовал китайские модели от DeepSeek, Qwen, MiniMax и Z.ai, отдельно — Gemini от Google. На GLM-модели от Z.ai я подсел, когда они хорошо показали себя в моём процессе.
На момент написания статьи у меня рабочие связки такие:
- Codex CLI с GPT-моделями:
gpt-5.5 xhigh fast,gpt-5.5 high fastи вариантами безfast. Это мой топ, но лимитов хватает впритык и выходит дороговато; - Pi с GLM-5.1 от Z.ai. Это простая рабочая альтернатива для задач, где я не парюсь о лимитах. На моих задачах GLM-5.1 показывает себя не хуже GPT-5.5.
По подпискам у меня сейчас так: OpenAI Pro за $100 хватает впритык на кодинг в 2–3 терминалах. У Z.ai — квартальная Pro-подписка за $90 ($30 в месяц), но цены у них часто меняются. Думаю вернуться на Lite: лимитов раньше хватало, не хватало скорости.
Я веду несколько параллельных терминалов под разные задачи, с короткими сессиями, чтобы не раздувать контекст.
Слишком большой контекст ухудшает управляемость сессии. Длинная сессия работает как снежный ком: чем она дольше, тем больше токенов потребляет каждый следующий шаг и тем быстрее заканчиваются лимиты. Иногда правильнее стартовать новую сессию и дать агенту короткую, чистую задачу.
С GLM у меня был неприятный эффект: при контексте больше 100K модель иногда начинала «бредить» в рассуждениях, коверкать слова и уходить в длинный цикл. Поэтому я ограничивал контекст в конфигурации агента. В последние недели проблема стала встречаться реже, но я всё равно не люблю огромные сессии.
Что я хочу от идеального агента
После всех экспериментов у меня сложился список требований к агенту, с которым удобно работать через CLI/TUI.
Минимальный список:
- CLI/TUI-интерфейс. Мне удобнее, когда агент работает в терминале. На GUI-агентов я посматриваю, но пока они кажутся сырыми, медленными и прожорливыми по процессору и памяти.
- Skills / инструкции. Сейчас это лучший способ с минимальными затратами дать агенту навык — умение правильно делать что-то полезное: от рабочих правил проекта до отдельных сценариев, инструментов и специализированных действий.
- Tools. Должна быть возможность добавлять свои tool calls — сейчас это чаще всего делают через MCP.
- Управление стартовым контекстом. Агенту нужно быстро дать нужный минимум контекста для задачи, не раздувая сессию с первых сообщений. В Codex CLI часть контекста уже приходит из базового промпта модели. Например, в
base_instructionsдля GPT-5.5 лежит большой блок про поведение, дизайн, frontend-рекомендации и даже запреты уровня «не говорить про гоблинов». Когда я сам описываю стиль, правила проекта и поведение агента вAGENTS.md, такой базовый контекст может быть лишним или конфликтовать с моими инструкциями. - Расширяемость и кастомизация. Агент должен позволять менять и достраивать функциональность под мой процесс, а не только работать в заранее заданных режимах.
- LSP или аналог. Навигация по коду должна быть умнее
grep. Mario Zechner критиковал использование LSP в OpenCode, но мне такая возможность кажется полезной фичей. - Семантическая индексация. Особенно для больших проектов: агенту нужно находить релевантный код даже по неточному описанию или неполному названию класса, а документацию — по смыслу. В Kilo Code это хорошо работало.
- Поддержка разных провайдеров. Локальные модели, облачные модели, запасные варианты на случай лимитов.
- Free tier или дешёвый вход. Новые модели хочется проверять до того, как они начнут есть бюджет.
Как я выстроил работу с агентами
Входной контекст
Память агента
У ИИ-агента нет памяти о прошлом. Она ограничена текущей сессией общения. Новая сессия — и всё заново: агент погружается в проект так, будто видит его в первый раз.
Я уже писал про это в статье «Память и контекст: уроки из художественных историй для сознательного ИИ». Очень рекомендую посмотреть фильм «Мементо»: главный герой не помнит, что было 15 минут назад, и вынужден строить систему внешних подсказок. Фильм хорошо показывает, как такая система помогает не забывать важное и к чему приводят ошибки в организации памяти.
С ИИ-агентами похожая ситуация. Всё, что ниже написано, — способ помочь агенту быстро погружаться в проект снова и снова: с меньшим контекстом, меньшими затратами токенов и меньшим количеством повторных объяснений. Это обычно называют context management / context engineering (управление контекстом).
В моём процессе у памяти агента различаются горизонты:
- Краткосрочная — текущая сессия. В ней живёт обсуждение конкретной задачи. Я стараюсь держать её короткой и закрывать после завершения работы.
- Среднесрочная — эпики и задачи в
todo/. Там хранится рабочий контекст: цель, критерии, PR, история изменений, зависимости. - Долгосрочная —
AGENTS.md,docs/, роли и конвенции. Это правила проекта, архитектура, процессы, решения и инструкции.
Всё как у людей.
AGENTS.md Как конституция проекта
Файл AGENTS.md работает как точка входа, роутер к инструкциям и «конституция» для ИИ-агента.
В нём лежат:
- Миссия и приоритет правил. Это помогает агенту понимать, что важнее, если инструкции конфликтуют.
- Роль — выбор специализированной роли перед началом работы. Так агент смещает фокус и смотрит на задачу под нужным углом.
- Рефлексия — оценка сложности задачи, контекста и рисков. Это помогает агенту не сразу бросаться писать код, а сначала подумать и при необходимости задать уточняющие вопросы.
- Язык общения с пользователем — правила общения и именования. Агенты любят притаскивать английские фразы и термины; я прошу минимизировать это.
- Архитектура проекта — стек, инфраструктура, структура папок, миграции, модули и слои.
- Работа с кодом — Git-flow, ветки, задачи, техдолг.
- Tests and Validation — виды тестов и инструменты проверки.
- Предварительные проверки — требования перед сдачей задачи.
- Формат коммитов и Pull Requests — как оформлять коммиты и PR, в какой последовательности действовать.
- Документирование — что и как документировать в проекте.
- Что запрещено — явные запреты, которые помогают модели не делать то, что она может сделать.
- Мини-чеклист для self-review (самопроверки) — список обязательных действий перед сдачей результата. Он помогает модели не забыть важные действия.
Главное правило: не раздувать корневой AGENTS.md. В корне я держу только самые главные правила и ссылки на второстепенные инструкции.
Проектные знания и правила получаются переносимыми, так как живут не в MCP, Skills или специальных фичах конкретного агента, а в обычных markdown-файлах. Если агент читает AGENTS.md, он уже может работать по моим правилам. Поэтому Pi с GLM-5.1 без дополнительных надстроек на моих задачах держится на уровне Codex CLI с GPT-5.5 xhigh.
Роли агентов
В зависимости от задачи агент берёт роль. Роль задаёт фокус, документы и критерии качества.
Примеры ролей из моего процесса:
- Маркетолог — стратегия продвижения, воронки привлечения, аналитика рынка и рост метрик;
- Сейлз — продажи, конверсия пользователей, консультации и фидбек рынка;
- Product Owner — формулирует бизнес-цель, ценность и критерии приёмки;
- Юрист — правовая экспертиза, privacy/compliance, пользовательские соглашения;
- Team Lead — задаёт подход реализации, оценивает риски и стандарты качества;
- System Analyst — уточняет требования, сценарии, ограничения и edge cases;
- System Architect — проектирует и проверяет архитектуру, границы модулей и интеграции;
- UI/UX Designer — проектирует UX-flow и UI-компоненты;
- Copywriter — пишет тексты интерфейса, microcopy и сообщения ошибок;
- Backend Developer — реализует серверную логику: DDD, Application/Domain, API, Messenger;
- Frontend Developer — реализует UI: Twig, Turbo, Stimulus, AssetMapper, CSS/JS;
- DevOps Engineer — отвечает за контейнеры, окружения, CI/CD и инфраструктурные make-команды;
- Backend Reviewer — ревьюит PHP, DDD, архитектуру, стиль, тесты и безопасность;
- Frontend Reviewer — ревьюит UI/JS, Turbo/Stimulus, UX и доступность;
- DevOps Reviewer — ревьюит Compose, CI/CD, безопасность и воспроизводимость;
- QA Backend — проверяет use cases/API, тест-планы, unit/integration тесты;
- QA Frontend — проверяет UI-сценарии, e2e, кроссбраузерность и регресс;
- Technical Writer — обновляет документацию, гайды и описание контрактов.
Примеры обращения к ролям в запросе:
Бэкендер, возьми в работу задачу из todo/EPIC-status-page.todo.md;Копирайтер, проверь тексты в PR;Фронтендер, сделай ревью.
Роль помогает агенту сместить фокус в нужную область и посмотреть на задачу под нужным углом.
Всё как у людей.
Задачи и документы проекта
Задачи как спецификации
Свой процесс я называю Task-driven development — разработка, управляемая задачами как спецификациями.
Идея простая: задача становится единицей истины.
Задача описывает:
- цель;
- историю и контекст задачи;
- границы: что входит в scope и что не входит;
- критерии приёмки;
- обязательные проверки;
- требования к тестам;
- ссылки на контекст;
- ограничения по архитектуре;
- ожидаемый формат результата.
Если нужна большая фича, я оформляю эпик. Эпик декомпозируется на атомарные задачи. Каждая задача проходит свой цикл: постановка → реализация → self-review (самопроверка) → ревью ролью → PR → моё финальное ревью → merge.
Термин spec-driven development используют по-разному. В современных AI-инструментах вроде GitHub Spec Kit или Kiro Specs это обычно отдельный слой артефактов: требования, дизайн, план и список задач. У меня проще: я не развожу отдельный spec-пайплайн. Спецификация упакована прямо в задачу: история, границы, критерии приёмки, проверки и ссылки на контекст. В этом смысле таска = spec.
Это хорошо подходит для агентов: задачу можно положить в репозиторий, связать с PR, обновлять по мере работы и передавать между ролями. Агент получает не расплывчатое «сделай красиво», а цель, границы, контекст и проверки.
Tasks as Code: задачи как код
Для постановки задач использую файловую систему. В корне проекта лежит папка todo/, внутри — markdown-файлы задач и эпиков. Папка находится рядом с кодом и под управлением Git, поэтому задача становится частью контекста проекта: агент может открыть её как обычный файл, передать между ролями, связать с PR и видеть изменения вместе с кодом.
По аналогии с Docs as Code я называю этот подход Tasks as Code. В нашей классификации памяти такая задача становится среднесрочной памятью агента.
Чтобы не копировать правила из проекта в проект, я вынес их в отдельный репозиторий todo-md:
Задачи не являются источником долгосрочных знаний на проекте. Основной источник знаний — хорошо написанный код и минимально необходимая документация. Задачи я не храню вечно: после релиза удаляю. Если что-то нужно сохранить надолго, лучше вынести это в docs/; подробнее про это ниже.
Всё как у людей.
Документация как Memory Bank
ИИ-агент хорошо справляется с изучением того, что делает код. Хорошо написанный код становится самодокументирующим. Но есть знания, которые сложно или невозможно достать из кода: зачем продукт существует, кто пользователь, какие решения уже обсуждались, почему выбрали такую архитектуру, какие сценарии считаются критическими, как деплоить, где границы MVP и MMP.
Поэтому наряду с инструкциями для ИИ-агента и задачами на проекте появляется документация. В среде разработчиков, которые используют ИИ, её часто называют Memory Bank.
К этой документации я отношу:
Vision.md— видение продукта, целевая аудитория, ценность и принципы;Mission.md— миссия и ценностный фундамент продукта;Strategy.md— бизнес-цели и стратегии их достижения;MVP.md— Minimum Viable Product, минимальная версия для проверки идеи;MMP.md— Minimum Marketable Product, минимальная версия для выхода на рынок;StoryMapping.md— user story map с backbone activities и release slices;- ADR — описание и назначение архитектурных решений;
- документация по модулям;
- SDLC — Software Development Life Cycle с распределением по ролям;
- описание инфраструктуры сред разработки, тестирования и продакшена;
- инструкции по деплою;
- компоненты темы для построения UI;
- пользовательская документация по работе с системой.
Документации по проекту много, поэтому агенту нужно подсказывать, когда и какой документацией пользоваться. Я решаю это через роли: для каждой роли даю разные наборы документов на входе, а агент в зависимости от запроса сам решает, что подтянуть. Пример — роль Product Owner, где есть ссылки на такие документы.
Всё как у людей.
Архитектура, правила и качество
Модульный монолит
Модульный монолит с изоляцией, написанный по принципам DDD, хорошо подходит для разработки с ИИ-агентами: агенту проще собрать нужный контекст, меньше искать по проекту и тратить меньше токенов и времени.
Что в этом помогает:
- весь код в одном репозитории;
- модули разделены по предметным границам;
- принцип
High cohesion, low couplingуменьшает необходимость залезать в чужие модули и классы; - единый язык предметной области облегчает навигацию;
- CQRS разделяет сценарии чтения и записи.
С PHP у меня большой опыт, поэтому мне проще делать финальное ревью, проектировать архитектуру и проверять реализацию. Плюс современный PHP даёт нормальные типы, строгую типизацию через declare(strict_types=1), readonly, enum, Composer и большую экосистему инструментов и библиотек.
Symfony дополняет это зрелым каркасом для сложных приложений: контейнером зависимостей, консольными командами, очередями через Messenger, валидацией, сериализацией, HTTP-клиентом, тестовой инфраструктурой и механизмами, на базе которых можно выстраивать модульную архитектуру.
Тесты
Важная часть процесса разработки с ИИ-агентами — наличие тестов: Unit, Integration, E2E, Smoke.
Для тестирования использую несколько уровней:
- Unit — быстрые тесты классов. Не используют БД и внешние сервисы. Их нужно писать много: они помогают сохранять вычислительную целостность класса при изменениях. Запускаются в тестовом окружении.
- Integration — проверяют взаимодействие слоёв и инфраструктуры. Требуют тестовую БД, но без взаимодействия с внешними сервисами. Из-за БД работают медленнее, поэтому ими стоит покрывать важные участки кода. Запускаются в выделенном тестовом окружении с отдельной БД.
- E2E — проверяют пользовательские сценарии и критические части пользовательского пути. Требуют БД, иногда взаимодействия с внешними сервисами. Они медленные, поэтому я запускаю их при изменении покрытого функционала и перед релизом. Запускаются в отдельном e2e-окружении с отдельной БД и своими настройками.
- Smoke — минимальный набор быстрых ручных проверок текущей конфигурации проекта. Отвечают на вопрос: подсистема или компонент вообще в рабочем состоянии? Используются только для ручного запуска, когда нужно быстро проверить часть системы.
Для запуска Unit, Integration, E2E и части Smoke-тестов использую PHPUnit. Пример конфигурации держу в coding-standard. Smoke-проверки также оформляю как Smoke Commands — консольные команды для ручного запуска.
Всё как у людей.
Конвенции: Coding Standard
Конвенции — набор правил и соглашений, которые регулируют стиль, структуру кода и архитектурные подходы. Они помогают держать код единообразным, читаемым и удобным для поддержки.
Для удобства подключения к своим проектам я вынес конвенции в отдельный публичный репозиторий coding-standard.
Агентам тяжело стабильно следовать большому своду правил: они могут привнести что-то своё, не попасть в стиль проекта, нарушить изоляцию слоёв или начать раздувать слои, которые должны быть тонкими. Поэтому часть конвенций я закрепляю автоматическими проверками: правилами для Deptrac и снифами для PHPCS.
Для поддержки чистоты кода использую утилиты:
| Утилита | Пример конфигурации | Цель | |
|---|---|---|---|
| PHP_CodeSniffer | phpcs.xml.dist |
Проверка code style | |
| Psalm | psalm.xml |
Статический анализ типов | |
| Deptrac | depfile.yaml |
Проверка архитектурных зависимостей | |
| PHPMD | phpmd.xml |
Поиск проблемного кода |
Всё как у людей.
Git workflow
Git workflow — набор правил по работе с ветками, оформлению коммитов, PR и релизов. Я явно описываю агенту: какую ветку создать, как оформить коммит, когда открыть PR и что проверить перед merge.
Формат коммитов тоже проверяю автоматически: локально и в CI. Это ещё один feedback loop: агент оформил коммит, проверка показала проблему, агент исправил сообщение и повторил проверку.
Всё как у людей.
Feedback loop для агента
В feedback loop — цикле обратной связи — я использую тесты, статические анализаторы и утилиты для автоматической проверки конвенций. Агент создаёт, меняет или удаляет код, запускает проверки и получает детерминированный результат. Если проверка не прошла — агент смотрит вывод, исправляет код и запускает проверки снова. Если проблем нет, он выходит из цикла.
Чем больше проверок агент проходит до сдачи задачи, тем меньше остаётся ручной проверки на финальном ревью.
Утилиты: одна команда для проверок
Агенту нужны детерминированные команды. Если проверка состоит из десяти ручных действий, он забудет один шаг или запустит не те параметры. Поэтому я использую Makefile.
Пример:
check: cs psalm deptrac test
cs:
vendor/bin/phpcs
psalm:
vendor/bin/psalm
deptrac:
vendor/bin/deptrac analyze
test:
vendor/bin/phpunitВ AGENTS.md достаточно написать:
После завершения работы над задачей перед финальным ответом пользователю запусти `make check`.
Если `make check` упал — исправь причины падения и запусти его снова.
Сдавай задачу только после успешного `make check`.Это и есть feedback loop: агент сделал изменения, запустил проверки, исправил найденные проблемы, повторил запуск и вернул задачу только после успешных проверок.
Процесс работы
Планирование
Обычно работа начинается с постановки задачи или эпика. Код идёт следующим шагом.
Пример запроса:
Возьми на себя роль аналитика. Мне нужна status page для проекта. Сделай эпик для этой задачи.Дальше процесс такой:
- Запрос. Я задаю роль и цель.
- Генерация. Агент загружает роль, правила постановки задач, шаблоны и пишет эпик.
- Self-review (самопроверка). Прошу агента перепроверить себя и исправить слабые места.
- Review. Прошу другую роль проверить задачу: архитектора, ревьювера, QA, девопса.
- Создание PR. Агент оформляет изменения отдельной веткой и PR.
- Final Review. Я сам читаю постановку и даю замечания.
- Закрытие. Агент мержит PR, удаляет ветку, возвращается на master и ждёт следующую команду.
«Лучше один день потерять, чтобы потом за пять минут долететь»
— народная мудрость
Плохая постановка задачи почти гарантирует плохое решение. Хорошая постановка не гарантирует идеальное решение, но уменьшает цикл «проверка → правка» на финальном ревью.
Реализация
Реализация похожа на планирование, только вместо текста задачи агент меняет код.
Пример запроса:
Бэкендер, возьми в работу задачу из todo/EPIC-status-page.todo.md.Дальше:
- Запрос. Даю роль и файл задачи.
- Реализация. Агент пишет код, тесты, миграции, документацию.
- Проверки. Запускает PHPUnit, PHPCS, Psalm, Deptrac, PHPMD, Composer или
make check. - Self-review (самопроверка). Сам проверяет своё решение.
- Role review. Другая роль смотрит архитектуру, тесты, UX или инфраструктуру.
- PR. Агент создаёт pull request.
- Финальное ревью. Я читаю результат и прохожу с агентом цикл «замечание → правка».
- Merge. Агент мержит, удаляет ветку, возвращается на master.
- Релиз. Перед релизом агент запускает e2e, готовит changelog и тег. Прод выкладываю сам.
Ценность такого процесса — в разделении этапов. Агент не делает всё одним прыжком: сначала реализует, потом проверяет себя, потом отдаёт результат другой роли и только потом передает человеку на финальное ревью. Такое разделение этапов в купе с предварительным планированием задачи повышает качество реализации и уменьшает время потраченное человеком на финальном ревью.
Финальное ревью
На финальном ревью я смотрю не столько саму реализацию, сколько соответствие кода правилам проекта: конвенциям, изоляции модулей, принципу High cohesion, low coupling, предметным границам и единому языку предметной области.
Ещё проверяю то, что пока не перенесено в детерминированные инструменты: странные решения, лишнюю сложность, нарушения безопасности и явную дичь. Если что-то кажется неправильным, обычно спрашиваю агента, почему он сделал именно так. Дальше либо соглашаюсь, либо агент переделывает.
Код тестов почти не смотрю: открываю редко, когда нужно проверить конкретный сценарий или причину падения.
Отдельно проверяю оформление PR. Например, мне важно, чтобы агент ставил на PR свою метку: по этим меткам потом строятся отчёты по доле работы агентов.
Правки в правилах для агентов читаю внимательнее обычного кода. Хорошее правило даёт большую отдачу, но агенты не всегда хорошо пишут правила для самих себя: часто получается многословно и не по сути. Думаю, это можно улучшить, если потратить время и научить агентов писать такие правила лучше. Пока такие правки я предпочитаю вычитывать руками.
На финальном ревью я также фиксирую повторяющиеся ошибки агентов. Потом из них рождаются новые правила, проверки и уточнения процесса.
Ретроспектива
Ретроспектива нужна, чтобы повышать автономность и качество работы агента. Я смотрю, какие проблемы повторяются, и превращаю их в правила, проверки, шаблоны или уточнения процесса.
Цикл такой:
- Наблюдение. Смотрю работу агента в процессе и на ревью. Фиксирую сбои, недопонимание контекста, лишние действия и ошибки.
- Анализ. Выделяю повторяющиеся паттерны, которые тратят время и токены. Ищу системное решение: что изменить в инструкции, шаблоне или инструменте, чтобы ошибка не повторялась.
- Улучшение. Вношу точечную правку в
AGENTS.md, роль, шаблон задачи, документацию, конфиг линтера, Deptrac-правило, сниф или тест.
Важно соблюдать принцип изолированных изменений. Не менять всё сразу — так невозможно отследить влияние конкретной правки. Улучшения нужно внедрять малыми порциями и сразу проверять эффект.
Пример реального эпика и результата: эпик status page и его реализация на task.ai-aid.pro.
Метрики результата
Что получилось в цифрах
Код руками я почти перестал писать. Возникает важный вопрос: выросла ли продуктивность?
Чтобы ответить на него, я начал собирать детальные метрики по проекту TasK, потому что в основном занимаюсь его разработкой. Дополнительно смотрю общие метрики по остальным моим проектам на GitHub.
Размер проекта на 13 мая 2026 года
| Language | Files | Lines | Blanks | Comments | Code | Complexity | LPF |
|---|---|---|---|---|---|---|---|
| PHP | 5 985 | 398 495 | 61 695 | 25 693 | 311 107 | 8 554 | 67 |
| Markdown | 562 | 59 330 | 12 369 | 0 | 46 961 | 0 | 106 |
| Twig Template | 252 | 20 657 | 1 450 | 0 | 19 207 | 799 | 82 |
| YAML | 199 | 14 168 | 676 | 447 | 13 045 | 0 | 71 |
| Plain Text | 43 | 10 248 | 106 | 0 | 10 142 | 0 | 238 |
| JavaScript | 37 | 7 158 | 1 164 | 247 | 5 747 | 802 | 193 |
| Shell | 29 | 2 194 | 315 | 164 | 1 715 | 247 | 76 |
| BASH | 16 | 596 | 82 | 26 | 488 | 90 | 37 |
| JSON | 16 | 9 467 | 0 | 0 | 9 467 | 0 | 592 |
| HTML | 9 | 148 | 2 | 0 | 146 | 0 | 16 |
| Makefile | 9 | 840 | 147 | 73 | 620 | 32 | 93 |
| CSS | 4 | 538 | 95 | 29 | 414 | 0 | 135 |
| XML | 4 | 300 | 2 | 0 | 298 | 0 | 75 |
| Dockerfile | 2 | 217 | 20 | 6 | 191 | 16 | 109 |
| Sass | 2 | 16 | 0 | 0 | 16 | 0 | 8 |
| Docker ignore | 1 | 16 | 0 | 0 | 16 | 0 | 16 |
| INI | 1 | 12 | 0 | 0 | 12 | 0 | 12 |
| Python | 1 | 180 | 40 | 15 | 125 | 24 | 180 |
| SQL | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| Total | 7 173 | 524 581 | 78 163 | 26 700 | 419 718 | 10 564 | — |
Если грубо перевести этот размер в контекст LLM, получается порядка 5–7 млн токенов. Оценка зависит от tokenizer и состава файлов, но порядок понятен: такой проект нельзя целиком держать в контексте модели. Нужны границы модулей, задачи, документация и проверки, иначе контекст быстро превращается в шум.
Распределение файлов и строк
На графиках видно, что PHP доминирует: 83,4% файлов и 76,0% строк. Но markdown занимает уже заметную долю — 7,8% файлов и 11,3% строк. Это задачи, инструкции, роли, конвенции и документация. Для агентского процесса они стали частью кодовой базы, а не текстом рядом с кодом.
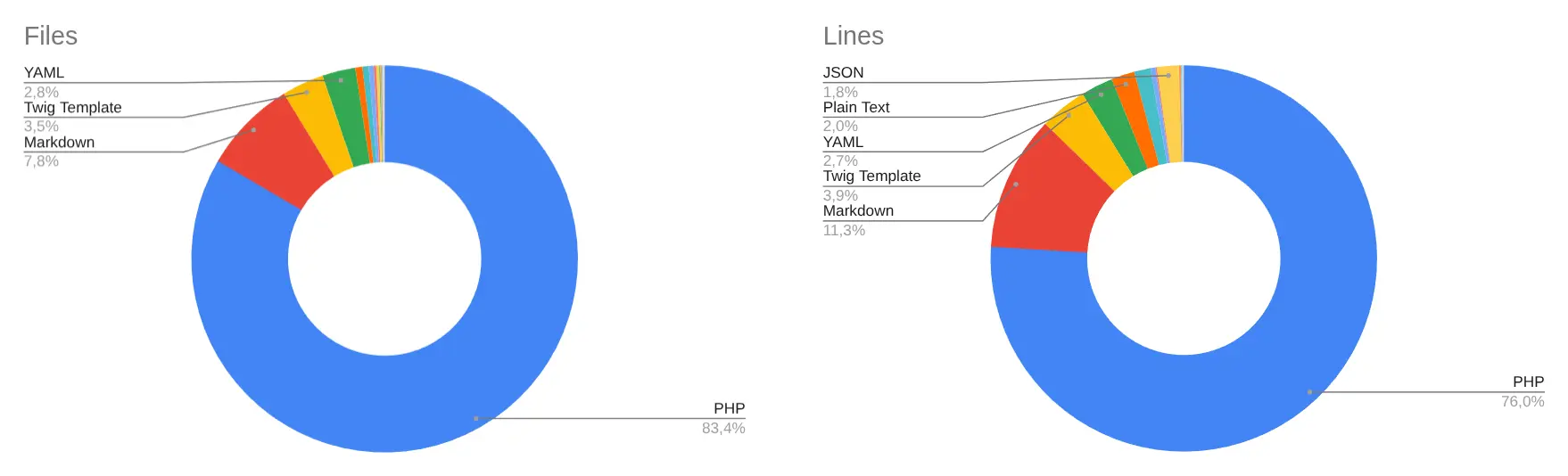
Количество файлов и строк по типам.
Доля агентов в генерации кода
График основан на «задетых» строках из diff: Added + Deleted. До 25-й недели 2025 года (середина июня) почти всё проходило через ручную разработку. После подключения Codex Cloud доля агентского кода быстро стала основной, а дальше начался период подбора инструментов: Codex Cloud сменился Codex CLI, пробовались Kilo Code, OpenCode, Gemini CLI и другие, позже в текущую связку вошёл Pi.
Доля «задетых» строк по неделям: человек и ИИ-агенты.
Сколько кода стали менять агенты
Первый срез — объём изменений в diff по неделям: сколько строк добавлено и сколько удалено. После перехода к агентам столбцы стали выше: в разработку стало попадать больше изменений. Крупные пики удалений связаны в том числе с выносом части решений из основного проекта в отдельные публичные пакеты.
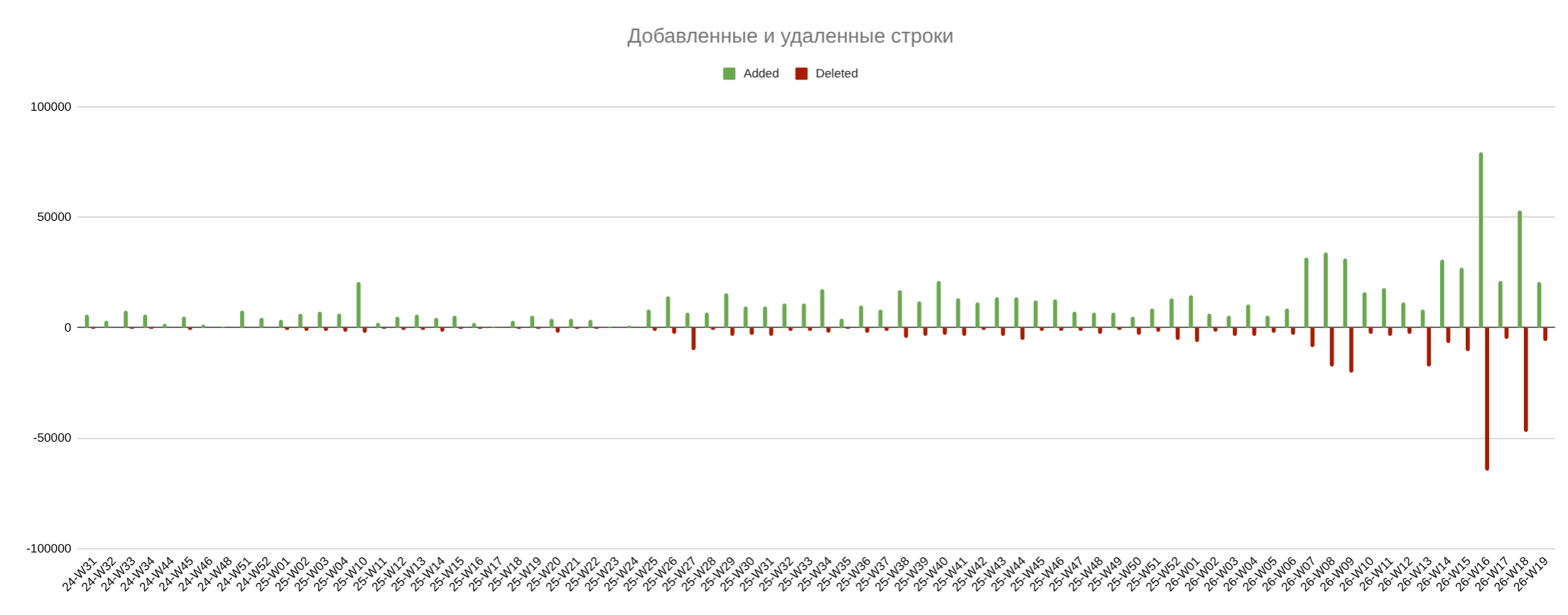
Добавленные и удалённые строки по неделям.
Для ответа на вопрос про продуктивность удобнее сравнить средние значения до и после того, как я начал использовать агентов в проекте. Total — общий объём изменений — вырос примерно в 11,3 раза: с 4,1 тыс. до 46,4 тыс. строк в неделю. Net — чистый прирост — примерно в 4,5 раза: с 2,7 тыс. до 12,2 тыс. строк.
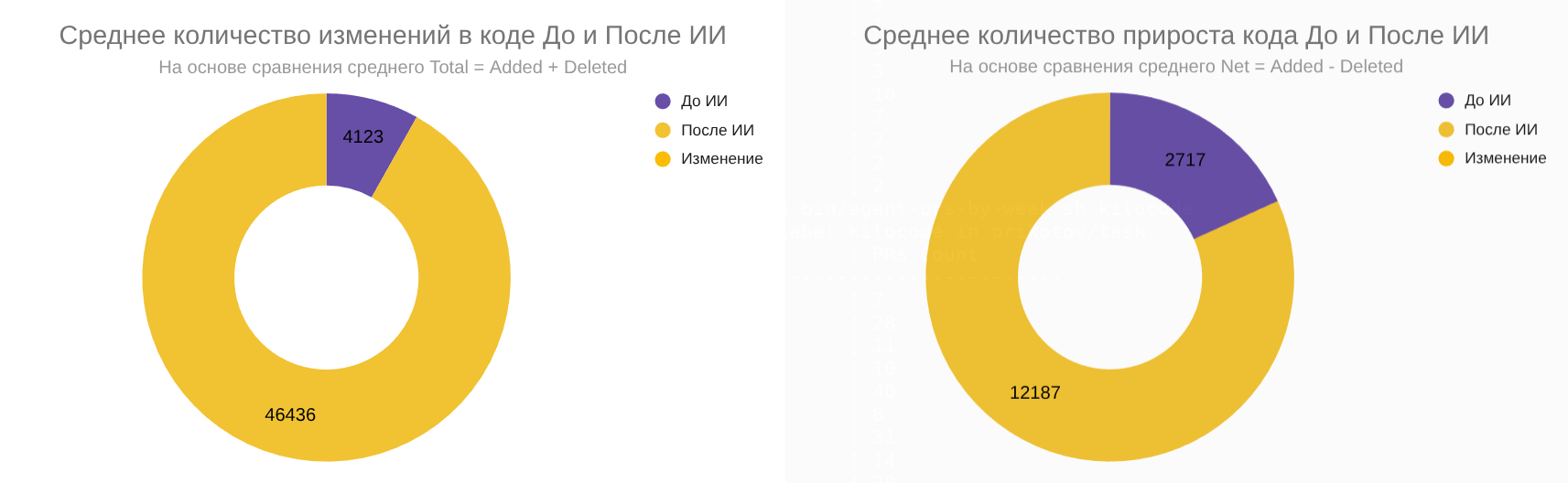
Средние значения до и после перехода на ИИ-агентов.
Разница между Total и Net важна. Она показывает, что рост не сводится к добавлению новых строк. Значительная часть работы — изменения в существующем коде.
Важно не только сколько строк меняется, но и где они меняются. После подключения агентов заметно выросла доля тестов. В 2026 году больше изменений стало приходиться на markdown: задачи, инструкции, роли, конвенции и документация стали рабочей частью проекта.
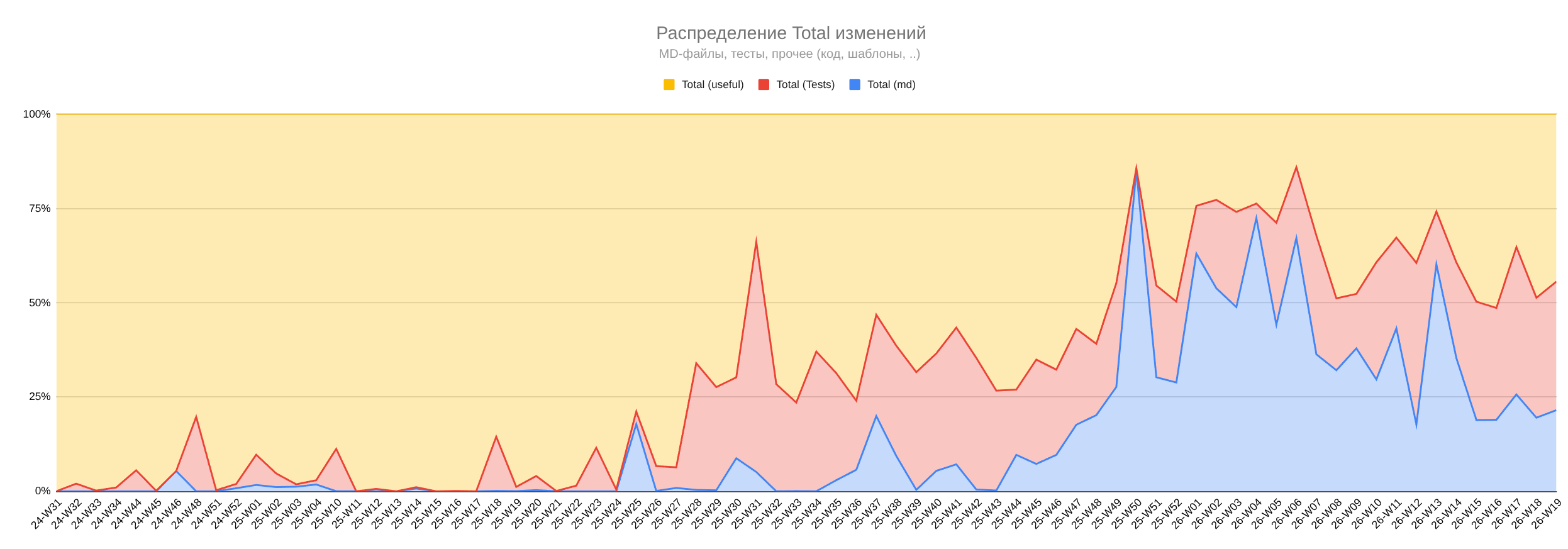
Доли изменений в коде, тестах и markdown по неделям.
Не всё выросло вместе со строками
По коммитам и PR картина спокойнее. После июня 2025 активность выросла, но не в 11 раз. Это другой срез: строки показывают объём изменений, а PR показывают, сколько задач сделано.
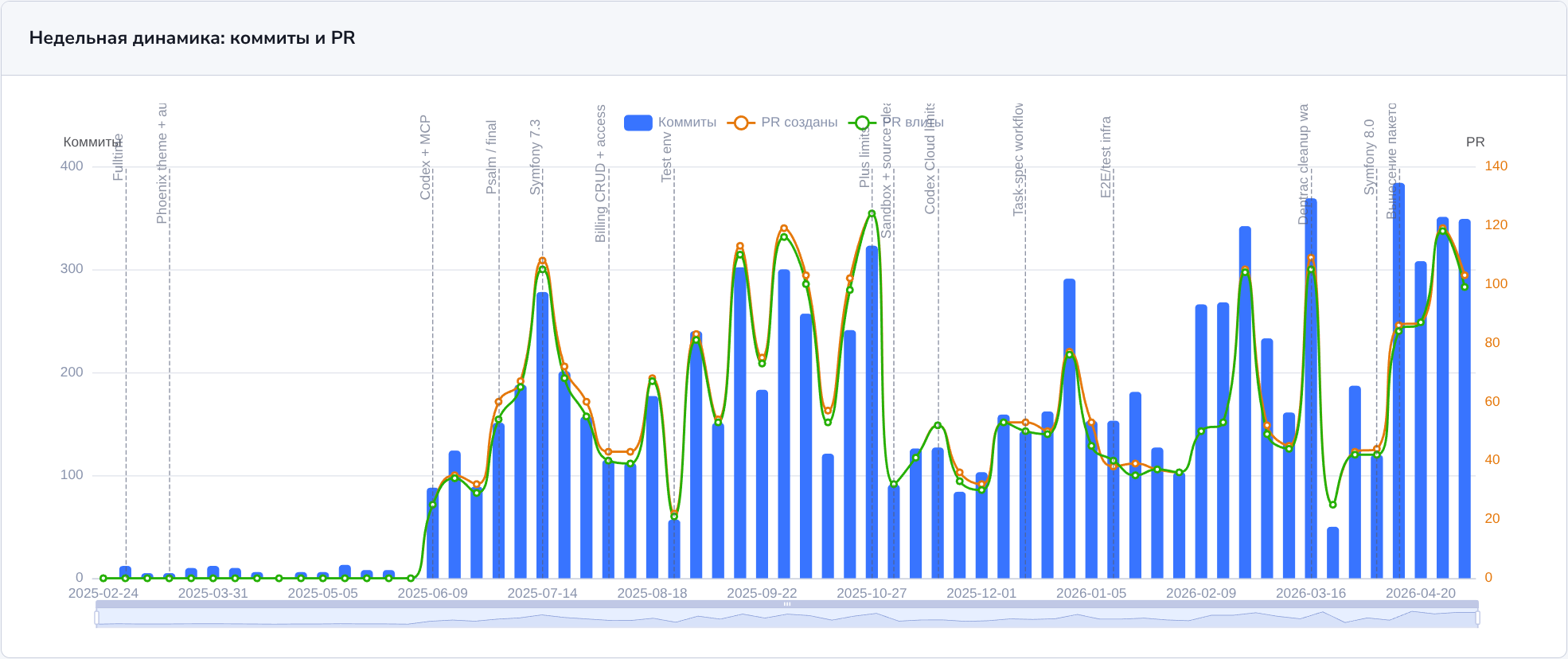
Коммиты и PR по неделям.
В ноябре 2025 года видна яма: тогда в Codex Cloud появились жёсткие лимиты, и я ушёл искать альтернативы. Об этом писал отдельно: «Лимиты Codex Cloud».
Зато изменился размер PR. Их не стало кратно больше, но в отдельные недели через один PR проходит заметно больше строк. Частично это связано с внедрением автоматических проверок кода: после добавления новых правил приходилось массово исправлять проект под эти правила. В конце графика виден ещё и вынос части решений из основного проекта в публичные пакеты.
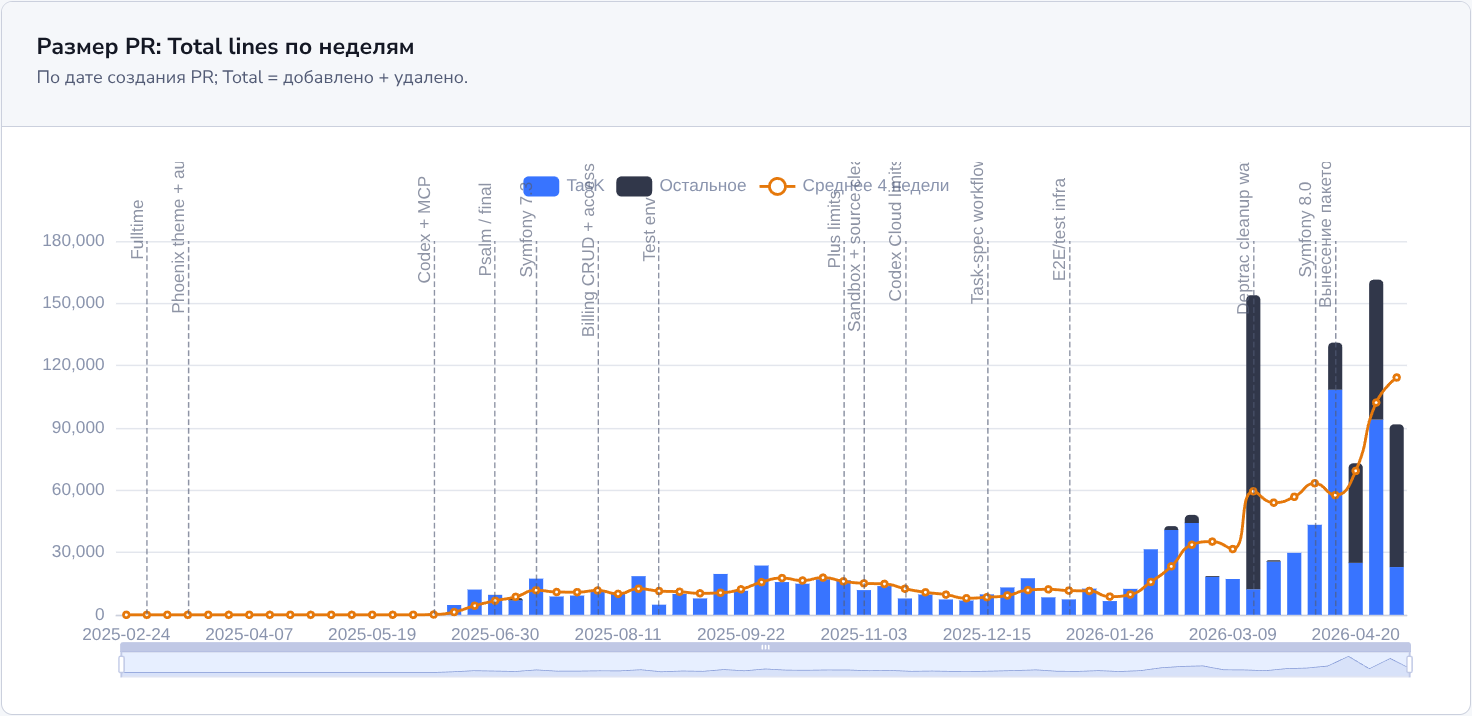
Размер PR по строкам: Added + Deleted.
По цифрам видно:
- производительность выросла, если смотреть на поток изменений;
- тестам, документации и постановке задач стало доставаться больше внимания;
- количество PR не выросло в 10 раз, поэтому узкое место сместилось в оркестрацию и ревью.
Публичные проекты, которые выросли из этого процесса
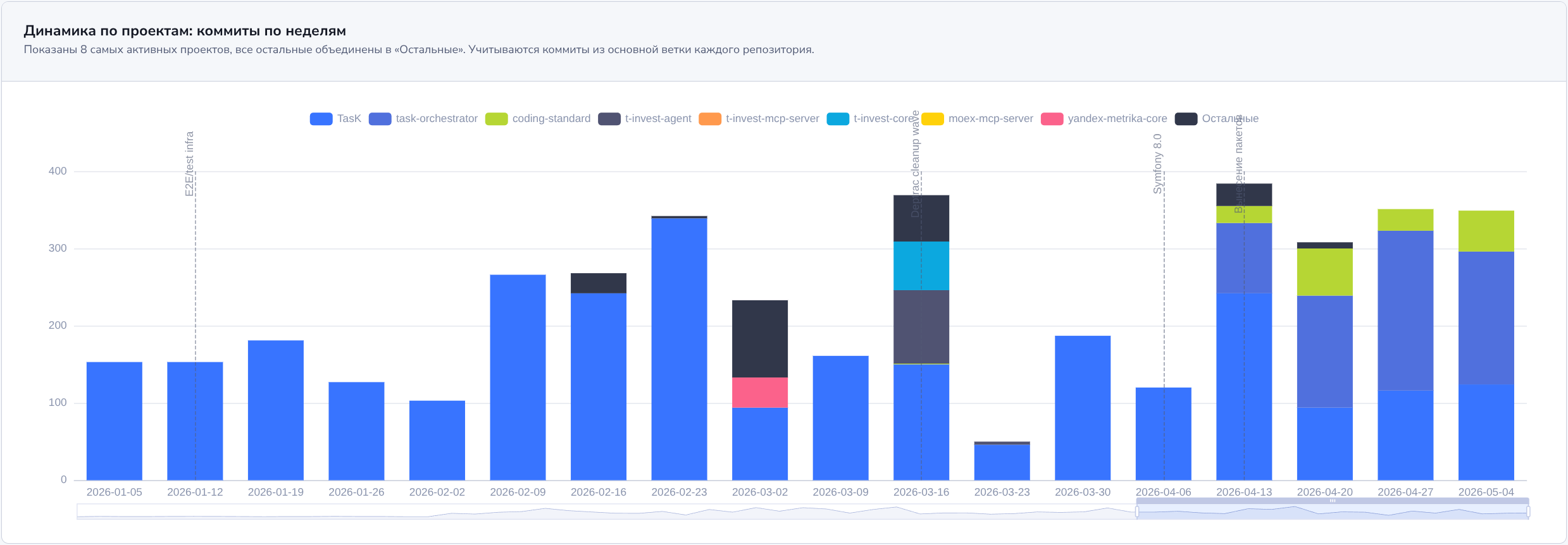
Проект TasK растёт, и часть решений хочется переиспользовать в других проектах. Поэтому я начал выносить независимые куски в публичные репозитории.
TasK Orchestrator
Репозиторий: github.com/prikotov/task-orchestrator
Идея — переложить на оркестратор мою основную боль: вести эпик или задачу по процессу до Final Review. Сама оркестрация — ведение задачи по процессу — не сложная. Тяжело постоянно переключаться, восстанавливать контекст и принимать мелкие решения.
Оркестратор должен стать инструментом, который держит процесс: роли, задачи, проверки, статусы, переходы между этапами. Он должен снять с меня мелочовку и оставить мне то, где действительно нужно моё внимание.
Coding Standard
Репозиторий: github.com/prikotov/coding-standard
Здесь лежат конвенции, примеры конфигураций и инструменты проверки: архитектурные правила, снифы, примеры для Symfony-проектов.
Агент может отклониться от конвенций. Проверка должна поймать отклонение до моего финального ревью.
Todo-md
Репозиторий: github.com/prikotov/todo-md
Это правила и шаблоны для задач. Минимальная система управления задачами через markdown-файлы и Kanban-подход.
Git-workflow
Репозиторий: github.com/prikotov/git-workflow
Правила работы с ветками, коммитами, PR, релизами и деплоем. Агентам нужны такие инструкции, чтобы одинаково выполнять повторяющиеся шаги Git workflow: создавать ветки, оформлять коммиты, открывать PR, ставить свои метки и проходить проверки.
Что хочу улучшить дальше
Сейчас главное ограничение это время. Новые кодовые агенты, модели и подходы выходят быстрее, чем я успеваю пробовать их в деле. По обзорам можно сформировать мнение, но проверять всё равно нужно на реальных задачах. Из-за нехватки времени остановилось развитие части личных проектов, а к ним тоже хочется вернуться уже с агентами.
Поэтому первое, что хочу оптимизировать, это время на ручную оркестрацию: сейчас много времени уходит на ведение задачи по процессу. Для этого я делаю TasK Orchestrator — инструмент, который должен вести задачу по жизненному циклу.
Ещё один способ экономить время — подключать агентов к research (исследованиям). Я стал использовать их для изучения инструментов, чтобы самому не разбирать каждую новую штуку с нуля. Примеры: «Сводная таблица: AI-agent фреймворки и оркестраторы» и «Coding Agents — Сводная таблица сравнения (финальная версия)».
Отдельная тема — безопасность. Нужна защита от попадания секретов в репозиторий. У меня уже был кейс: агент записал в документацию пароль от моего прокси, а я это не заметил.
Та же логика экономии времени тянет агентов за пределы разработки — в инвестиции и создание контента. Про инвестиции писал в статье «ИИ-агент для финансовой аналитики: анализ портфеля Т-Инвестиций на OpenCode», про контент — в «SKILLs в OpenCode: процессный подход к созданию контента». В инвестициях хочу закопаться глубже: нужно улучшать качество управления портфелем, времена непростые.
PHP + AI = ❤️
В PHP-среде AI-разработка пока не выглядит такой активной, как в Python/TypeScript-мире. Я хочу показывать на своём опыте, что ИИ-агенты могут работать и в большом PHP/Symfony-проекте.
Всё, что описал в статье, я пробую на TasK. Если интересно развивать AI-First продукт на PHP — присоединяйтесь как разработчики или первые пользователи. Новости и обсуждения — в Telegram-канале.
Источники и ссылки:
- Мой опыт с Codex: влияние на продуктивность — первый опыт с Codex и замеры влияния на разработку.
- Лимиты Codex Cloud — почему я ушёл от Codex Cloud к CLI-агентам.
- Первый опыт с GLM-5: кодинг через Kilo Code — пример работы с GLM-моделью и Kilo Code.
- ИИ-агент для финансовой аналитики: анализ портфеля Т-Инвестиций на OpenCode — эксперимент с агентом вне разработки.
- SKILLs в OpenCode: процессный подход к созданию контента — как я применял skills для подготовки контента.
- Память и контекст: уроки из художественных историй для сознательного ИИ — статья про память, контекст и внешние подсказки.
- task.ai-aid.pro — проект TasK, на котором я пробую описанный процесс.
- task-agents-playbook — плейбук с ролями, правилами и инструкциями для агентов.
- task-orchestrator — оркестратор задач и эксперименты с research через агентов.
- coding-standard — конвенции, снифы и конфигурации проверок.
- todo-md — правила и шаблоны задач в markdown.
- git-workflow — правила работы с ветками, коммитами, PR и релизами.
- Artificial Analysis Coding Index — рейтинг моделей, на который я смотрю перед пробами новых моделей.
- Codex CLI — мой основной CLI-агент от OpenAI.
- Pi coding agent — минималистичный CLI-агент, который я использую с GLM-моделями.
- Z.ai подписка и тарифы — GLM-модели нормально работают в моём окружении; даже Lite-плана хватает с запасом для обычных coding-сессий.




