AI 编程智能体:我是如何改造项目的
译文:Русский оригинал · English version

“说到底,还是跟人协作一样。”
——民间智慧
先说结论: 过去将近一年,我一直在把自己的项目改造成适合 AI 编程智能体参与开发的形态。最后我的结论很简单:模型很重要,但围绕模型的工程支撑体系更重要——指令、规则、可用工具、角色,以及由测试、静态分析、自查、智能体代码审查组成的短反馈闭环。最终审查仍然由人完成。切换到这套流程之后,变更吞吐量明显上升:每周 diff 中新增行数和删除行数之和增长了 11.3 倍,净代码增长增长了 4.5 倍,同时代码质量仍然保持在可控范围内。
这篇文章我拖了很久。原因很简单:流程一直在变。最开始是 Codex Cloud,后来是 CLI,再后来有了角色、Markdown 任务、检查、约定,以及最早的编排实验。现在它已经像一套可以展示的工作系统了。
一开始我很谨慎:只把小改动交给智能体,然后几乎逐行检查。后来,我慢慢把过去只存在于脑子里的东西搬进智能体指令里:规则、必要上下文、架构限制、验证命令。于是,智能体和模型周围长出了一套工程支撑体系,让它们可以在一个较大的项目里工作。
这篇文章会讲我做了什么,来解决这些问题:
- 不让 AI 智能体写出糟糕代码;
- 新增功能时不破坏旧功能;
- 让智能体遵守指令;
- 不让它忘记项目上下文和过去的决策;
- 减少我检查它工作成果的时间;
- 看清 AI 智能体到底怎样影响我的生产力。
这篇文章写给谁
围绕 AI 编程,有两个声音很大的阵营。
第一个阵营说:“AI 根本不行,真正的开发者肯定做得更好。” 这有点像喝了一次劣质速溶咖啡,就断言咖啡这种东西不行。AI 智能体也类似:如果你把任务直接扔给它,没有上下文、没有做法、项目本身也没有准备好,它就会开始猜你的口味。有时候能猜对。更多时候,它会按自己的理解把菜做出来。
第二个阵营说:“AI 会替代所有人,开发者不再需要了。” 管理者开始幻想没有程序员的团队,程序员开始幻想没有管理者的项目。听起来很爽,但真实工作最后还是会撞到同一堵墙:责任,以及专家对结果的审查。
我更接近中间位置:AI 智能体是专家的放大器。我把 AI 看成工具:需要试、需要研究、需要嵌入工作流程,并通过它放大自己、团队和公司。只买一个模型订阅远远不够。要建立 AI-first(AI 原生)和 AI-friendly(便于 AI 协作)的流程:智能体要拿到上下文,按规则工作,重新检查结果,而且不能脱离人类专家的监督。
对第一个阵营,我会展示我做了哪些事,让 AI 智能体开始更好地工作:给了哪些规则,把哪些上下文放进文件,加了哪些检查,以及哪些地方不能不经验证就相信 AI。
对第二个阵营,我会展示边界在哪里:什么可以交给 AI,什么最好仍然留给人类专家。智能体可以写代码、跑检查、收集上下文、提出方案。结果的责任仍然在人的身上。
这篇文章也写给正在走类似道路的人:正在试、正在折腾、正在调整流程,想看看别人的真实经验,而不是再听一遍“明天所有人都要失业”的噪音。
我与智能体和模型的经验
我是怎么走到 AI 智能体这一步的
差不多一年前,我开始在开发中使用 AI 智能体。我一开始就知道,这件事大概率要靠自己摸索:经验很新,现成规则很少。当时我怀疑 AI 能不能处理大型代码库。简单提问,可以。帮忙想思路,可以。但在真实项目里写代码?我有疑问。
一切从 ChatGPT 订阅和网页端的 Codex Cloud 开始。那时 Codex CLI 已经存在,但从俄罗斯快速跑起来更麻烦。网页端的 ChatGPT 对我可用,所以我先从 Codex Cloud 入手。第一次体验我单独写过:《我使用 Codex 的经验:对生产力的影响》。
然后我被它吸引住了。最初几次会话之后,我在仓库里创建了 AGENTS.md——给智能体看的指令文件。最开始里面只有项目的基础规则,但已经有明显效果:智能体更理解项目结构,能按项目已有风格写代码,也能很好地处理模板化任务。当时 Codex Cloud 还没有单独计费,所以我几乎全天候使用它。
慢慢地,我意识到:可以通过 AGENTS.md 影响代码生成质量。
如果智能体重复犯同一种错误,我就把规则写进 AGENTS.md。文件越来越大。过了一段时间,智能体自己开始抱怨:AGENTS.md 太大,它只能分段阅读。这个信号很明确:我试图把整个项目记忆塞进一个文件里。
于是流程逐渐演化成这样:
- 根目录的
AGENTS.md只保留最重要的规则,并作为二级规则的路由入口; - 次要规则移动到
docs/; - 在那里保存我和智能体都需要的项目信息;
- 文档化那些代码里没有、或者智能体从代码里提取成本太高的知识;
- 不描述模型本来就具备的基础知识。
我甚至尝试给 AI 智能体做技术“面试”:问它 DDD、SOLID、架构层、Symfony、测试、静态分析和 PR 流程。看它在哪些地方回答稳定,在哪些地方混乱,哪些地方需要更明确的输入。基于这些回答,我整理了一张能力矩阵:哪些任务可以交给智能体,哪些地方必须加检查,哪些规则应该马上写进文档。
后来 Codex Cloud 加了限制。我 1–2 天就能用完额度,而在使用量说明里看到 CLI 工具消耗更少。于是我切到 Codex CLI,开始适应终端里的工作流程。
终端很快暴露出日常痛点:
- 做界面相关任务时,需要把图片传给智能体;
- Linux 剪贴板行为很奇怪:鼠标选中文本是一个剪贴板,普通复制又是另一个剪贴板,最基础的复制粘贴突然变成一个小任务;
- 熟悉的
Ctrl+Z不是撤销输入,而是暂停终端进程; - 发送消息也需要习惯:
Enter、Alt+Enter、Shift+Enter,甚至按Tab后误发送。
为了解决这些问题,我开始试其他终端。我那个老 xfce4-terminal 对 TUI 智能体来说已经不太合适了。我看了 Ghostty、Kitty、Warp、Tilix、Alacritty。最后停在 Ghostty。
一部分痛点可以通过配置解决:
- 用 Ghostty 设置把剪贴板行为理顺;
- 做 UI 任务时,把图片保存到桌面,然后拖进终端,让路径自动插入;
- 用扩展权限启动智能体(
yolo mode),这样它们可以读取项目目录外的图片。
与此同时,我也在寻找可以借鉴实践经验的信息源。信息很多,但大多是“某个厉害模型发布了”或“某个新工具出现了”这种新闻,缺少在真实项目里怎么用的细节。所以我一边看新闻,一边自己试,慢慢找到更有价值的信息源:一些频道和聊天群,里面的开发者会分享使用智能体的经验。有人贴了 GitHub 活动统计。我当时直接震惊:有些开发者通过智能体处理了几百万行代码。
慢慢地,我花在“用 AI 智能体写代码”之外的时间也越来越多:找工具、深入工具、改进开发流程。最后就很清楚了:结果不只取决于模型,还取决于模型周围的工作方式。
我试过的 AI 智能体
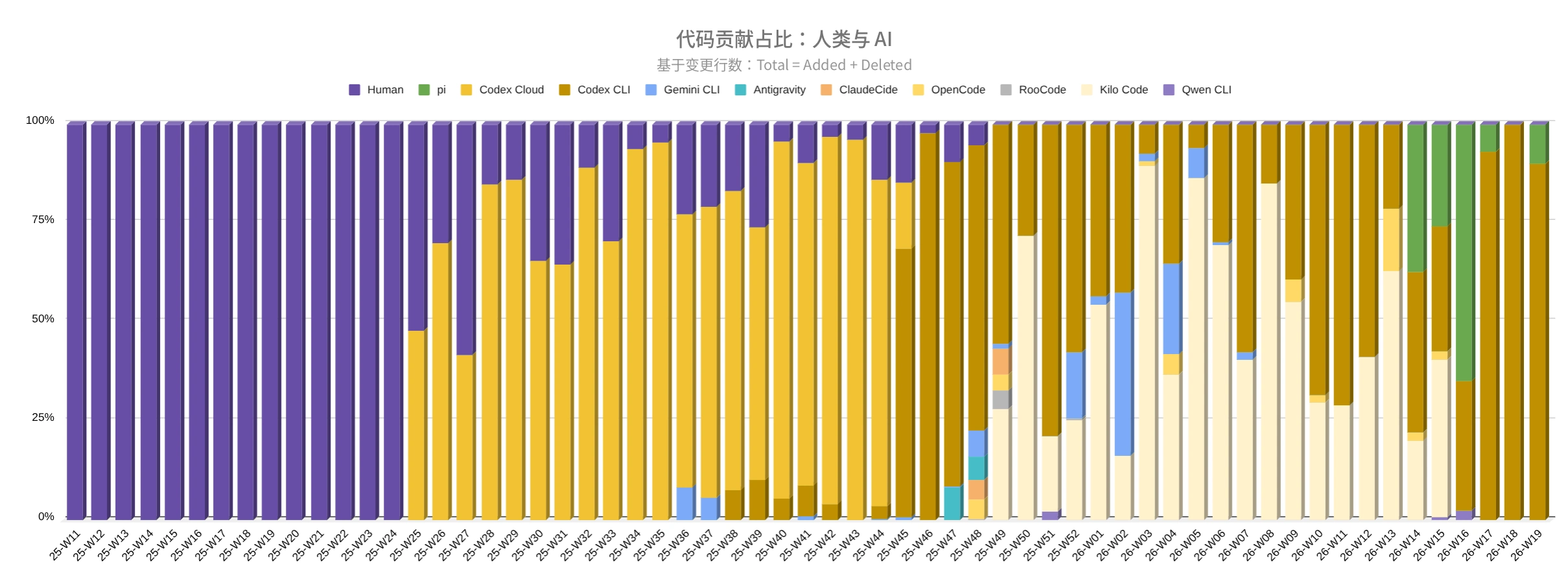
我在 TasK 项目上使用智能体的统计
这张图展示了我在 TasK 项目上试用不同 AI 智能体的过程。它不仅能看到智能体代码占比的增长,也能看到工具组合如何变化:Codex Cloud、Codex CLI、Kilo Code、Pi 等。我不想靠评测文章做比较,而是拿自己项目里的当前任务,看智能体怎么完成、能有多自主、结果质量如何。
新的智能体和模型出现得比我测试得更快。下面是我的主观简评:试过什么,哪些留下来了,哪些很快放弃了,原因是什么。
Codex Cloud 是 OpenAI 的网页智能体:项目在云端运行,代码审查也在应用里完成。它很适合作为第一次体验:隔离性好,审查方便。缺点也来自这些优点:运行更慢,消耗更多 token,过程中不能快速在本地“摸一摸”结果。现在我不用它了。
Codex CLI 是 OpenAI 面向 GPT 模型的 CLI 智能体。它是我的主力工具。本地运行,速度快,很多东西可以配置。对顶级模型配合下的智能体,我已经建立了一定信任,所以会用 yolo mode 跑:智能体拥有扩展权限,不会每一步都请求确认。主要缺点是终端界面。
Claude Code 是 Anthropic 面向 Opus、Sonnet、Haiku 模型家族的 CLI 智能体。很多新的智能体玩法往往先在这里出现。我没能很好地用它的原生模型测试。它和 GLM-4.7 的组合不适合我。
一开始我看 Claude Code 和 Codex CLI 的发展,会疑惑为什么 Codex CLI 的功能这么少。后来我明白了:Claude Code 里很多通过 hooks(事件处理器)和其他机制解决的事情,在 Codex CLI 里可以通过 AGENTS.md 里的指令解决。Codex 模型更听指令,所以需要的外部装置更少。
我同意 Pi 作者 Mario Zechner 的观点:Claude Code 正在逐渐变成一艘像荷马·辛普森汽车那样的“宇宙飞船”。能力很多,但日常工作里你只用其中很小一部分,其余部分变成了暗物质——不知道它做什么,也不知道它怎么影响结果。

Gemini CLI 是 Google 面向 Gemini 模型家族的 CLI 智能体。有免费额度:对我来说,强模型通常一天够做 1–2 个任务。它适合文本和文档。例如,它帮我写过 task-agents-playbook 的文本和翻译。在我的环境里,它写代码弱一些。我还记得 Gemini 2.5 在一次 Psalm 升级后的大规模修复中,把我的项目搞坏了。
Antigravity 是 Google 的 IDE,一个带智能体的 VS Code 分支版本。它使用 Gemini 模型,也支持有限的其他模型。我试的时候有免费额度。那时产品还很生,有一些让人不舒服的问题,所以我没有继续用。
Aider 是较早的一批 CLI 智能体,有自己的性格。它有自己的 模型排行榜,专门比较代码编辑任务,我曾经关注过。最后一个官方版本发布于 2025 年 8 月 10 日,但仓库里还有新的提交。如果发展真的停了,会有点可惜;也可能只是新东西发布前的暂停。
OpenCode 是一个 CLI 智能体,有自己的模型生态和资费体系。按我的记忆,它有免费模型、相对便宜的订阅,也能使用本地模型。我用它配合 Z.ai 的 GLM 模型做过不少事情。产品本身不错,但在我的使用里 token 消耗比较明显。终端界面比 Codex CLI 花哨,但不一定更方便:在终端里,很多时候越简单越好。OpenCode 还有一个重要信号:Kilo Code 后来转向了它的核心。我在《用于金融分析的 AI 智能体》里写过它的使用经验,也写过 OpenCode 中的 SKILLs。
Qwen Code 是一个 CLI 智能体,是 Gemini CLI 的分支版本,面向阿里巴巴的 Qwen 模型。我在 Qwen-3.6 发布后试过:写代码还不错。当时有每天 1000 次请求的免费额度,后来取消了。
RooCode 是 VS Code 扩展,配置项很多。有项目语义搜索:当你记不清类名,或者想在仓库里的文档中按语义搜索时,它很有用。对大代码库来说,这很重要。项目发展非常快:有时一天好几个版本。我没有把自己绑定到这样一个变化速度的工具上,因为担心稳定性。可惜的是,这个产品确实有意思。2026 年,团队宣布 停止维护 Roo Code,转向 Roomote。
Kilo Code 是 VS Code 扩展。最初它是 RooCode 的分支版本,后来扩展被围绕 Kilo CLI 重建,而 Kilo CLI 自己在 README 里被称为 OpenCode 的分支版本。在这次迁移前,我很积极地使用 Kilo,但新版本一开始没有带上对我最关键的功能——语义搜索。最近它以 Codebase Indexing / semantic_search 的形式回来了,但仍然是实验性功能,产品也还比较生。我仍然关注 Kilo:我喜欢它的 Ask 和 Architect 模式,带 Mermaid 图的回答能更好地解释智能体的思路。我在《第一次使用 GLM-5》里写过这段经验。
Pi 是 Mario Zechner 做的极简 CLI 智能体。和 Claude Code 这类巨兽相比,我喜欢它相反的哲学:小核心、可扩展、用户自己补自己需要的东西——想造自己的宇宙飞船也可以 😎。Pi 的作者专注核心,其余交给用户扩展。最近一个月,我在 task-orchestrator 项目上大量使用 Pi。
模型和我当前的订阅
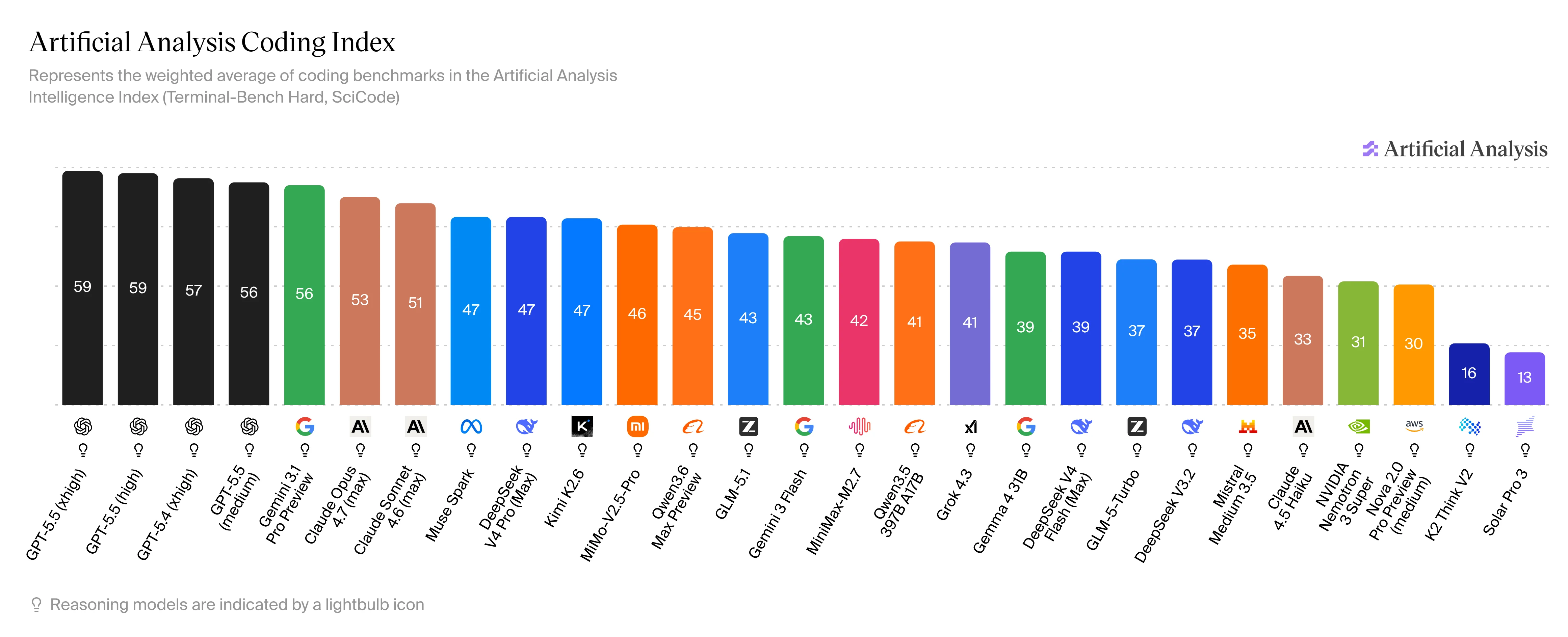
Artificial Analysis Coding Index 是我判断哪些代码模型值得关注的参考之一。
模型发布得太快,我不可能在真实工作中全部测试。新模型发布后,我会先看它在 Artificial Analysis Coding Index 这类榜单里的位置,再决定是否值得在工作中试用。
我试过 DeepSeek、Qwen、MiniMax、Z.ai 的中文模型,也单独试过 Google 的 Gemini。GLM 系列模型在我的流程里表现不错,所以我一度很依赖 Z.ai 的 GLM。
写这篇文章时,我的工作组合是:
- Codex CLI 配 GPT 模型:
gpt-5.5 xhigh fast、gpt-5.5 high fast以及不带fast的版本。这是我的顶配组合,但额度很紧,成本也偏高; - Pi 配 Z.ai 的 GLM-5.1。这是一个简单可用的替代方案,适合那些我不想为额度焦虑的任务。在我的任务上,GLM-5.1 的表现不比 GPT-5.5 差。
订阅方面,我现在是这样:OpenAI Pro 每月 100 美元,勉强够我在 2–3 个终端里写代码。Z.ai 是季度 Pro 订阅 90 美元(折合每月 30 美元),但它们的价格经常变化。我在考虑回到 Lite:以前额度够用,不够的是速度。
我会开几个并行终端处理不同任务,并尽量保持会话短小,避免上下文膨胀。
上下文过大,会让会话变得难以控制。长会话像滚雪球:越往后,每一步消耗的 token 越多,额度消耗也越快。有时候更正确的做法是开一个新会话,给智能体一个短而干净的任务。
GLM 上我遇到过一个不好的现象:上下文超过 100K 后,模型有时会在推理里“跑偏”,开始扭曲词语,进入很长的循环。所以我在智能体配置里限制了上下文。最近几周这个问题少了,但我仍然不喜欢巨大的会话。
我希望理想智能体具备什么
经历这些实验后,我对适合 CLI/TUI 工作的智能体有了一份需求清单。
最低要求:
- CLI/TUI 界面。 我更喜欢智能体在终端里工作。我也会看 GUI 智能体,但目前它们看起来还很生、慢,并且吃 CPU 和内存。
- Skills / 指令。 这是目前用最低成本给智能体增加“能力”的方式:从项目工作规则,到单独的场景、工具和专门动作。
- Tools。 应该可以添加自己的 tool calls——现在通常通过 MCP 做。
- 启动上下文控制。 智能体需要在任务开始时快速拿到必要的最小上下文,而不是一开始就把会话撑大。在 Codex CLI 中,一部分上下文已经来自模型的基础提示词。例如,GPT-5.5 的
base_instructions里有很长一段关于行为、设计、前端建议,甚至还有“不要谈论 goblins”这种限制。当我已经在AGENTS.md里描述项目风格、规则和智能体行为时,这类基础上下文可能多余,甚至和我的指令冲突。 - 可扩展和可定制。 智能体应该允许我按自己的流程修改和扩展功能,而不是只能在预设模式里工作。
- LSP 或类似能力。 代码导航应该比
grep更聪明。Mario Zechner 批评过 OpenCode 中使用 LSP 的方式,但我认为这仍然是有价值的能力。 - 语义索引。 对大项目尤其重要:智能体需要能根据不精确描述或不完整类名找到相关代码,也能按语义找到文档。Kilo Code 在这方面做得不错。
- 支持不同模型服务商。 本地模型、云模型,以及额度用完时的备用方案。
- 免费层或低成本入口。 新模型在吃预算之前,最好能先试一下。
我如何搭建与智能体协作的流程
输入上下文
智能体记忆
AI 智能体没有过去的记忆。它的记忆受限于当前对话。新会话一开始,一切都要重来:智能体像第一次看到项目一样重新进入上下文。
我在《记忆与上下文:从虚构故事中得到的有意识 AI 启示》里写过这个问题。我很推荐看电影 《记忆碎片》:主角不记得 15 分钟前发生了什么,只能构建一套外部提示系统。电影很好地展示了这种系统如何帮助人不忘记重要信息,以及记忆组织出错会带来什么后果。
AI 智能体也类似。下面写的所有东西,本质上都是为了帮助智能体一次又一次更快地进入项目:更少上下文、更低 token 成本、更少重复解释。这通常叫 context management / context engineering(上下文管理 / 上下文工程)。
在我的流程里,智能体记忆有不同时间尺度:
- 短期记忆——当前会话。里面是一个具体任务的讨论。我尽量让它保持短小,任务结束就关闭。
- 中期记忆——
todo/中的 epic 和 task 文件。那里保存工作上下文:目标、标准、PR、变更历史、依赖关系。 - 长期记忆——
AGENTS.md、docs/、角色和约定。这些是项目规则、架构、流程、决策和指令。
说到底,还是跟人协作一样。
AGENTS.md 作为项目宪法
AGENTS.md 文件是 AI 智能体的入口、指令路由器,以及项目“宪法”。
里面包含:
- 使命和规则优先级。这样当指令冲突时,智能体知道什么更重要。
- 角色——工作开始前选择专业角色。角色会调整智能体的关注点,让它从正确角度看任务。
- 反思——评估任务复杂度、上下文和风险。这样智能体不会一上来就写代码,而是先思考,必要时提出澄清问题。
- 与用户沟通的语言——沟通和命名规则。在我的俄语工作流里,智能体很喜欢夹带英文短语和术语;我会要求尽量减少。
- 项目架构——技术栈、基础设施、目录结构、迁移、模块和层。
- 代码工作规则——Git flow、分支、任务、技术债。
- 测试与验证(Tests and Validation)——测试类型和验证工具。
- 交付前检查——任务交付前的要求。
- 提交格式和 PR(Pull Requests)——如何写提交和 PR,按什么顺序行动。
- 文档化——项目中什么需要文档化,如何文档化。
- 禁止事项——明确禁止,防止模型做那些它“能做但不该做”的事。
- 自查(self-review)迷你清单——交付结果前必须做的动作。它帮助模型不忘关键步骤。
最重要的规则:不要让根目录的 AGENTS.md 膨胀。根目录只保留最重要的规则,以及指向次级指令的链接。
项目知识和规则之所以可迁移,是因为它们不活在 MCP、Skills 或某个智能体的专有功能里,而是活在普通 Markdown 文件里。只要智能体能读 AGENTS.md,它就已经可以按我的规则工作。因此,Pi + GLM-5.1 在没有额外层的情况下,在我的任务上可以跟 Codex CLI + GPT-5.5 xhigh 跟上节奏。
智能体角色
根据任务不同,智能体会选择角色。角色定义关注点、文档和质量标准。
我的流程中有这些角色:
- 市场营销——推广策略、获客漏斗、市场分析和指标增长;
- 销售——销售、用户转化、咨询和市场反馈;
- 产品负责人(Product Owner)——定义业务目标、价值和验收标准;
- 法务——法律审查、隐私/合规、用户协议;
- 技术负责人(Team Lead)——定义实现方式,评估风险和质量标准;
- 系统分析师(System Analyst)——澄清需求、场景、限制和边界场景;
- 系统架构师(System Architect)——设计和检查架构、模块边界和集成;
- UI/UX 设计师——设计用户流程和 UI 组件;
- 文案(Copywriter)——写界面文案、微文案和错误消息;
- 后端开发者(Backend Developer)——实现服务端逻辑:DDD、Application/Domain、API、Messenger;
- 前端开发者(Frontend Developer)——实现 UI:Twig、Turbo、Stimulus、AssetMapper、CSS/JS;
- DevOps 工程师——负责容器、环境、CI/CD 和基础设施 make 命令;
- 后端代码审查者(Backend Reviewer)——审查 PHP、DDD、架构、风格、测试和安全;
- 前端代码审查者(Frontend Reviewer)——审查 UI/JS、Turbo/Stimulus、UX 和可访问性;
- DevOps 审查者——审查 Compose、CI/CD、安全和可复现性;
- 后端 QA(QA Backend)——检查用例/API、测试计划、单元/集成测试;
- 前端 QA(QA Frontend)——检查 UI 场景、E2E、跨浏览器和回归;
- 技术写作者(Technical Writer)——更新文档、指南和契约说明。
在提示词里调用角色的例子:
Backend developer, take the task from todo/EPIC-status-page.todo.md into work;Copywriter, check the texts in the PR;Frontend developer, do a review。
角色帮助智能体把注意力切到正确领域,并从正确角度看任务。
说到底,还是跟人协作一样。
项目任务和文档
把任务当成规格说明
我把自己的流程称为 任务驱动开发(Task-driven development)——由任务规格驱动的开发。
想法很简单:任务成为唯一事实来源。
一个任务描述:
- 目标;
- 任务历史和上下文;
- 边界:范围内包含什么,不包含什么;
- 验收标准;
- 必须执行的检查;
- 测试要求;
- 上下文链接;
- 架构限制;
- 预期结果格式。
如果需要一个大功能,我会写一个大型任务(epic)。这个 epic 会被拆成原子任务。每个任务都有自己的循环:定义 → 实现 → 自查(self-review)→ 角色审查 → PR → 我的最终审查 → 合并。
规格驱动开发(spec-driven development)这个词有很多用法。在 GitHub Spec Kit 或 Kiro Specs 这类现代 AI 工具中,它通常是一层独立产物:需求、设计、计划和任务列表。我的方式更简单:我不单独引入规格流水线。规格说明直接打包进任务里:历史、边界、验收标准、检查和上下文链接。从这个意义上说,task = spec。
这很适合智能体:任务可以放进仓库,和 PR 关联,在工作过程中更新,并在角色之间传递。智能体拿到的不是模糊的“做漂亮一点”,而是目标、边界、上下文和检查。
任务即代码(Tasks as Code)
任务管理我使用文件系统。项目根目录有一个 todo/ 文件夹,里面是 Markdown 格式的任务和 epic 文件。这个文件夹和代码放在一起,并由 Git 管理,所以任务成为项目上下文的一部分:智能体可以像普通文件一样打开它,在角色之间传递它,把它和 PR 关联,并和代码一起看到变更。
类比 Docs as Code,我把这种方式叫做 任务即代码(Tasks as Code)。在前面那套记忆分类中,这类任务就是智能体的中期记忆。
为了不在项目之间复制规则,我把它们抽到了单独仓库 todo-md:
任务不是项目长期知识的来源。长期知识的主要来源应该是写得好的代码和必要的最小文档。任务我不会永久保存:发布后会删除。如果某些东西需要长期保存,最好放进 docs/;下面会讲。
说到底,还是跟人协作一样。
文档作为记忆库(Memory Bank)
AI 智能体很擅长理解代码做了什么。写得好的代码本身就是自解释的。但有些知识很难或无法从代码中提取:产品为什么存在,用户是谁,哪些方案已经讨论过,为什么选择这种架构,哪些场景是关键场景,如何部署,MVP 和 MMP 的边界在哪里。
所以,除了 AI 智能体指令和项目任务,项目里还需要文档。在使用 AI 的开发者圈子里,它常被称为 Memory Bank。
这些文档包括:
Vision.md——产品愿景、目标用户、价值和原则;Mission.md——产品使命和价值基础;Strategy.md——业务目标及达成策略;MVP.md——Minimum Viable Product,用于验证想法的最小版本;MMP.md——Minimum Marketable Product,用于进入市场的最小版本;StoryMapping.md——带 backbone activities 和 release slices 的 user story map;- ADR——架构决策记录及其目的;
- 模块文档;
- SDLC——Software Development Life Cycle,以及角色分工;
- 开发、测试、生产环境的基础设施说明;
- 部署说明;
- 用于构建 UI 的主题组件;
- 用户使用文档。
项目文档很多,所以需要提示智能体什么时候使用哪些文档。我通过角色解决这个问题:不同角色入口处提供不同文档集合,智能体根据请求自己判断要拉取什么。例子是 产品负责人(Product Owner) 角色,其中包含指向这些文档的链接。
说到底,还是跟人协作一样。
架构、规则和质量
模块化单体
按 DDD 原则编写、边界隔离良好的模块化单体,很适合和 AI 智能体一起开发:智能体更容易收集需要的上下文,减少在项目里乱找,也减少 token 和时间消耗。
有帮助的点包括:
- 所有代码在同一个仓库;
- 模块按领域边界拆分;
High cohesion, low coupling原则减少进入无关模块和类的必要性;- 统一的领域语言让导航更容易;
- CQRS 分离读写场景。
我有很多 PHP 经验,所以最终审查、架构设计和实现验证对我更容易。现代 PHP 也提供了正常的类型、通过 declare(strict_types=1) 实现的严格类型、readonly、enum、Composer,以及大量工具和库。
Symfony 则提供了适合复杂应用的成熟框架:依赖注入容器、console commands、通过 Messenger 实现的队列、验证、序列化、HTTP client、测试基础设施,以及可以在其上构建模块化架构的机制。
测试
使用 AI 智能体开发时,测试非常重要:Unit、Integration、E2E、Smoke。
我使用几个层级:
- Unit——快速的类测试。不使用数据库和外部服务。应该写很多:它们帮助在修改过程中保持类的计算完整性。在测试环境中运行。
- Integration——检查层与基础设施之间的交互。需要测试数据库,但不和外部服务交互。因为数据库会让它们更慢,所以应该覆盖重要代码区域。在专门的测试环境和单独数据库中运行。
- E2E——检查用户场景和关键用户路径。需要数据库,有时也需要外部服务。它们很慢,所以我在相关功能变化时以及发布前运行。在独立 E2E 环境中运行,有单独数据库和配置。
- Smoke——一组最小的快速手动检查,用来验证当前项目配置。回答的问题是:这个子系统或组件至少能不能工作?只在需要快速检查系统某部分时手动运行。
Unit、Integration、E2E 和部分 Smoke 测试,我用 PHPUnit 运行。配置示例放在 coding-standard。Smoke 检查也写成 Smoke Commands——用于手动运行的 console commands。
说到底,还是跟人协作一样。
约定:编码规范
约定是一组规则和协议,用来规定代码风格、结构和架构方式。它们帮助代码保持一致、可读、可维护。
为了方便接入自己的项目,我把这些约定放进了单独的公开仓库 coding-standard。
智能体很难稳定遵守一大套规则:它们可能带入自己的风格,偏离项目风格,破坏层隔离,或者把本该薄的层写得过厚。所以我把一部分约定固化成自动检查:用于 Deptrac 的规则,以及用于 PHPCS 的 sniffs。
为了保持代码干净,我使用这些工具:
| 工具 | 配置示例 | 目标 | |
|---|---|---|---|
| PHP_CodeSniffer | phpcs.xml.dist |
检查代码风格 | |
| Psalm | psalm.xml |
静态类型分析 | |
| Deptrac | depfile.yaml |
检查架构依赖 | |
| PHPMD | phpmd.xml |
发现问题代码 |
说到底,还是跟人协作一样。
Git 工作流
Git 工作流 是一组关于分支、提交、PR、发布和部署的规则。我明确告诉智能体:创建什么分支,提交怎么写,什么时候开 PR,合并前检查什么。
提交格式也会自动检查:本地检查和 CI 检查。这是另一个反馈闭环:智能体写提交,检查发现问题,智能体修改消息,然后重新检查。
说到底,还是跟人协作一样。
给智能体的反馈闭环
在反馈闭环里,我使用测试、静态分析器,以及自动检查约定的工具。智能体创建、修改或删除代码,运行检查,拿到确定性结果。如果检查失败,智能体读取输出,修改代码,再次运行检查。如果没有问题,就退出循环。
智能体在交付任务前通过的检查越多,最终审查时留给人的手工检查就越少。
工具:用一个命令跑检查
智能体需要确定性的命令。如果检查由十个手动步骤组成,它会忘记某一步,或者使用错误参数。所以我使用 Makefile。
示例:
check: cs psalm deptrac test
cs:
vendor/bin/phpcs
psalm:
vendor/bin/psalm
deptrac:
vendor/bin/deptrac analyze
test:
vendor/bin/phpunit在 AGENTS.md 中,只需要写:
After finishing work on the task, before the final response to the user, run `make check`.
If `make check` fails, fix the causes of the failure and run it again.
Hand over the task only after `make check` succeeds.这就是反馈闭环:智能体完成修改,运行检查,修复发现的问题,重复运行,只有检查成功后才交付任务。
工作流程
规划
工作通常从定义任务或 epic 开始。代码是下一步。
示例请求:
Take the analyst role. I need a status page for the project. Create an epic for this task.之后流程如下:
- 请求。 我指定角色和目标。
- 生成。 智能体加载角色、任务定义规则、模板,然后编写 epic。
- 自查(self-review)。 我要求智能体重新检查自己,并修复薄弱点。
- 审查。 我要求另一个角色检查任务:架构师、代码审查者、QA、DevOps。
- 创建 PR。 智能体在单独分支中整理变更并创建 PR。
- 最终审查。 我自己阅读任务并提出意见。
- 关闭。 智能体合并 PR,删除分支,回到 master,等待下一条命令。
“磨刀不误砍柴工。”
——民间智慧
糟糕的任务定义几乎必然带来糟糕的方案。好的任务定义不保证方案完美,但会缩短最终审查中的“检查 → 修改”循环。
实现
实现阶段和规划阶段类似,只是智能体修改的是代码,而不是任务文本。
示例请求:
Backend developer, take the task from todo/EPIC-status-page.todo.md into work.之后:
- 请求。 我给出角色和任务文件。
- 实现。 智能体写代码、测试、迁移和文档。
- 检查。 它运行 PHPUnit、PHPCS、Psalm、Deptrac、PHPMD、Composer 或
make check。 - 自查(self-review)。 它检查自己的方案。
- 角色审查。 另一个角色审查架构、测试、UX 或基础设施。
- PR。 智能体创建 PR。
- 最终审查。 我阅读结果,并和智能体走“评论 → 修改”的循环。
- 合并。 智能体合并,删除分支,回到 master。
- 发布。 发布前,智能体运行 E2E,准备更新日志和标签。生产部署由我自己做。
这套流程的价值在于阶段拆分。智能体不是一口气做完所有事情:先实现,再自查,再交给另一个角色审查,最后才交给人做最终审查。阶段拆分和前置任务规划结合起来,可以提高实现质量,并减少人在最终审查上花的时间。
最终审查
最终审查时,我看的重点不是实现本身,而是代码是否符合项目规则:约定、模块隔离、高内聚、低耦合(High cohesion, low coupling) 原则、领域边界,以及统一的领域语言。
我还会检查那些尚未固化到确定性工具里的东西:奇怪的方案、不必要的复杂性、安全问题和明显的垃圾。如果某处感觉不对,我通常会问智能体为什么这样做。然后我可能接受,也可能要求它重做。
测试代码我几乎不看:只有需要确认具体场景或失败原因时才打开。
我会单独检查 PR 格式。例如,我很在意智能体是否给 PR 打上自己的标签:之后我会根据这些标签统计智能体工作占比。
对智能体规则的改动,我比普通代码看得更仔细。好规则回报很高,但智能体不一定擅长给自己写规则:经常写得啰嗦,抓不住重点。我认为这可以通过训练智能体写规则来改进。现在这类改动我还是更愿意手工读一遍。
最终审查时,我也会记录智能体反复犯的错误。之后这些错误会变成新的规则、检查和流程修正。
复盘
复盘的目的,是提高智能体工作的自主性和质量。我会看哪些问题反复出现,然后把它们转成规则、检查、模板或流程说明。
循环是这样的:
- 观察。 在工作过程和审查中观察智能体。记录失败、上下文误解、多余动作和错误。
- 分析。 找出浪费时间和 token 的重复模式。寻找系统性方案:应该修改哪条指令、哪个模板或哪个工具,才能避免错误再次出现。
- 改进。 对
AGENTS.md、角色、任务模板、文档、代码检查器配置、Deptrac 规则、sniff 或测试做小而明确的修改。
这里很重要的一点是遵守隔离变更原则。不要一次改所有东西——那样无法追踪某个具体修改的影响。改进应该小步引入,并立即检查效果。
真实 epic 和结果示例:status page epic,以及它在 TasK 上的实现——status page。
结果指标
数字说明了什么
我几乎已经不再手写代码。于是有一个重要问题:生产力是否真的提升了?
为了回答这个问题,我开始收集 TasK 项目的详细指标,因为我主要开发的是这个项目。除此之外,我也看自己其他 GitHub 项目的总体指标。
2026 年 5 月 13 日的项目规模
| Language | Files | Lines | Blanks | Comments | Code | Complexity | LPF |
|---|---|---|---|---|---|---|---|
| PHP | 5 985 | 398 495 | 61 695 | 25 693 | 311 107 | 8 554 | 67 |
| Markdown | 562 | 59 330 | 12 369 | 0 | 46 961 | 0 | 106 |
| Twig Template | 252 | 20 657 | 1 450 | 0 | 19 207 | 799 | 82 |
| YAML | 199 | 14 168 | 676 | 447 | 13 045 | 0 | 71 |
| Plain Text | 43 | 10 248 | 106 | 0 | 10 142 | 0 | 238 |
| JavaScript | 37 | 7 158 | 1 164 | 247 | 5 747 | 802 | 193 |
| Shell | 29 | 2 194 | 315 | 164 | 1 715 | 247 | 76 |
| BASH | 16 | 596 | 82 | 26 | 488 | 90 | 37 |
| JSON | 16 | 9 467 | 0 | 0 | 9 467 | 0 | 592 |
| HTML | 9 | 148 | 2 | 0 | 146 | 0 | 16 |
| Makefile | 9 | 840 | 147 | 73 | 620 | 32 | 93 |
| CSS | 4 | 538 | 95 | 29 | 414 | 0 | 135 |
| XML | 4 | 300 | 2 | 0 | 298 | 0 | 75 |
| Dockerfile | 2 | 217 | 20 | 6 | 191 | 16 | 109 |
| Sass | 2 | 16 | 0 | 0 | 16 | 0 | 8 |
| Docker ignore | 1 | 16 | 0 | 0 | 16 | 0 | 16 |
| INI | 1 | 12 | 0 | 0 | 12 | 0 | 12 |
| Python | 1 | 180 | 40 | 15 | 125 | 24 | 180 |
| SQL | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| Total | 7 173 | 524 581 | 78 163 | 26 700 | 419 718 | 10 564 | — |
如果粗略换算成 LLM 上下文,这大约是 5–7 百万 token。估算取决于分词器和文件组成,但数量级很明确:这样的项目不能整个塞进模型上下文里。必须有模块边界、任务、文档和检查,否则上下文会很快变成噪音。
文件和行数分布
图里可以看到,PHP 占主导:83.4% 的文件和 76.0% 的行数。但 markdown 已经占了明显比例——7.8% 的文件和 11.3% 的行数。这些是任务、指令、角色、约定和文档。对于智能体流程来说,它们已经成为代码库的一部分,而不是代码旁边的文字。
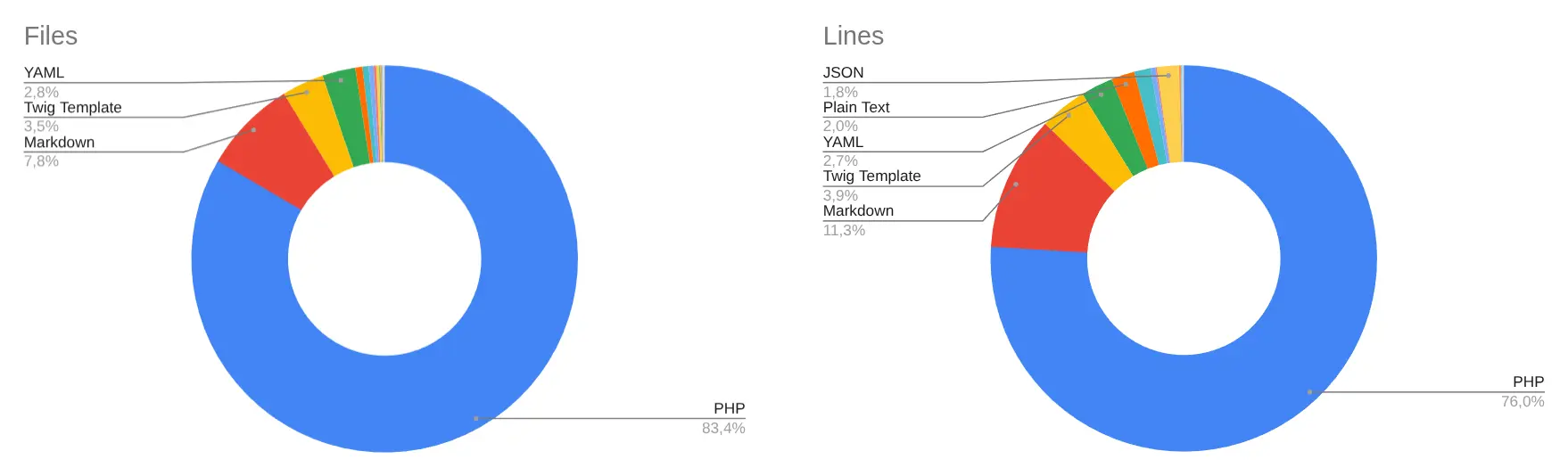
按类型统计的文件数和行数。
智能体在代码生成中的占比
这张图基于 diff 中“被触碰”的行数:Added + Deleted。2025 年第 25 周(6 月中旬)之前,几乎所有开发都由人工完成。接入 Codex Cloud 后,智能体代码占比很快成为主力。之后进入工具选择阶段:Codex Cloud 被 Codex CLI 替代,我试了 Kilo Code、OpenCode、Gemini CLI 等,后来 Pi 进入当前组合。
按周统计的被触碰行数占比:人类与 AI 智能体。
智能体开始改变多少代码
第一个视角是每周 diff 规模:新增多少行,删除多少行。切到智能体后,柱子明显变高:进入开发流程的变更更多了。删除峰值很大的一些周,部分原因是把一些方案从主项目抽离到独立公开包中。
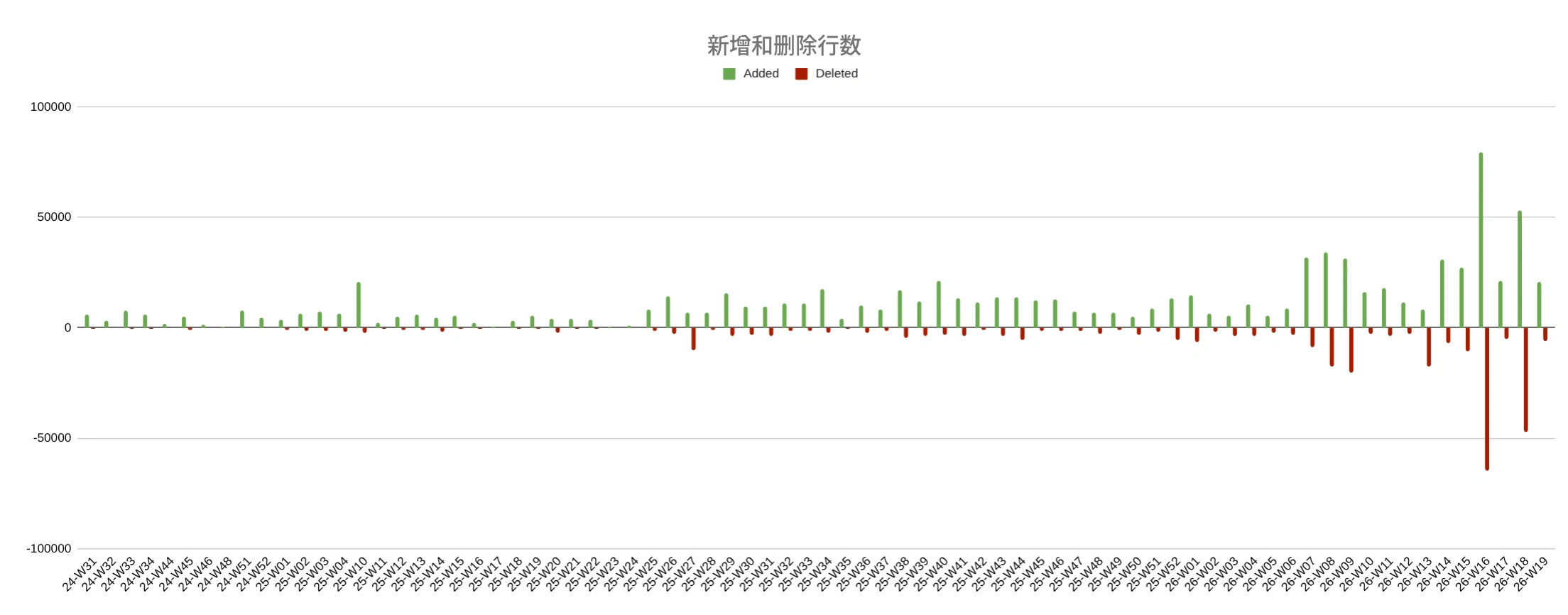
按周统计的新增和删除行数。
为了回答生产力问题,更有用的是比较我在项目中使用智能体前后的平均值。Total(总体变更量)大约增长 11.3 倍:从每周 4.1 千行到 46.4 千行。Net(净增长)大约增长 4.5 倍:从 2.7 千行到 12.2 千行。
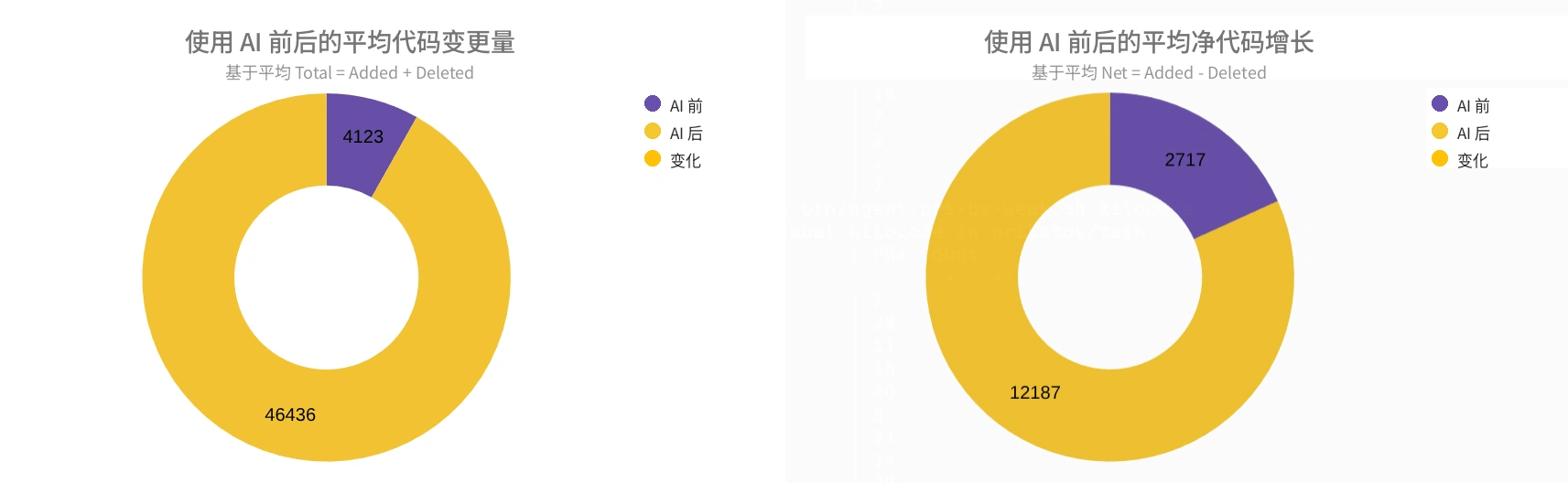
使用 AI 智能体前后的平均值。
Total 和 Net 两个指标的差异很重要。它说明增长并不只是新增代码行。相当一部分工作是修改已有代码。
重要的不只是改变了多少行,还包括这些行在哪里改变。接入智能体后,测试的占比明显增长。2026 年,更多变更开始落到 Markdown 上:任务、指令、角色、约定和文档成为项目的工作部分。
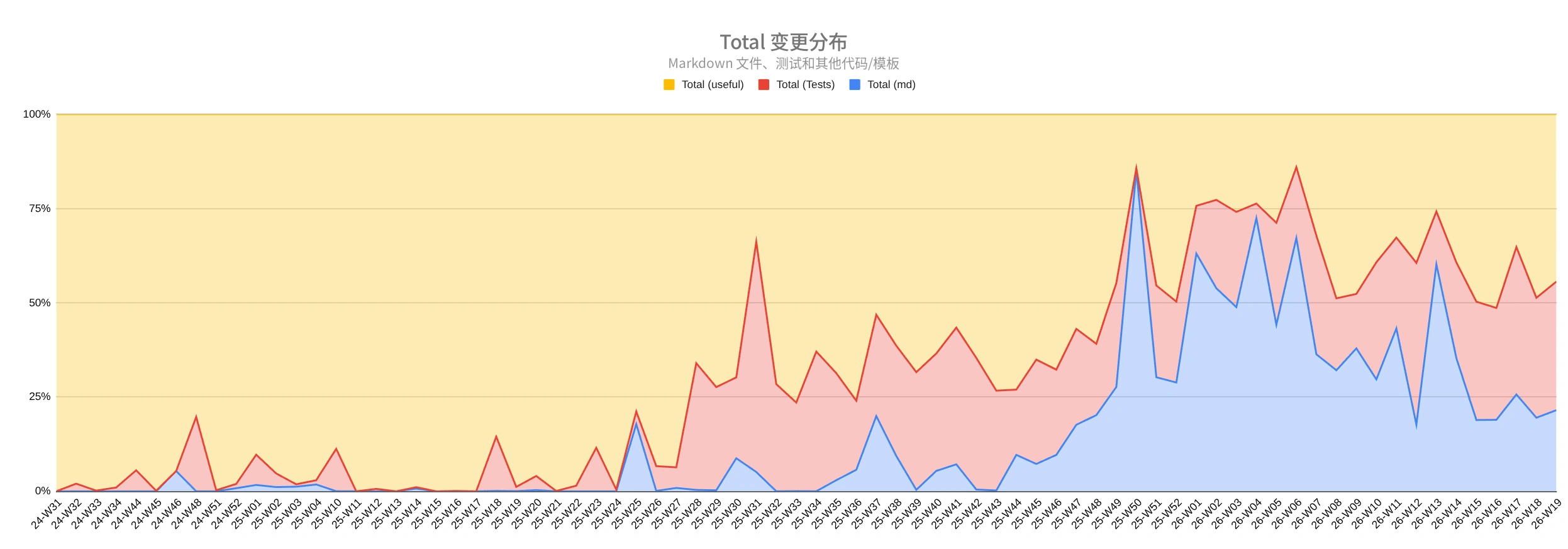
按周统计的代码、测试和 Markdown 变更占比。
不是所有指标都和行数一起增长
从提交和 PR 看,图像平静得多。2025 年 6 月之后,活动增加了,但不是 11 倍。这是另一个视角:行数展示变更量,PR 展示完成了多少任务。
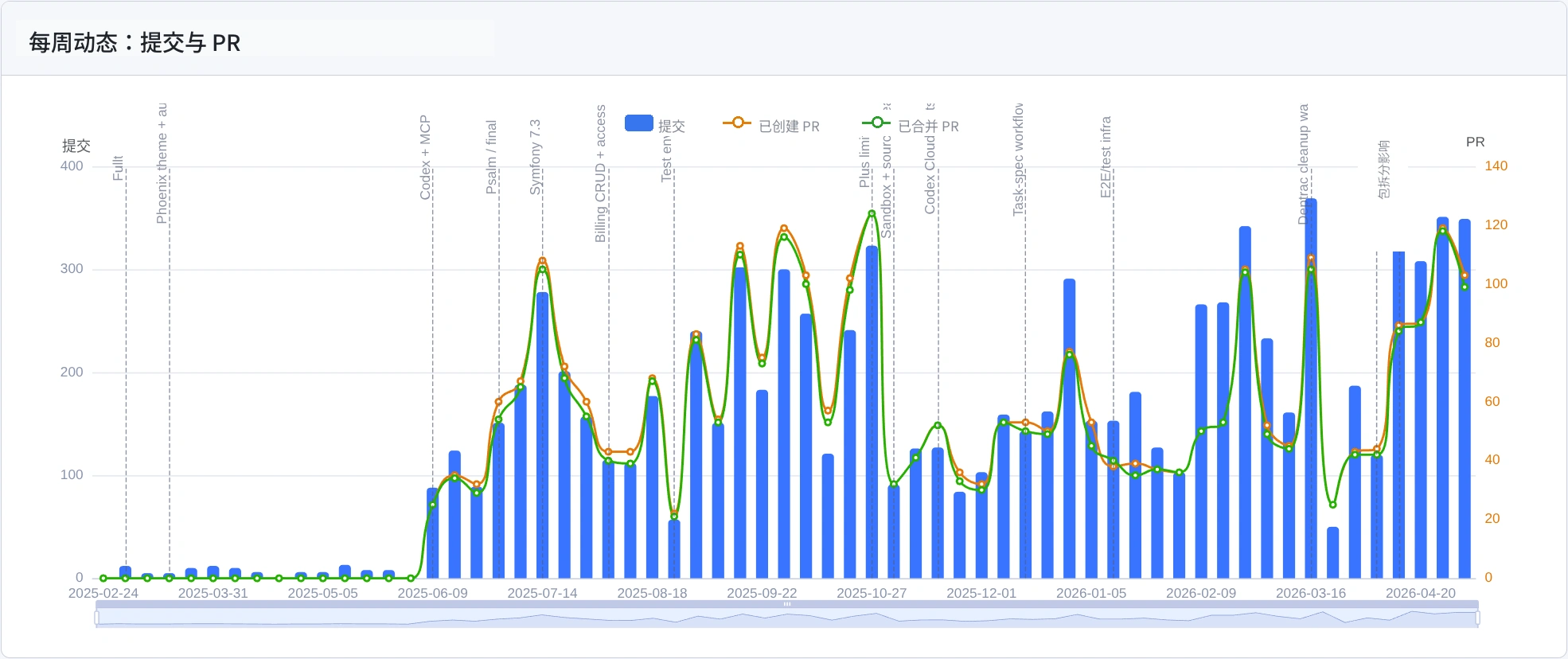
按周统计的提交和 PR。
2025 年 11 月有一个低谷:那时 Codex Cloud 出现严格额度限制,我开始寻找替代方案。我单独写过:《Codex Cloud 限制》。
但 PR 大小发生了变化。PR 数量没有成倍增长,但某些周里,一个 PR 承载的行数明显更多。部分原因是引入自动代码检查:添加新规则后,需要大规模修复项目以符合规则。图表末尾也能看到一些方案从主项目抽离到公开包。
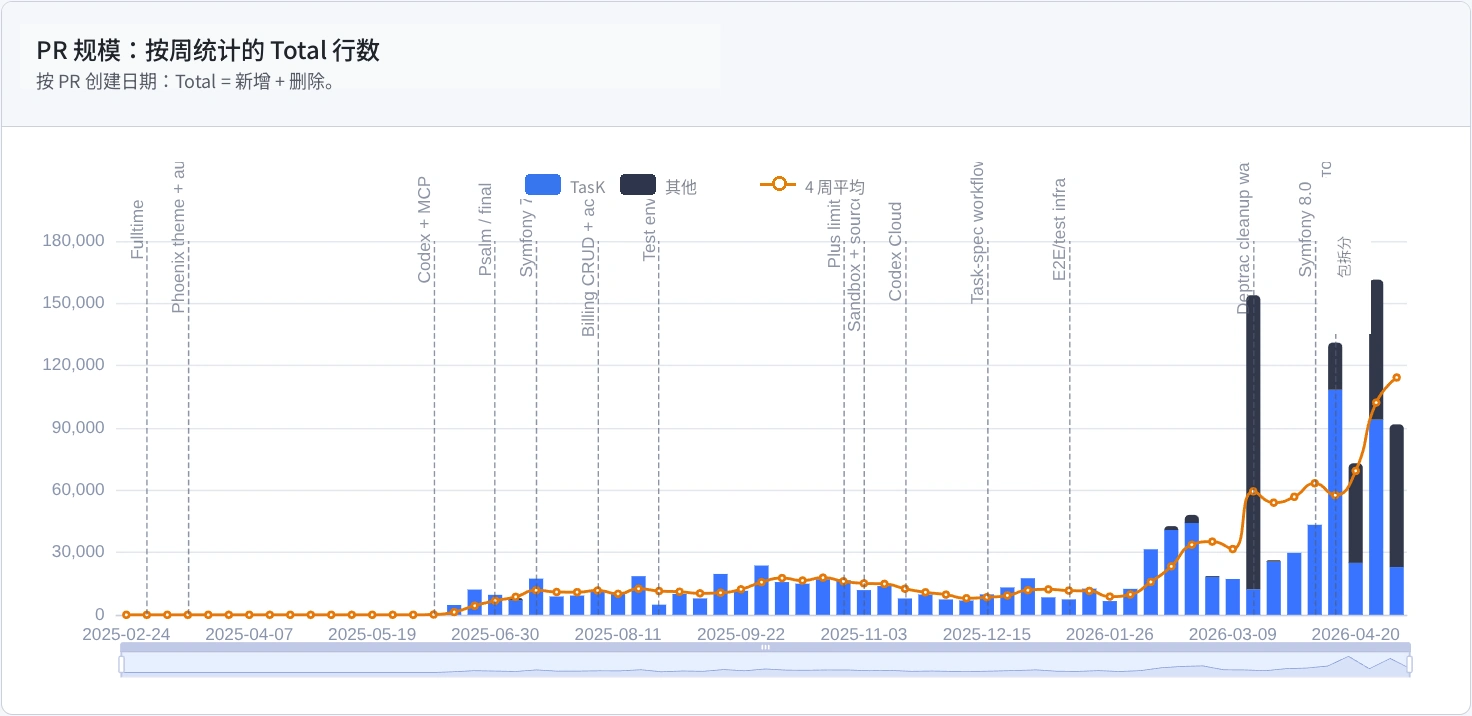
PR 规模:Added + Deleted。
从数字可以看到:
- 如果按变更吞吐量衡量,生产力上升了;
- 测试、文档和任务定义获得了更多关注;
- PR 数量没有增长 10 倍,所以瓶颈转移到了编排和审查。
从这套流程中长出来的公开项目
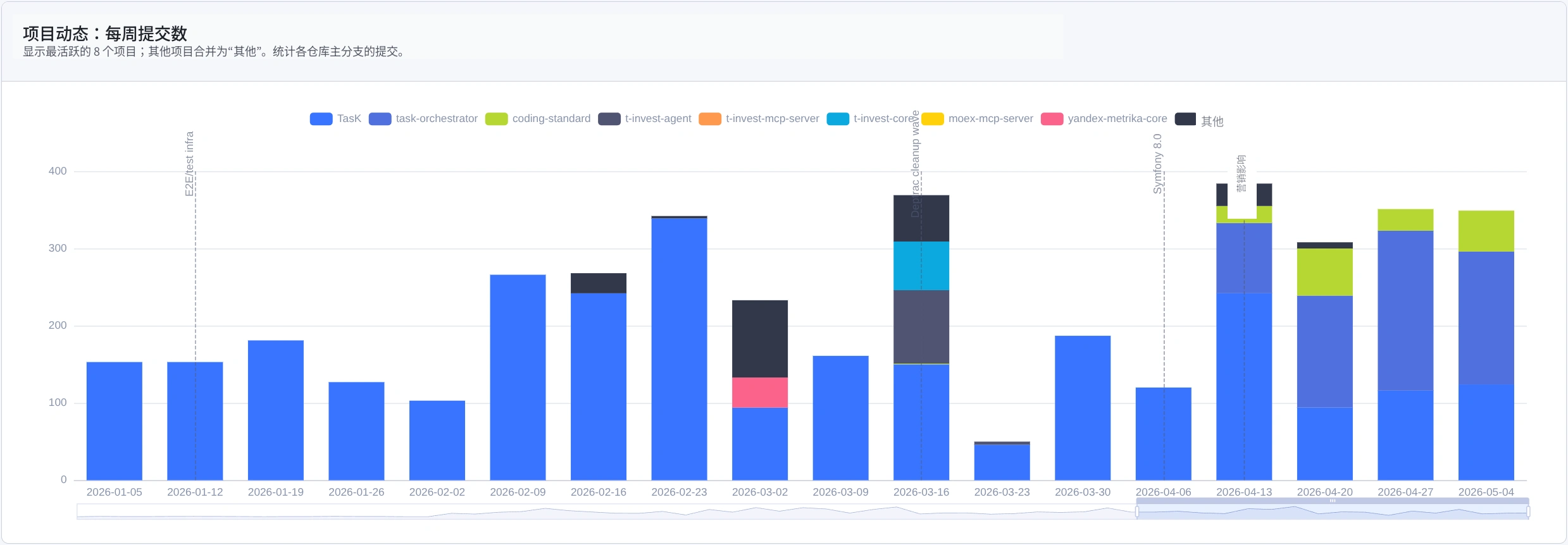
TasK 项目在增长,其中一些方案我希望在其他项目中复用。所以我开始把独立部分抽到公开仓库。
TasK Orchestrator
仓库:github.com/prikotov/task-orchestrator
想法是把我最大的痛点交给编排器:把一个 epic 或 task 按流程推进到最终审查。编排本身——让任务沿着流程走——并不复杂。真正累的是不断切换、恢复上下文、做很多小决策。
这个编排器应该成为一个负责维持流程的工具:角色、任务、检查、状态,以及阶段之间的转换。它应该把琐碎的事情从我身上拿走,只留下真正需要我注意的部分。
编码规范
仓库:github.com/prikotov/coding-standard
这里放着约定、配置示例和检查工具:架构规则、sniff 规则、Symfony 项目示例。
智能体可能偏离约定。检查应该在我的最终审查之前捕捉到偏离。
todo-md
仓库:github.com/prikotov/todo-md
这是任务规则和模板。一个基于 Markdown 文件和 Kanban 思路的最小任务管理系统。
Git-workflow
仓库:github.com/prikotov/git-workflow
关于分支、提交、PR、发布和部署的规则。智能体需要这类指令,才能一致地执行重复的 Git 工作流步骤:创建分支、写提交、打开 PR、打自己的标签、通过检查。
接下来我想改进什么
现在最大的瓶颈是时间。新的编程智能体、模型和方法出现得比我实际试用得更快。评测可以帮助缩小范围,但最终还是要在真实任务上测试。因为时间不够,一些个人项目的发展停下来了,而我也想带着智能体重新回到它们。
所以我首先想优化的是手工编排时间:现在很多时间花在推动任务按流程前进上。为此我在做 TasK Orchestrator——一个应该能把任务沿生命周期推进的工具。
另一种节省时间的方式,是把智能体接入调研。我开始用它们研究工具,这样就不用自己从零拆解每一个新东西。例子包括:《汇总表:AI 智能体框架和编排器》 和 《Coding Agents — 对比汇总表(最终版)》。
安全是另一个单独主题。需要防止密钥进入仓库。我已经遇到过一次:智能体把我的代理密码写进文档,而我没有注意到。
同样的节省时间逻辑,也会把智能体推到开发之外——投资和内容创作。我在《用于金融分析的 AI 智能体:用 OpenCode 分析 T-Investments 投资组合》里写过投资,在《OpenCode 中的 SKILLs:内容创作的流程化方法》里写过内容。投资方向我想挖得更深:投资组合管理质量需要提高,市场并不宽容。
PHP + AI = ❤️
在 PHP 圈子里,AI 辅助开发看起来还没有 Python/TypeScript 圈那么活跃。我想用自己的经验说明:AI 智能体同样可以在大型 PHP/Symfony 项目中工作。
本文描述的一切,我都在 TasK 上测试。如果你对用 PHP 做 AI-first(AI 原生)产品感兴趣,欢迎作为开发者或早期用户加入。新闻和讨论在 Telegram 频道,目前主要是俄语。
资料和链接:
- 我使用 Codex 的经验:对生产力的影响——第一次使用 Codex 的经验,以及它对开发影响的测量(俄语)。
- Codex Cloud 限制——我为什么从 Codex Cloud 转向 CLI 智能体(俄语)。
- 第一次使用 GLM-5:通过 Kilo Code 编程——使用 GLM 模型和 Kilo Code 的例子(俄语)。
- 用于金融分析的 AI 智能体:用 OpenCode 分析 T-Investments 投资组合——软件开发之外的智能体实验(俄语)。
- OpenCode 中的 SKILLs:内容创作的流程化方法——我如何把 skills 用于内容准备(俄语)。
- 记忆与上下文:从虚构故事中得到的有意识 AI 启示——关于记忆、上下文和外部提示的文章(俄语)。
- TasK——我在这个项目里测试本文描述的流程。
- task-agents-playbook——包含智能体角色、规则和指令的 playbook。
- task-orchestrator——任务编排器,以及用智能体做调研的实验。
- coding-standard——约定、sniff 规则和检查配置。
- todo-md——Markdown 格式任务的规则和模板。
- git-workflow——分支、提交、PR 和发布规则。
- Artificial Analysis Coding Index——我在试新模型前会参考的模型排行榜。
- Codex CLI——OpenAI 的 CLI 智能体,也是我的主力工具。
- Pi 编程智能体——极简 CLI 智能体,我用它配 GLM 模型。
- Z.ai 订阅方案——GLM 模型在我的环境里工作得很稳;即使是 Lite 套餐,额度对日常编码会话也绰绰有余。