
Этот текст является переводом статьи: RAG From Scratch
Содержание
Я работаю инженером по машинному обучению и часто пользуюсь Claude или ChatGPT, чтобы писать код. Обычно это помогает, но иногда модель начинает повторяться или «галлюцинировать» — особенно при сложных или длительных задачах. Такое бывает из-за ограниченного контекстного окна модели или из-за самого характера запроса. В этих случаях я обычно добавляю к запросу псевдокод, чтобы направить модель — и это чаще всего срабатывает.
Контекстное окно — это максимальное количество текста (в токенах), которое модель способна обработать за один раз. Если этот лимит превышен, возникают проблемы: теряется информация, модель путается в деталях, особенно при работе с длинными задачами.
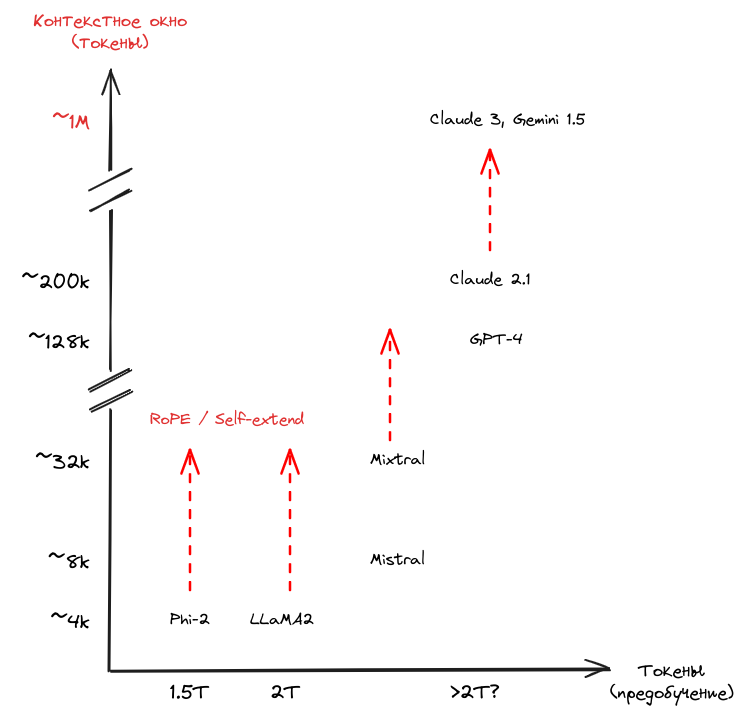
Иногда я замечаю, что модель начинает «забывать» переданную информацию. Тогда я использую простой приём: делю данные на части и подаю их поэтапно, чтобы не выйти за пределы контекста. Это помогает сохранить важные детали на всём протяжении диалога. По сути, именно эта идея лежит в основе Retrieval-Augmented Generation (RAG) — правда, с некоторыми дополнениями, о которых расскажу дальше.
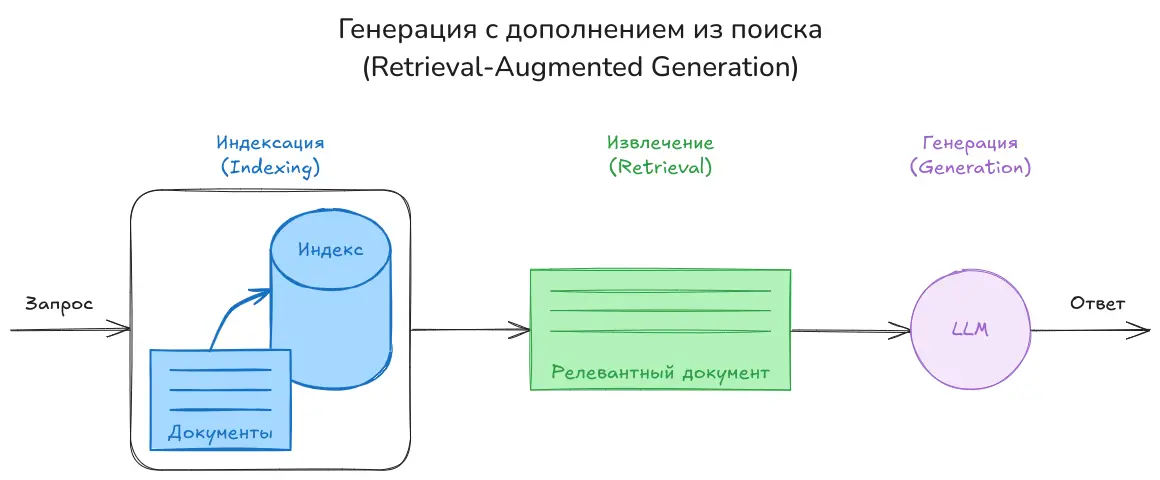
Индексация

- Документы: Всё начинается с набора источников информации — книг, статей или любых других текстов.
- Разбиение на фрагменты: На этом этапе мы делим большие документы на небольшие и удобные для обработки части. Это упрощает дальнейшую работу и делает поиск нужной информации более эффективным.
- Эмбеддинг: Каждый фрагмент текста преобразуется в числовое представление, отражающее его смысл. Это позволяет системе «понимать» содержимое и сравнивать его с другими фрагментами.
- Индекс: Наконец, все эмбеддинги сохраняются в специальной структуре данных, которая обеспечивает быстрый и точный поиск.
Разбиение на фрагменты
Кажется, все этапы понятны, кроме одного — как именно разбивать документы?
Существует множество подходов. Некоторые из них — статические, например, разбиение на фиксированные длины, когда текст делится на части с заранее заданным количеством токенов или символов. Другие подходы — семантические, они учитывают структуру и смысл текста при разбиении.
Для более подробного объяснения смотри статью: Пять уровней стратегий разбиения в RAG
Извлечение
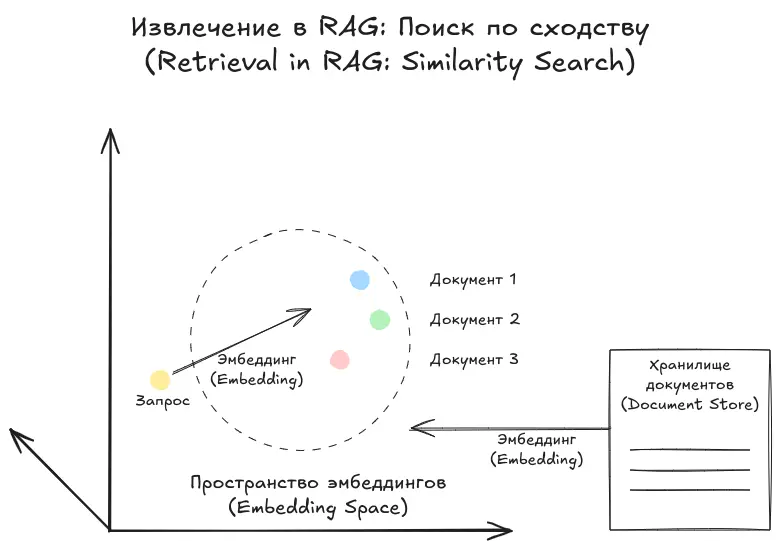
После того как документ был разбит на фрагменты, эмбеддирован и проиндексирован, мы не будем передавать все фрагменты в LLM вместе с запросом. Вместо этого выберем top-k — то есть несколько наиболее релевантных фрагментов, соответствующих вопросу пользователя.
Проще говоря, мы преобразуем сам запрос в эмбеддинг и сравниваем его с эмбеддингами фрагментов, чтобы найти те, которые наиболее близки по смыслу.
Генерация
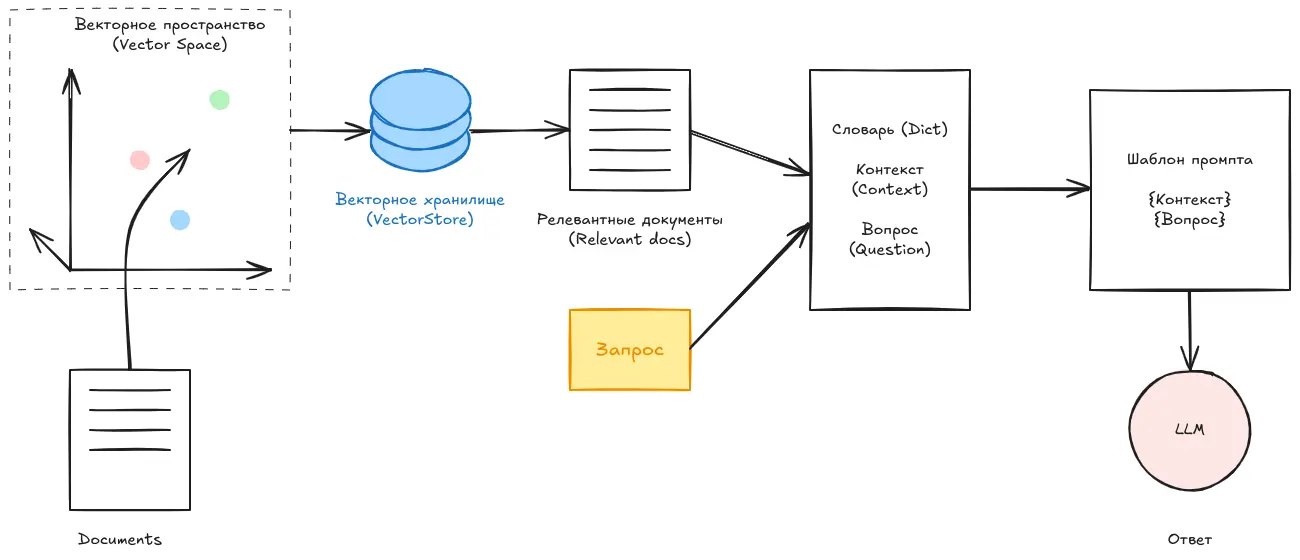
Это почти финальный этап в нашем RAG-конвейере. Теперь мы берём запрос вместе с наиболее релевантными документами и передаём их в качестве подсказки (prompt) языковой модели. Модель в ответ генерирует финальный ответ.
Это была самая базовая версия пайплайна RAG. Но стоит учесть важный момент, отражённый на изображении из твита: RAG используется для ответа на запросы к приватным данным, если сам запрос сформулирован достаточно чётко. То есть, он может быть выражен иначе, чем формулировки в самих документах. Проблема в том, что модель может попросту не понять, что именно вы хотите — и в таком случае запрос нужно предварительно переформулировать.
Преобразование запроса
![]()
Множественный запрос (Multi-Query Prompt)
Мы начинаем с исходного вопроса и переформулируем его в несколько различных вариантов. Затем подбираем релевантные фрагменты информации для каждого запроса. После этого можно использовать различные методы, чтобы объединить полученные запросы и их результаты, а затем — вместе с оригинальным вопросом — передать всё это в модель.
RAG-fusion
Метод RAG-fusion использует технику под названием Reciprocal Rank Fusion (RRF) — объединение результатов по взаимному ранжированию. Понимание RRF особенно важно, так как позже мы ещё вернёмся к нему, когда будем говорить о повторном ранжировании (Re-ranking).
Когда мы применяем стратегию множественных запросов, мы генерируем несколько формулировок и собираем наиболее релевантные фрагменты для каждой из них. Затем мы объединяем все результаты и удаляем дубликаты, чтобы в итоге остались только уникальные элементы.
Теперь представим ситуацию: два запроса возвращают разные фрагменты с одной и той же оценкой — например, 0.55. Возникает вопрос: как определить порядок этих фрагментов при объединении? Именно здесь RRF и становится полезным.
RRF помогает упорядочить фрагменты на основе их релевантности для каждого отдельного запроса. Это позволяет понять, какие из них должны получить приоритет в финальной выборке. Используя RRF, мы можем эффективно объединить результаты и при этом сфокусироваться на действительно значимых частях информации, что приводит к более точному и полезному ответу.
Если вы хотите разобраться в формуле и посмотреть примеры, рекомендуем ознакомиться со следующими статьями:
- RAG Fusion Revolution — A Paradigm Shift in Generative AI
- Reciprocal Rank Fusion (RRF) explained in 4 mins — How to score results form multiple retrieval methods in RAG
Декомпозиция
Декомпозиция запроса — это метод, при котором сложный запрос разбивается на более мелкие, простые и легко решаемые подзадачи. После этого ответы на них объединяются — либо рекурсивно, либо путём поочерёдного решения каждой части.

Рекурсивный ответ
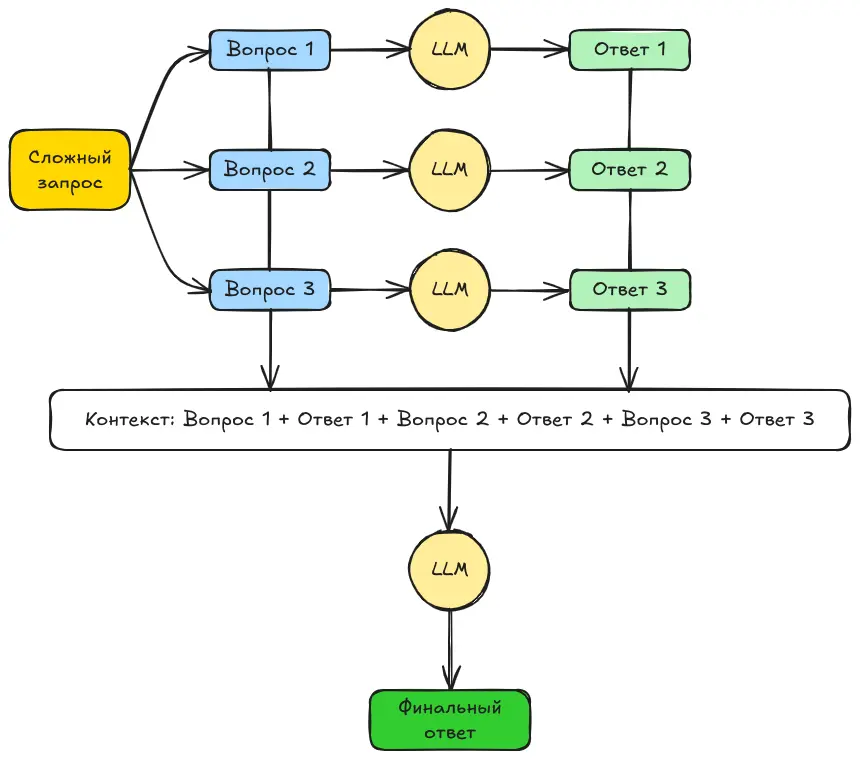
Этот метод заключается в том, чтобы разбить сложный запрос на цепочку более простых, небольших вопросов. Когда большая языковая модель (LLM) отвечает на первый из них, мы используем сам вопрос и его ответ как контекст для следующего.
Затем процесс повторяется: второй вопрос задаётся с учётом предыдущего ответа, потом третий — и так далее, пока не будут получены ответы на все подзапросы. (В некоторых случаях на этом этапе можно остановиться.)
В других случаях — все подзапросы и их ответы объединяются в один общий контекст, чтобы вернуться к исходному главному вопросу и ответить уже на него. Если мы делаем этот финальный шаг, то стратегия называется Answer Individually — «отвечать по отдельности».
Маршрутизация (Routing)
При создании масштабного RAG-приложения часто невозможно ограничиться одной фиксированной задачей или работой только с одним загруженным файлом. Например, если у вас есть ученик старших классов, готовящийся к экзаменам, вы можете создать RAG-приложение, которое помогает ему по всем предметам, а не только по одному. Однако в таком случае приложению потребуется маршрутизатор — компонент, который определяет, к какому предмету относится каждый запрос.
Например, если ученик задаёт вопрос по физике, маршрутизатор должен направить RAG к учебникам по физике, которые он загрузил, игнорируя при этом материалы по другим предметам. То есть на основе запроса пользователя приложение выбирает наиболее подходящий маршрут или цепочку (chain), чтобы получить лучший результат.
Теперь рассмотрим методы, которые можно использовать для маршрутизации:
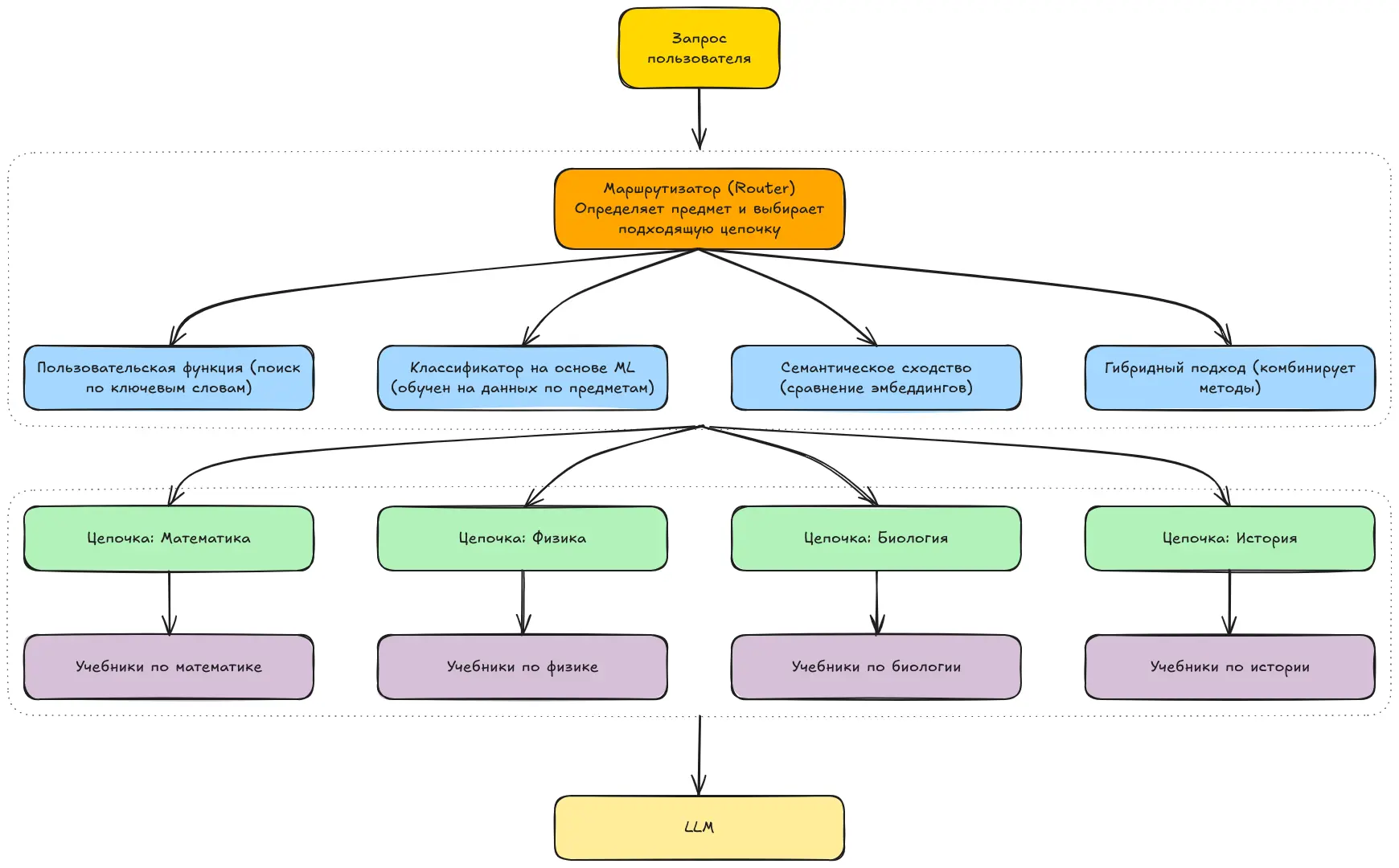
Использование пользовательской функции (Custom Function):
Можно просто создать отдельные цепочки для каждого предмета. Например, если речь идёт о математике, вы можете разработать цепочку, в которой модель будет «играть роль» учителя математики и отвечать на основе знаний по этому предмету. Аналогично — цепочка для физики, и так далее.
Простая функция будет проверять запрос на наличие ключевых слов (например, “математика”) и выбирать соответствующую цепочку.
Классификатор на основе машинного обучения (Machine Learning Classifier):
Если у вас много запросов по разным предметам — физика, математика и т.д. — и вы хотите, чтобы система автоматически определяла, о каком предмете идёт речь, вы можете обучить классификатор. Он будет относить запрос к нужной категории, и после этого система направит его к соответствующим учебникам или цепочке, связанной с этим предметом.
Семантическое сходство (Semantic Similarity):
Можно использовать более продвинутые методы, чем простое сопоставление по ключевым словам. Например, вы можете создать эмбеддинг (числовое представление) для каждой цепочки. Когда поступает новый запрос, его эмбеддинг сравнивается с эмбеддингами всех цепочек, и выбирается та, которая наиболее близка по смыслу.
Гибридный подход (Hybrid Approach):
Как следует из названия, можно комбинировать несколько вышеперечисленных методов, чтобы добиться более точной и надёжной маршрутизации.
Почему маршрутизация важна?
Хорошая маршрутизация позволяет гарантировать, что контекст, переданный в LLM, действительно соответствует заданному вопросу. Это помогает избежать ситуации, когда модель использует нерелевантную информацию из другой области.
Кроме того, эффективная маршрутизация улучшает работу индексации: поиск происходит по нужным фрагментам, экономится время и повышается точность результатов.
Построение запроса (Query Construction)
Когда мы формируем запрос, большинство файлов в используемой нами базе данных, скорее всего, содержат метаданные. А что это такое? Проще говоря, метаданные — это данные о данных.
Например, если у нас есть видеофайл, то основными данными будет само содержимое видео. А метаданные — это, например, его источник, дата создания, продолжительность и другие характеристики.
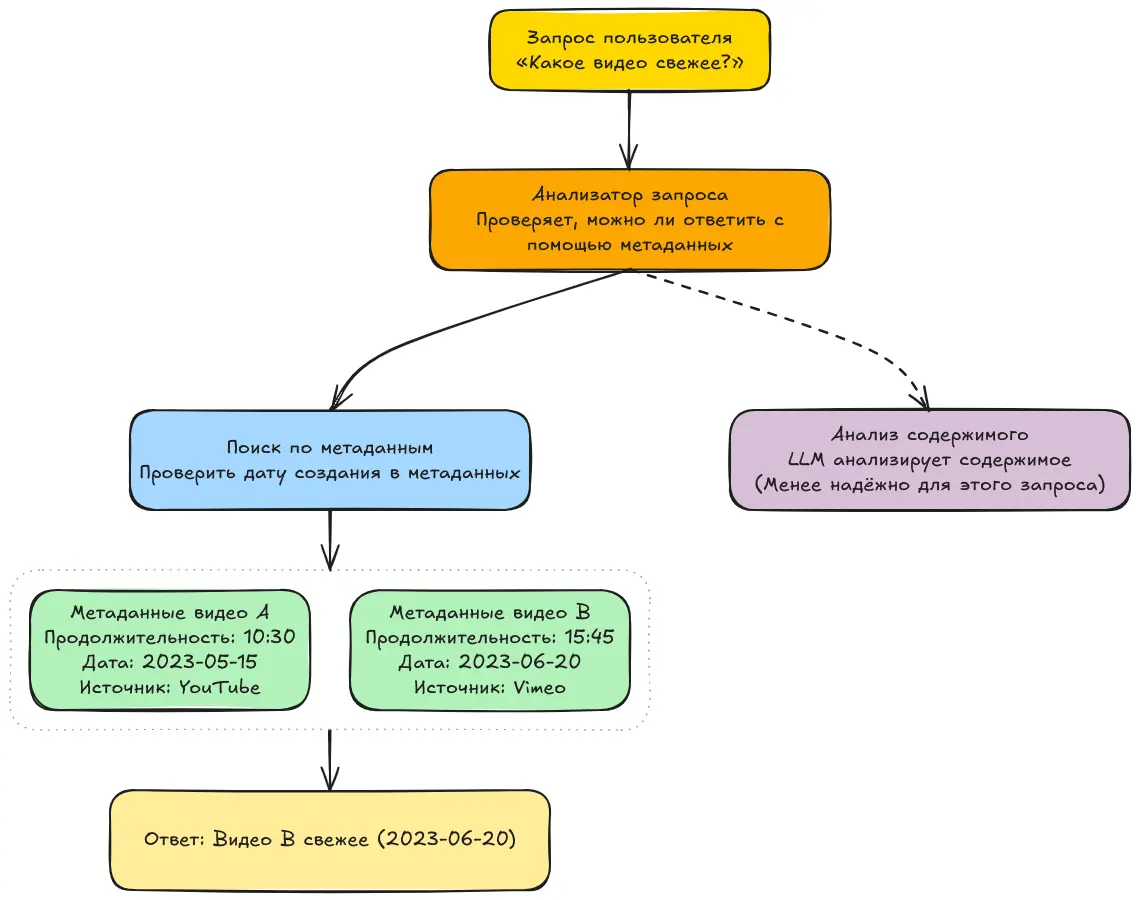
Теперь представим, что у нас есть вопрос:
Какое видео длиннее — A или B?
Первое, что может сделать модель — это посмотреть на количество слов в транскрипции первого видео и сравнить его с количеством слов во втором. Кажется логичным: где больше слов — то и длиннее. Так ведь?
Не совсем. Одно видео может содержать больше тишины, чем другое. И даже если в нём меньше слов, оно всё равно может быть длиннее. Но даже если большее количество слов действительно означает большую длительность — какой способ получить ответ будет быстрее? Проанализировать всё содержимое видео? Или просто взять продолжительность из метаданных и сравнить?
А как насчёт использования метаданных для улучшения разбиения на фрагменты (chunking)? Иногда на пользовательский запрос можно ответить напрямую, используя только метаданные — без необходимости в анализе основного содержимого. И это позволяет получить ответ проще, быстрее и надёжнее.
Ресурсы:
- Retrieval-Augmented Generation (RAG) from basics to advanced
- Advanced RAG Techniques: Unlocking the Next Level
Этот текст является переводом статьи: RAG From Scratch




