
Аннотация
Большие языковые модели (LLM) уже показали, что могут серьёзно изменить подход к обработке текста в самых разных сферах — и финансы не стали исключением. Один из главных вызовов при создании финансовых LLM (FinLLM) — это доступ к качественным финансовым данным. Проприетарные модели вроде BloombergGPT выигрывают за счёт уникальных баз данных, но такой закрытый подход создаёт потребность в открытой альтернативе, чтобы каждый мог использовать масштабные финансовые данные из интернета.
В этой работе мы представляем FinGPT — открытую большую языковую модель для финансовой области. В отличие от закрытых решений, FinGPT делает ставку на доступность данных и прозрачность: мы даём исследователям и разработчикам всё необходимое, чтобы создавать свои FinLLM. Мы отдельно отмечаем важность автоматической обработки данных и простой технологии дообучения модели с минимальными затратами. Также мы показываем, как можно использовать FinGPT, например, для робо-советников, алгоритмической торговли или быстрой low-code-разработки. Благодаря совместной работе сообщества AI4Finance, мы хотим ускорить развитие новых идей, сделать финансовые LLM доступнее и открыть больше возможностей для открытых финансов.
Вот два репозитория, где можно посмотреть код:
1. Введение
Постоянное развитие и расширение возможностей искусственного интеллекта создали плодородную почву для стремительного роста больших языковых моделей, что привело к настоящему сдвигу в обработке естественного языка в самых разных сферах. Этот масштабный переход вызвал большой интерес к применению таких моделей в финансовой области. Однако очевидно, что ключевым фактором для создания эффективной и доступной финансовой языковой модели с открытым исходным кодом является получение качественных, актуальных и релевантных данных.
Применение языковых моделей в финансах связано с рядом серьёзных трудностей — от сложности получения данных и разнообразия форматов и типов до проблем с качеством и необходимостью постоянно обновлять информацию. Особенно сложно работать с историческими или узкоспециализированными финансовыми данными, так как они могут быть представлены в виде веб-страниц, API, PDF-документов или изображений.
В мире закрытых решений модели вроде BloombergGPT использовали эксклюзивный доступ к специализированным данным для обучения языковых моделей, заточенных под финансы. Однако ограниченность доступа и непрозрачность таких моделей лишь усилили спрос на открытую и инклюзивную альтернативу. В ответ на этот запрос наблюдается устойчивая тенденция к демократизации финансовых данных интернет-масштаба в рамках open-source-сообщества.
В этой статье мы рассматриваем вышеупомянутые проблемы, связанные с финансовыми данными, и представляем FinGPT — полноценный open-source фреймворк для создания больших языковых моделей в финансовой сфере (FinLLM). FinGPT опирается на подход, ориентированный на данные, и подчёркивает важность этапов сбора, очистки и предобработки данных при разработке открытых FinLLM. Продвигая идею доступности данных, FinGPT стремится ускорить исследования, сотрудничество и инновации в области финансов, открывая путь к практике открытых финансов.
Наш вклад можно резюмировать так:
- Демократизация: FinGPT — это open-source фреймворк, цель которого — демократизировать доступ к финансовым данным и FinLLM, раскрывая новые возможности для открытых финансов.
- Ориентация на данные: Понимая важность качественной подготовки данных, FinGPT реализует подход, в центре которого — работа с данными, включая тщательную очистку и предобработку, что позволяет эффективно обрабатывать разнообразные форматы и обеспечивать высокое качество информации.
- Фреймворк полного цикла: FinGPT включает в себя полноценную архитектуру для FinLLM, состоящую из четырёх уровней:
- Уровень источников данных: обеспечивает широкий охват рынка и учитывает временную чувствительность финансовой информации, используя данные в реальном времени.
- Уровень обработки данных: оптимизирован для потоковой обработки текстов, учитывает высокую волатильность и низкий сигнал в финансовых данных.
- Уровень LLM: использует различные методы дообучения, позволяя адаптироваться к быстро меняющейся финансовой информации и сохранять актуальность модели.
- Уровень приложений: демонстрирует реальные кейсы и примеры, показывая, как FinGPT может применяться в финансовой сфере.
Наша цель — сделать FinGPT катализатором инноваций в финансах. Это не просто техническое решение, но и основа для open-source экосистемы FinLLM, поддерживающей обработку в реальном времени и дообучения под конкретные задачи. Развивая сообщество AI4Finance, мы хотим переосмыслить подход к созданию и применению финансовых языковых моделей.
2. Связанные работы
2.1. Большие языковые модели и ChatGPT
Большие языковые модели (LLMs) стали технологическим прорывом в области обработки естественного языка. Примеры — GPT-3 и GPT-4. Они основаны на архитектуре трансформеров и демонстрируют впечатляющие результаты в различных генеративных задачах.
ChatGPT — одна из моделей семейства GPT, разработанная компанией OpenAI. Она предназначена для генерации текста, близкого к человеческому, в ответ на пользовательские запросы. ChatGPT оказался полезен в самых разных сценариях: от написания электронных писем и программного кода до создания текстов самого разного содержания.
2.2. LLM в финансах
LLM находят применение во множестве задач в финансовой сфере — от предиктивного моделирования до генерации аналитических текстов на основе "сырых" финансовых данных. Особенно активно исследуются применения этих моделей для анализа финансовых текстов — новостей, стенограмм отчётных звонков компаний, постов в соцсетях и пр.
Первой крупной FinLLM можно считать BloombergGPT, обученную на комбинированном корпусе финансовых и общих текстов. Несмотря на высокую производительность, модель остаётся закрытой и недоступной, а стоимость её обучения делает актуальной задачу дообучения LLM к финансовой сфере при минимальных затратах.
Наш проект FinGPT отвечает на эти вызовы: это open-source финансовая LLM, использующая обучение с подкреплением с участием человека (RLHF), чтобы адаптироваться под предпочтения конкретных пользователей. Это делает возможным создание персонализированных финансовых ассистентов. Мы стремимся объединить сильные стороны универсальных моделей, таких как ChatGPT, с финансовой специализацией, раскрывая потенциал LLM в этой области.
2.3. Зачем нужны открытые FinLLM?
Фонд AI4Finance — некоммерческая организация с открытым исходным кодом, объединяющая ИИ и финансовые технологии, включая разработку финансовых LLM (FinLLMs). За плечами фонда уже есть успешные проекты, такие как FinRL и FinRL-Meta, ставшие основой для инновационной экосистемы FinTech-инструментов. Сейчас фонд активно развивает направление FinLLM, ускоряя внедрение ИИ в финансовую индустрию.
Преимущества open-source подхода к FinLLM:
- Расширение доступа и равных возможностей
Открытые модели позволяют всем использовать передовые технологии, поддерживая идею демократизации FinLLM. - Прозрачность и доверие
Открытые модели предоставляют полный доступ к исходному коду, повышая доверие и делая работу моделей понятной и проверяемой. - Ускорение исследований и инноваций
Open-source способствует более быстрому прогрессу: исследователи могут использовать готовые наработки и сосредоточиться на новых идеях. - Развитие образования
Открытые FinLLM — отличные учебные инструменты: студенты и исследователи могут изучать внутренние механизмы таких моделей, работая с ними напрямую. - Развитие сообщества и сотрудничества
Открытые проекты объединяют международное сообщество разработчиков и исследователей, что помогает модели оставаться актуальной, надёжной и устойчивой в долгосрочной перспективе.
3. Подход, ориентированный на данные, для финансовых LLM (FinLLM)
Для создания эффективных финансовых языковых моделей важна не только архитектура модели, но и качество данных, на которых она обучается. Наш подход делает акцент на сборе, подготовке и обработке качественной информации.
3.1. Финансовые данные и их особенности
Финансовые данные поступают из множества источников и обладают своими уникальными характеристиками. Мы подробнее рассматриваем ключевые типы источников: финансовые новости, отчётность компаний, социальные сети и тренды/аналитику.
Финансовые новости содержат важную информацию о мировой экономике, отраслях и отдельных компаниях. Их отличают:
- Актуальность: отражают последние события в экономике и на рынках.
- Динамичность: быстро меняются под влиянием рыночных и макроэкономических факторов.
- Влияние: могут заметно повлиять на поведение инвесторов и вызвать движения на рынке.
Финансовая отчётность и официальные заявления компаний — документы, подаваемые в регулирующие органы и раскрывающие финансовое состояние компаний. Их особенности:
- Детализированность: содержат информацию об активах, обязательствах, доходах и прибыли.
- Надёжность: данные проверяются и утверждаются регуляторами.
- Периодичность: публикуются регулярно, чаще всего раз в квартал или год.
- Значимость: могут существенно влиять на котировки и инвестиционные решения.
Социальные сети отражают массовое восприятие отдельных акций, секторов или рынка в целом. Характерные черты:
- Разнообразие: мнения и сообщения сильно варьируются по стилю, содержанию и достоверности.
- Настроения в реальном времени: позволяют оперативно отслеживать тренды и изменение общественного восприятия.
- Высокая волатильность: мнение публики быстро меняется под влиянием новостей и событий.
Тренды и аналитические платформы (например: Seeking Alpha, Google Trends, блоги, форумы) дают представление о рыночной динамике и стратегии инвесторов. Их отличают:
- Аналитический взгляд: содержат прогнозы и рекомендации от экспертов.
- Рыночные настроения: позволяют оценить общую атмосферу вокруг активов или секторов.
- Широкий охват: покрывают большое количество инструментов и сегментов рынка.
Каждый из этих источников предоставляет уникальный взгляд на происходящее в мире финансов. Интеграция таких разнообразных данных в модели вроде FinGPT позволяет глубже понимать рынок и принимать более обоснованные решения.
3.2. Основные сложности при работе с финансовыми данными
Мы выделяем три ключевых вызова:
- Высокая временная чувствительность
Финансовые данные быстро устаревают. Новость, способная повлиять на рынок, даёт очень короткое окно для получения прибыли. - Быстрая динамика
Финансовая среда постоянно меняется. Огромный поток новостей и сообщений делает частое переобучение моделей дорогим и неэффективным. - Низкое соотношение сигнал/шум (SNR)
Полезная информация часто теряется в огромном объёме вторичных или нерелевантных данных. Чтобы извлечь суть, нужны продвинутые методы фильтрации и анализа.
Решение этих задач критически важно для эффективной работы с финансовыми данными и раскрытия потенциала FinLLM. Мы предлагаем open-source фреймворк FinGPT как инструмент для этого.
4. Обзор FinGPT: открытый фреймворк для финансовых LLM
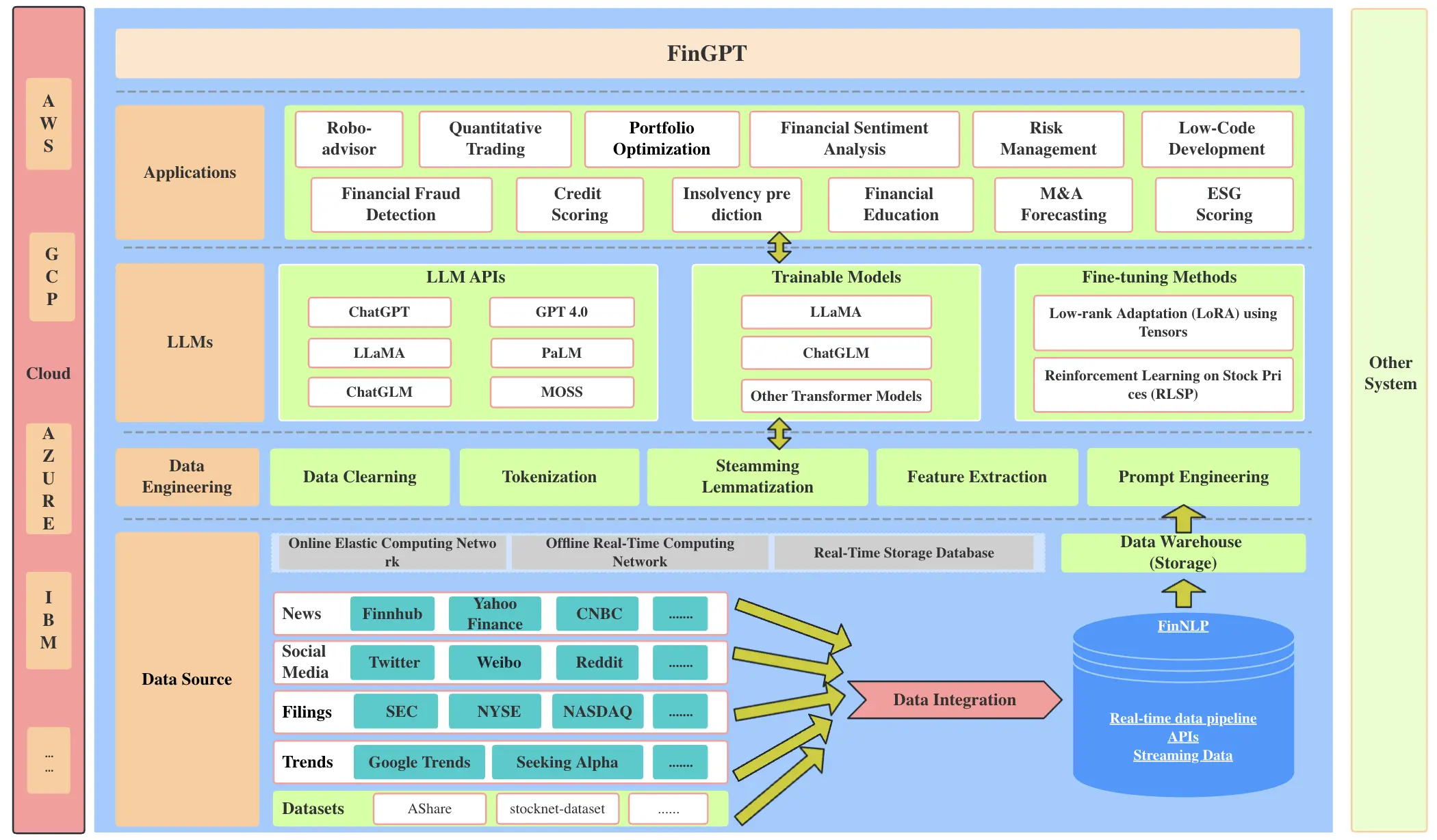
Архитектура FinGPT
FinGPT — это open-source фреймворк нового поколения, созданный специально для применения больших языковых моделей (LLM) в финансах. Как показано на схеме, он включает четыре ключевых компонента:
- Источники данных (Data Source)
- Обработка данных (Data Engineering)
- Языковые модели (LLMs)
- Приложения (Applications)
Каждый из этих слоёв играет важную роль, помогая FinGPT адаптироваться к постоянно меняющейся финансовой информации и рыночным условиям.
- Слой источников данных (Data Source layer): Первый слой отвечает за сбор большого объёма финансовых данных из разных онлайн-источников. Это новостные сайты, социальные сети, корпоративная отчётность, рыночные тренды и многое другое. Цель — охватить максимум событий и изменений, с учётом высокой временной чувствительности таких данных.
- Слой обработки данных (Data Engineering layer): На этом этапе происходит потоковая обработка текстовой информации в реальном времени. Используются современные методы NLP, чтобы отфильтровать шум и выделить важную информацию, несмотря на высокую динамичность и низкое соотношение сигнал/шум в финансовых данных.
- Слой языковых модели (LLMs layer): Центральный компонент системы, отвечающий за понимание и генерацию текста. Используются лёгкие методы дообучения (например, LoRA), чтобы оперативно обновлять модель и сохранять её актуальность без переобучения с нуля.
- Слой приложений (Application layer): Финальный слой, где показываются реальные сценарии использования FinGPT: робо-советники, торговые сигналы, инструменты low-code-разработки. Демо-примеры помогают пользователям быстро начать работу и понять потенциал модели.
4.1 Источники данных (Data Source)
FinGPT собирает данные из широкого спектра источников:
- Финансовые новости: такие сайты как Reuters, CNBC, Yahoo Finance публикуют информацию о рынках, отчётности компаний и макроэкономике.
- Социальные сети: Twitter, Facebook, Reddit, Weibo — отражают общественные настроения, тренды и мгновенные реакции на новости.
- Отчётность компаний: сайты регуляторов (например, SEC) и бирж (NYSE, NASDAQ, Шанхайская биржа) предоставляют квартальные и годовые отчёты, информацию о сделках инсайдеров, движении цен и объёмах торгов.
- Финансовые тренды и блоги: ресурсы вроде Seeking Alpha, Google Trends и тематические форумы содержат прогнозы, мнения аналитиков и обсуждения рыночной динамики.
- Академические датасеты: подготовленные для исследований наборы данных с верифицированной информацией.
Для сбора данных FinGPT использует API, web scraping и, где возможно, прямое подключение к базам данных. Все источники используются в соответствии с их условиями обслуживания — этично и легально.
API для данных: В FinGPT API применяются как для начального сбора данных, так и для их регулярного обновления в реальном времени. Реализована система контроля ошибок и соблюдения лимитов запросов.
4.2 Обработка данных (Data Engineering) в реальном времени для финансового NLP
Финансовые рынки работают в режиме реального времени и крайне чувствительны к новостям и настроениям. Стоимость активов может резко меняться в ответ на новую информацию, и даже небольшая задержка в её обработке может привести к упущенным возможностям или повышенным рискам. Поэтому обработка в реальном времени — ключевой компонент финансового NLP.
Главная сложность при построении такого пайплайна — эффективно управлять и обрабатывать непрерывный поток данных. Первый шаг — настроить систему, которая может принимать данные в реальном времени. Источником могут быть, например, API подключённых информационных платформ.
Далее приведены ключевые этапы проектирования такого NLP-пайплайна для приёма и обработки данных в режиме реального времени:
- Очистка данных: удаление мусора, нормализация текста, устранение пропусков и ошибок.
- Токенизация: разбиение текста на слова и фразы.
- Удаление стоп-слов и стемминг: исключение частых слов, сведение слов к их корню.
- Извлечение признаков и анализ тональности: преобразование текста в числовой вид (TF-IDF, Word2Vec и пр.) и определение тональности (позитивная, нейтральная, негативная).
- Промпт-инжиниринг: создание запросов для LLM, которые направляют модель к нужному ответу.
- Реакция на результат: модель может запускать сигналы, уведомления или отдавать результат в другие системы.
- Непрерывное обучение: модели могут дообучаться в режиме онлайн или периодически на новых данных.
- Мониторинг: отслеживание стабильности пайплайна и быстрый отклик на сбои.
4.3 Большие языковые модели (LLMs)
Подготовленные данные подаются в LLM для анализа и генерации финансово значимых выводов.
Компоненты:
- LLM API — подключение к существующим языковым моделям.
- Обучаемые модели (Trainable) — FinGPT позволяет дообучать модели на приватных финансовых данных.
- Методы дообучения (Fine-tuning) — позволяют настраивать модель под конкретные задачи, например — персонализированных советников.
Почему лучше дообучать LLM, а не обучать с нуля?
Использование уже готовых больших языковых моделей (LLM) и их последующая адаптация под финансовые задачи — это эффективная и экономически оправданная альтернатива дорогому и длительному обучению моделей с нуля.
Например, BloombergGPT, несмотря на впечатляющие результаты в финансовом контексте, требует колоссальных вычислительных ресурсов. Её обучение заняло примерно 1,3 миллиона GPU-часов, что при цене \(2.3 за час в облаке AWS эквивалентно **почти\)3 миллионам за одно обучение**.
В отличие от этого, FinGPT предлагает куда более доступное решение — благодаря лёгкой адаптации лучших моделей с открытым исходным кодом. Стоимость такой адаптации снижается на порядок и составляет менее $300 за обучение.
Этот подход обеспечивает быстрое обновление модели и гибкость, что критически важно в условиях постоянно меняющегося финансового ландшафта. Кроме того, благодаря открытому коду FinGPT не только повышает прозрачность, но и позволяет настраивать модель под конкретные потребности пользователя — что особенно актуально на фоне растущего спроса на персонализированные финансовые сервисы.
В конечном счёте, доступный и адаптивный фреймворк FinGPT делает возможной демократизацию финансовых языковых моделей и стимулирует развитие пользовательских решений в финансовой сфере.
4.3.1 Дообучения через Low-Rank Adaptation (LoRA)
В FinGPT мы дообучаем предобученную языковую модель (LLM) с использованием нового финансового датасета. Известно, что высококачественные размеченные данные — ключевой фактор успеха для многих LLM, включая ChatGPT. Однако их получение требует немалых затрат времени и ресурсов и обычно требует участия специалистов с финансовой экспертизой.
Если наша цель — использовать LLM для анализа финансовых текстов и поддержки количественной торговли, логично использовать встроенный механизм автоматической разметки, который уже присутствует на рынке. Мы предлагаем в качестве метки использовать относительное изменение цены акции после публикации каждой новости. Установив пороговые значения, мы делим метки на три категории: положительная, отрицательная и нейтральная — в зависимости от предполагаемого эмоционального окраса новости.
На следующем этапе — при составлении промптов — мы явно просим модель выбрать один из трёх вариантов. Такой приём помогает эффективно использовать знания, уже заложенные в предобученной модели. Благодаря применению Low-Rank Adaptation (LoRA), мы значительно сокращаем количество обучаемых параметров — с 6,17 миллиарда до всего лишь 3,67 миллиона.
4.3.2 Дообучение с подкреплением на основе фондового рынка (RLSP)
Аналогично, вместо обучения с подкреплением на основе обратной связи от человека (RLHF), как в ChatGPT, мы используем метод обучения с подкреплением по изменению цен акций — RLSP (Reinforcement Learning on Stock Prices). Это обусловлено тем, что цены акций представляют собой измеримую и объективную метрику, отражающую реакцию рынка на новости и события. Таким образом, рынок сам становится источником обратной связи в реальном времени для обучения модели.
Метод RL позволяет модели учиться через взаимодействие с внешней средой и получение отклика. В случае RLSP средой выступает фондовый рынок, а отклик — изменения цен акций. Такой подход позволяет FinGPT постепенно улучшать интерпретацию финансовых текстов и точность предсказаний.
Связывая эмоциональную окраску новостного сообщения с последующей динамикой соответствующей акции, RLSP даёт модели возможность понять, как именно рынок реагирует на те или иные события, и корректировать свои прогнозы. Это позволяет ей всё точнее моделировать рыночную логику.
Таким образом, интеграция RLSP в процесс тонкой настройки делает модель более чувствительной к реальной рыночной динамике и повышает её предсказательную точность. Используя реальные рыночные движения в качестве отклика, мы буквально «даём модели поучиться у самого рынка».
4.4 Приложения (Applications)
FinGPT может быть полезен во множестве задач в сфере финансовых услуг, помогая как профессионалам, так и частным инвесторам принимать более взвешенные и информированные решения. Возможные области применения включают:
- Робо-советник — предоставление персонализированных финансовых рекомендаций, снижая необходимость в частых личных консультациях.
- Алгоритмическая торговля — генерация торговых сигналов для поддержки стратегий автоматизированной торговли.
- Оптимизация портфеля — формирование инвестиционного портфеля с учётом экономических индикаторов и профиля инвестора.
- Анализ финансовых настроений — оценка тональности на разных платформах (новости, соцсети и т.д.) для поиска инвестиционных инсайтов.
- Управление рисками — построение стратегий на основе анализа потенциальных рисков.
- Обнаружение мошенничества — выявление аномалий и подозрительных транзакций для повышения безопасности.
- Кредитный скоринг — прогнозирование кредитоспособности на основе финансовых данных.
- Прогноз банкротства — выявление компаний с высоким риском неплатёжеспособности или банкротства.
- Прогнозирование M&A-сделок — анализ финансовой отчётности и рыночной информации для оценки вероятности сделок по слияниям и поглощениям.
- Оценка ESG — анализ экологических, социальных и управленческих факторов на основе открытых источников.
- Low-code разработка — упрощённое создание финансовых решений через визуальные интерфейсы, без необходимости программирования.
- Финансовое обучение — роль ИИ-наставника, который помогает разобраться в сложных финансовых темах и повысить уровень финансовой грамотности.
Объединяя все эти направления, FinGPT формирует целостное и доступное решение для внедрения ИИ в финансы — и создаёт базу для исследований, инноваций и прикладных решений в отрасли.
5. Заключение
Интеграция больших языковых моделей (LLM) в финансовую сферу — это одновременно и серьёзный вызов, и огромная возможность. Высокая временная чувствительность данных, динамичность финансовой среды и низкое соотношение сигнал/шум требуют продуманных и эффективных решений.
FinGPT предлагает инновационный подход: использование уже существующих LLM с их последующей адаптацией под конкретные финансовые задачи. Такой подход позволяет значительно сократить затраты на обучение и ресурсы, особенно по сравнению с моделями вроде BloombergGPT. В результате мы получаем более доступное, гибкое и экономичное решение для построения финансовых языковых моделей.
Кроме того, он обеспечивает возможность регулярного обновления, что критически важно для поддержания точности и актуальности модели в быстро меняющемся и чувствительном к времени мире финансов.
6. Дальнейшая работа
FinLLMs (финансовые большие языковые модели) воплощают представление о будущем, в котором персонализированные робо-советники и финансовые ассистенты доступны каждому. Цель проекта — демократизировать доступ к качественным финансовым рекомендациям, используя возможности современных языковых моделей для анализа больших объёмов данных и превращения их в понятные, практически применимые инсайты.
Ниже представлен план дальнейшего развития FinLLM:
-
Персонализация
В основе стратегии FinLLM — идея индивидуальной настройки. С помощью таких методов, как LoRA и QLoRA, пользователи могут адаптировать модели под собственные нужды, создавая своего персонального финансового помощника или советника. Это соответствует глобальному тренду на персонализированные финсервисы: всё больше людей хотят получать рекомендации, соответствующие их уникальному риск-профилю и целям. -
Open-source и доступность
FinLLM придерживается принципов открытости и предоставляет пользователям инструменты для адаптации LLM при минимальных затратах — от \(100 до\)300. Это не только делает технологии доступными, но и способствует развитию активного сообщества разработчиков и исследователей, которые вместе расширяют границы финансового ИИ. -
Доступ к качественным финансовым данным
FinLLM предлагает не только инструменты для моделирования, но и доступ к высококачественным финансовым данным. Это помогает пользователям эффективно обучать модели и упрощает подготовку данных. Кроме того, предоставляется пайплайн подготовки с демонстрациями, что позволяет быстрее и проще начать работу с собственными данными.
Отказ от ответственности: Мы публикуем код исключительно в академических и образовательных целях по лицензии MIT. Этот материал не является финансовой рекомендацией и не призывает к торговле реальными деньгами. Всегда используйте здравый смысл и консультируйтесь с профессионалами, прежде чем принимать инвестиционные решения.
Список литературы
- FinBERT: анализ финансовых настроений с использованием предварительно обученных языковых моделей (FinBERT: Financial sentiment analysis with pre-trained language models) — Araci, 2019.
- Plato-XL: исследование крупномасштабного предобучения для генерации диалогов (Plato-XL: Exploring the large-scale pre-training of dialogue generation) — Bao и др., 2021.
- Языковые модели как few-shot ученики (Language Models are Few-Shot Learners) — Brown и др., 2020.
- Bernice: мультиязычный предварительно обученный энкодер для Twitter — DeLucia и др., 2022. Источник: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022), стр. 6191–6205.
- QLoRA: эффективная тонкая настройка квантованных LLM (QLoRA: Efficient Finetuning of Quantized LLMs) — Dettmers и др., 2023.
- BERT: предварительное обучение двунаправленных трансформеров для понимания языка (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) — Devlin и др., 2018.
- Как Twitter меняет характер обнаружения финансовых новостей — Dredze и др., 2016. Источник: Proceedings of the Second International Workshop on Data Science for Macro-Modeling, стр. 1–5.
- Насколько контекстны контекстуализированные представления слов? Сравнение геометрии эмбеддингов BERT, ELMo и GPT-2 (How Contextual are Contextualized Word Representations?) — Ethayarajh, 2019.
- LoRA: низкоранговая адаптация больших языковых моделей (LoRA: Low-Rank Adaptation of Large Language Models) — Hu и др., 2021.
- BART: восстановительное предобучение для генерации, перевода и понимания текста (BART: Denoising Sequence-to-Sequence Pre-training) — Lewis и др., 2019.
- Предобученные языковые модели для биомедицинских и клинических задач: анализ и расширение современного уровня — Lewis и др., 2020. Источник: Proceedings of the 3rd Clinical NLP Workshop, стр. 146–157.
- FinRL: фреймворк глубокого обучения с подкреплением для автоматизации торговли в количественных финансах (FinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance) — Liu и др., 2021.
- FinRL-Meta: рыночные среды и бенчмарки для обучения с подкреплением в финансах (FinRL-Meta: Market Environments and Benchmarks for Data-Driven Financial Reinforcement Learning) — Liu и др., 2022.
- Улучшение понимания языка с помощью генеративного предобучения (Improving Language Understanding by Generative Pre-Training) — Radford и др., 2018. (OpenAI blog)
- LaMDA: языковые модели для диалоговых приложений (LaMDA: Language Models for Dialog Applications) — Thoppilan и др., 2022.
- Внимание — всё, что вам нужно (Attention Is All You Need) — Vaswani и др., 2017.
- BloombergGPT: большая языковая модель для финансов (BloombergGPT: A Large Language Model for Finance) — Wu и др., 2023.
Этот текст является переводом статьи: FinGPT: Open-Source Financial Large Language Models




